Note
containers / docker 改变了软件分发的方式.
以前是分发软件编译后的二进制产物, 现在是分发整个虚拟环境.
dockerfile, image, container, docker
- docker
- 是个开源 工具, 用来 管理和创建容器
- dockerfile
- dockerfile 是个编译镜像的 instruction, 本质是一个 文本格式 的 配置文件
- 包含了一系列 instructions,告诉 Docker 如何构建镜像
- 可以理解为”制作镜像的配置说明书”
- 镜像 (Image)
- 是一个轻量级、 独立、可执行 的 软件包
- 为什么镜像是个 软件包?
- 因为 image 包含运行应用程序所需的所有内容: 代码、运行时环境、依赖项、环境变量和配置文件等
- 是静态的,类似于一个 模板
- 镜像 不能被修改, 构建之后如果要更改里面的内容, 只能重新构建
- 所以有的地方会说 image 是 仅可读的, 这个和这里说的 image 是 可执行的 这一点不冲突
- 可以类比为面向对象编程中的”类”(Class)
- 是一个轻量级、 独立、可执行 的 软件包
- 容器 (Container)
- 是镜像的运行 实例 (镜像执行起来之后就是个 container)
- 在镜像的基础上增加了一个 可写层
- 是动态的,真正运行应用程序的地方
- 可以类比为面向对象编程中的”对象”(Object)
# Dockerfile (制作说明书)
FROM node:14
WORKDIR /app
COPY . .
RUN npm install
CMD ["npm", "start"]
# Image (按照说明书制作好的软件包)
# image 里面就包含了 npm install 的内容, 也就是软件执行所需要的依赖项; 也有代码啥的
$ docker build -t my-app .
# Container (运行这个软件包)
$ docker run my-appNote
有的地方会这么说:
- 镜像是 只读 的、静态 的、不可变的;
- 容器是 动态 的、可以被 启动、停止 的
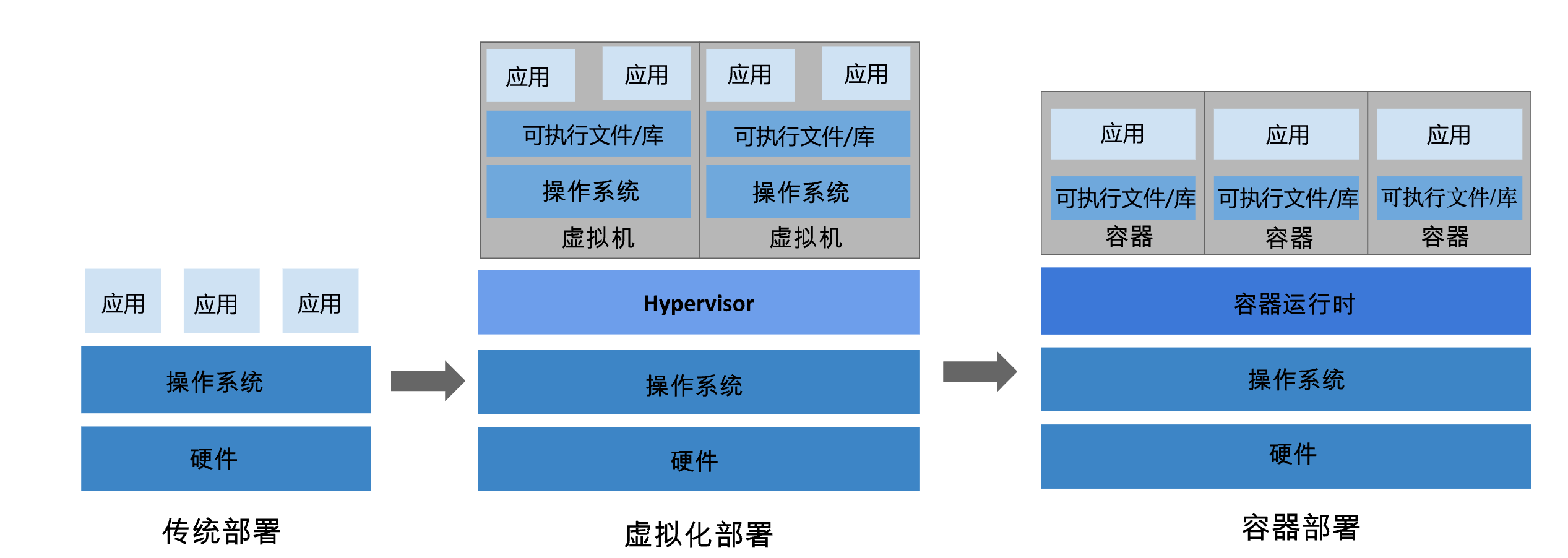
容器从 OS 层面实现 virtualization, VM 从硬件层面
containers:
- 不同的容器实际上只是 不同的、相互隔离 的进程, 在用户空间中执行
- containers on a host share the host OS’s kernel. Containers run as isolated processes in user space on the host OS.
- contains an application and its dependencies, but do not include a full OS.
Virtual Machines:
- VM 有自己完整的 OS
- VM runs its own complete OS on top of a hypervisor, which simulates hardware resources like CPU, memory, storage. → 虚拟机是在物理硬件层面上实现的 virtualization, 在物理机上创建独立的 OS → 每个 OS 都会被分配一定的硬件资源, 如 CPU、内存、网卡、磁盘 等 → 从虚拟机的视角来看, 这些硬件资源是独立的、自己独有的; 换句话说, 一台虚拟机在挖矿, 也不会影响另一台虚拟机的性能 → 从物理机的角度来看, 同一台物理机上的虚拟机在共享这些资源
credit k8s official doc
containers are processes
- 一个 container 实际上就是 a group of linux processes
Containers are essentially processes that run on the host operating system. Each container shares the host OS kernel but operates in its own user space. Container can have its own filesystem, networking and process space.
虽然是 a group of linux processes, 但是和普通的 process 还是有区别的:
- 普通的 process 直接就在 OS 上跑, 所有进程 共享内核和资源, 默认是没有什么资源限制的
- container 的 namespaces 命名空间 是隔离的, 有资源的 restriction
- 每个 container 都有自己独立的 user namespace、network namespace 等
- 同时 container 也有独立的 filesystem
filesystem 文件系统的独立性
- each container has its own root filesystem, which is separate from host OS’s filesystem.
- the filesystem includes everything needed to run the application inside the container, like libraries, binary files and configs.
network 网络的独立性
- 每个 container 都有自己的 网络接口, IP, 路由表 和 防火墙
- 需要通过特殊的机制, container 之间才能相互通信 (在此就不展开了)
process 进程的独立性
- 每个 container 都 只能够看到自己这个 container 里的进程, 看不到 host 的, 也看不到其他 container 的
container & linux
pivot_root (自己的 file system):
- 让 container 有自己的 root dir
namespaces (操作系统层面的限制):
- 让 container 有自己的 filesystem, network, users
cgroups (硬件上的限制):
- 限制 container 的 CPU、内存使用情况
seccomp_bpf (syscall 的限制):
- 有的比较危险的 syscall 会被限制, container 不能调用
container runtime
500 行手写 runtime container runtime 是啥?
- A container runtime is a piece of software that is responsible for executing containers. → runtime 是负责 创建和管理 容器 的底层组件, 本身也是一套软件 → runc github, containerd github
Note
上面 containers are processes 写到, 实际上 容器的本质就是 一组 被 namespace 和 cgroup 隔离起来的 进程;
每个进程都要一个 父进程 来启动它, 在这个 context 里, 启动 容器这组进程 的父进程, 需要对这些子进程进行 限制 + 启动 (fork);
那是谁把这些进程隔离、执行起来的呢? 谁作为这样的一个父进程呢? container runtime 就是这么个角色
- container runtime 主要功能:
- 镜像管理
- 容器管理
- 网络配置
- 存储管理
- 其他 container runtime 还有: containerd, runc, cri-o
runtime 的流程图:
runc run/start <container-id>
└── 读取 bundle 目录下的 config.json
└── 创建容器进程
├── 设置 namespaces (PID, NET, UTS, IPC, MOUNT, USER)
├── 设置 cgroups
├── 配置 root filesystem (pivot_root/chroot)
├── 配置 capabilities、rlimits
├── 配置 seccomp、安全策略
└── fork 子进程 (container process)
├── 子进程进入 namespace、mount 文件系统
├── 应用 seccomp 过滤
├── 设置 UID/GID
└── exec 进入用户指定的容器进程 (比如 /bin/sh)
└── runc 本身退出,容器进程独立运行
docker run 发生了什么
执行 docker run nginx 的时候发生了什么?
- 首先是
docker这个 CLI 工具作为客户端去请求 docker daemon - docker daemon 检查本地是否有镜像, 没有的话会去 hub 里拉
- docker daemon 设定 容器 的 容器id, filesystem, namespace, cgroup; 此时相当于是
docker create, 容器还没有真正执行起来, 没有 Pid - docker daemon 通过 docker runtime 来创建进程, 进程在独立的 namespace 里执行
同样的, Kubernetes 也 不执行容器, Kubernetes 只是 容器编排 的工具;
- 真正执行容器的是 Kubernetes 用的 container runtime
- 换句话说, docker 和 Kubernetes 是 higher level 的工具, 它们通过 container runtime 来管理容器
image
image 的本质是什么
image 的本质是个静态的 软件包, 仅可读, 可执行 的 静态文件 包含:
- OS 的 filesystem 的快照, 不包含 OS 本身
- 一些系统调用和其他依赖项
- image 用于构建容器
image 的 layers
- image 一般都有分层, 比如说下面的 dockerfile 写的就有几层
# Base layer - 基础层
FROM ubuntu:20.04
# Intermediate layer 1 - 中间层1
RUN apt-get update && apt-get install -y python3
# Intermediate layer 2 - 中间层2
RUN mkdir /app
# Intermediate layer 3 - 中间层3
COPY . /app-
在 dockerhub 上随便下载了个 nginx 的 image, 看这也有 19 个 layers
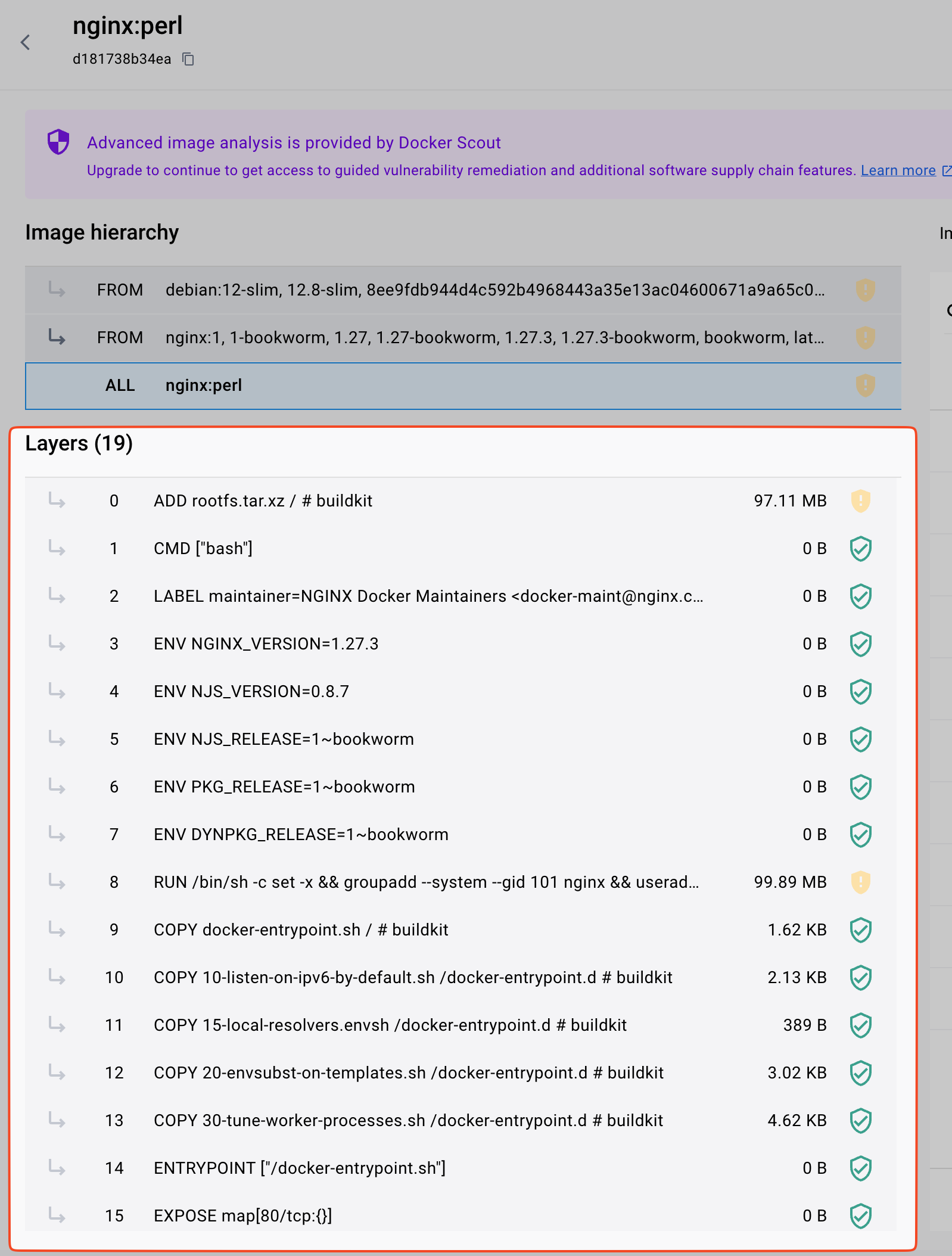
-
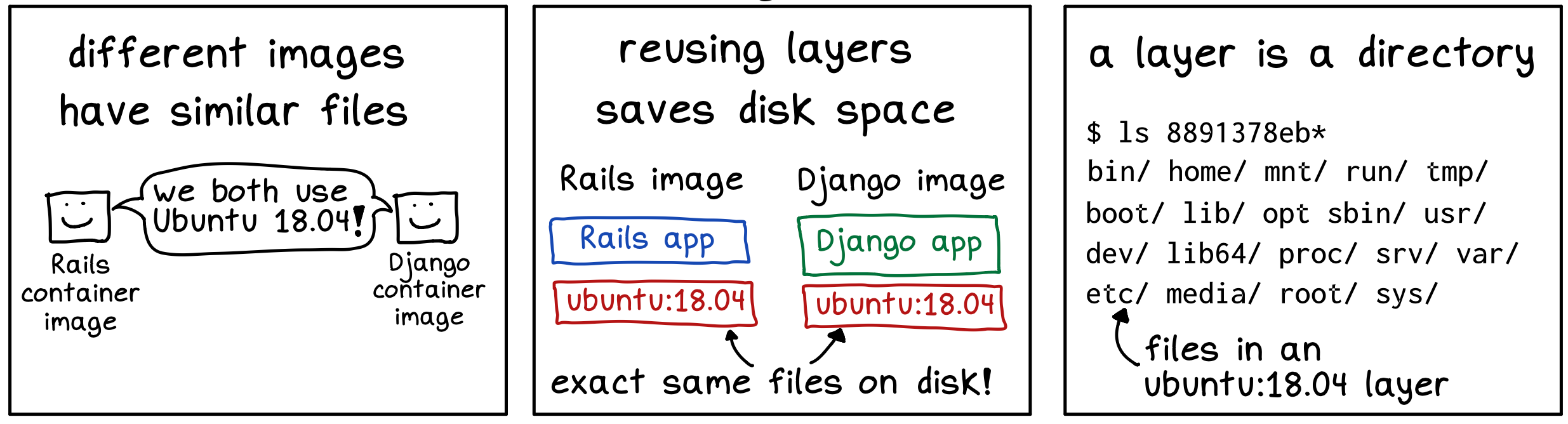
对于不同的 image, 如果他们有相同的 layer 是可以共用的;
-
如果两个 image 都是 ubuntu:20.04, 那他们就可以共用同一个 base layer
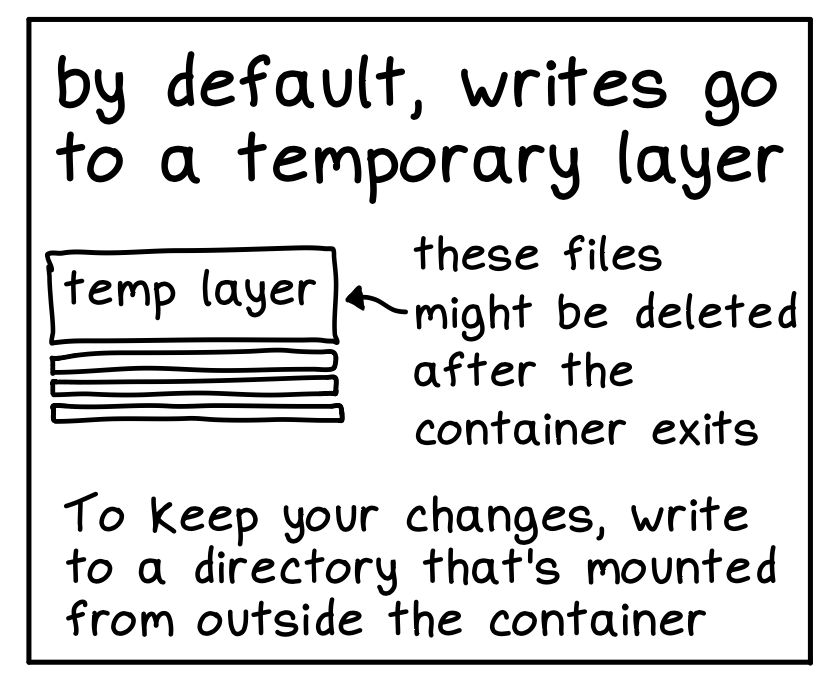
在 container 启动的时候, 还会有个 temporary 的 writable layer, 所有的 写操作 都会写到这个 layer 里
- 是个 temporary layer, 在 container 退出的时候就没了
- 对于需要 持久化 的数据, 需要写到 container 以外的 filesystem 里
Note
- 每个 layer 记录的只是 增量
- 比如说上面的 dockerfile 里, layer 3 是基于 layer 2 的, layer 3 只存了 layer 3 增量 的信息
- 每个 layer 都是 只读 的, 不会改变前面 layer 的东西
- 每个 layer 对应一个 directory
- 但是用户在容器中, 看到的是个 合并、统一 的 layer, 看不到 独立分层
- layer 是可缓存的: 当构建一个新的镜像时, Docker 会检查本地是否存在与新层相同的层; 如果存在, 则可以直接使用缓存的层, 而不需要重新构建
拉取基础镜像的时候发生了什么?
FROM ubuntu:20.04 拉取基础镜像
- 在本地看, 是否已经有了对应的景象
- 没有的话, 连接远端 docker hub (可以是私有的, 比如公司内部的 docker hub)
- 这个 base image 可能包含了很多 layer, 会分层下载; 如果某一层已经在本地存在了那就会跳过下载
- 每一层都有一个哈希值, 确保 layer 的唯一性
- 全部下载完了之后会组装
dockerfile
run & cmd
- 都是用来执行命令的 run:
RUN都会生成一个新的 layer (新的中间层)RUN在构建镜像的时候执行- 不是每个
RUN都会生成新的 layer; 如果是RUN echo "hello"这种命令, 对 filesystem 没有影响, 就不会生成新的 layer cmd: - 每个 dockerfile 里 只能有一个
CMD, 指定了多个的话, 只有最后一个会生效 CMD用于指定容器 启动 的时候默认执行的命令CMD在启动容器的时候执行
add & copy
- 这俩都会生成新的 镜像层 copy
- 简单地将 文件或目录 从 构建上下文 build context 中复制到镜像内
# 复制当前目录下的文件 file.txt 到镜像的 /app 目录
COPY file.txt /app/
# 复制当前目录下的 src 目录到镜像的 /app/src 目录
COPY src/ /app/src/add
- 有更多的功能, 可以解压, 可以从 remote 下载
# 复制当前目录下的文件 file.txt 到镜像的 /app 目录
ADD file.txt /app/
# 复制当前目录下的 my_archive.tar.gz 并解压到镜像的 /app 目录
ADD my_archive.tar.gz /app/
# 从 URL 下载文件并将其添加到镜像的 /app 目录
ADD http://example.com/file.txt /app/理解下我自己写的 dockerfile
FROM hub.byted.org/bet/tesla_py3:latest
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file into the container
COPY requirements.txt .
RUN apt-get update && \
apt-get install -y --no-install-recommends \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/
# Install the required packages
RUN pip install --upgrade pip && \
pip install --no-cache-dir Cython;
RUN pip install -r requirements.txt --no-cache-dir ;
# Copy the rest of your application's code into the container
COPY . .几个问题:
- workdir 是干啥的, 一定需要吗?
- 这个 dockerfile 是咋知道 requirements.txt 是啥的? 这个就是上面写到的 构建上下文 吗
- 为啥要
copy . .
workdir
workdir指定了接下来所有命令的执行路径- 如果不使用绝对路径的话, 所有相对路径都是以 workdir 为基础的
workdir也不是必须的:
FROM python:3.9-slim
# 复制 requirements.txt 到根目录
COPY requirements.txt /app/
# 安装依赖
RUN pip install -r /app/requirements.txt
# 复制应用代码到根目录
COPY . /app/- 也不是一定都要把应用代码复制到
/app, 这只是 convention
copy requirements.txt .
COPY: 从这个 dockerfile 所处于的目录中 (即构建上下文), 把 requirements.txt 复制到.- 这里的
.是 workdir 了, 也就是/app
copy . .
- 这里是把 构建上下文 中所有的东西都复制到 workdir 里, 即
/app里
build context
是个啥
- 是一系列文件的集合 (a set of files), 用 PATH 或者 URL 参数指定这些文件的路径
- 在构建过程中, 这些文件会被发到 docker daemon, 用来构建 image 的 filesystem 实际执行
$ docker image build -t genx:1.0 .-t:--tag, 给构建出来的 image 命名并标记tag.: 这个就是 build context, 指的是当前文件夹; 在构建镜像的时候, docker 会在当前文件夹里找 dockerfile
namespaces
Note
Namespaces 是容器技术的坚实基础:它不是虚拟机,它没有搞一套虚拟的操作系统接口,而是忠实地把宿主机的信息暴露给了某个 namespace 内的进程,但是不同的 namespace 内的进程之间是相互看不见的。它们都以为是自己在独占操作系统的全部资源。 → 高并发哲学
是什么
namespace 是 linux 里的一种 隔离机制, 让进程只看到 自己所属的 namespace 里的资源 包括:
- PID namespace
- User namespace
- network namespace
- 还有一些其他的 namespace, 一共 7 个 → 每个进程都有 7 个 namespace
进程可以属于不同的 network namespace, 同一台主机上的 不同进程 可以有 不同的 IP 地址 → 那么 container 也可以有不同的 IP → 这里的 IP 指的是 OS 分配的, 在主机上的 IP, 而不是主机通过 DHCP 从路由器那里拿到的 IP
Note
进程的 namespace 是可以任意 combine 的, 比如:
一个 container 的 PID namespace 是自己的, 但是 network namespace 是 host 的。