Why Some Projects Use Multiple Programming Languages
编译
什么叫编译
广义的理解:
- 从 high level code (C 等) 转化成 可执行文件
更广义的理解:
- 把一个 语言 转换成另一个语言 就叫编译
- 通常是指从 high level 的编程语言 转化成 low level 的编程语言
注意:
- 但这里的 low level language 不是特指 assembly code 或 executable binary
- 甚至 high level language 到 high level language 的转换都可以叫 编译
- 因为编译的本质就是 两种语言的转换!
- 以下都是编译:
- C代码 → 汇编代码 → 机器码
- Java代码 → Java字节码
- TypeScript → JavaScript (这就是 high level 到 high level)
- Java字节码 → 机器码(运行时)
- JIT just in time compilation, 过后再展开
- 关键是转换过后的代码更接近于 最终的执行环境, 不管这个环境是 CPU 还是虚拟机 (这里的虚拟机我知道是指 JVM 这样的东西, 但 JVM 具体是什么, 怎么理解这里的虚拟机?)
- wiki 有写, 过后再展开
Note
针对 compile 这个概念, 广义和狭义的理解有区分:
- 从 high level 语言到 low level 就叫 compile;
- 狭义一点呢, 说一个 语言是 compile language, 意思是说它会被编译成 executable binary, 对应的是 interpretive language;
- go wikipedia 第一句话就说 “go … is compiled”;
- 所有语言都是有 广义的 compilation 的; 但这里指的是 go 会被编译成 二进制文件.
boot.dev:
An interpreted program is a program that is executed by another program. The program that executes the interpreted program is called an interpreter. The interpreter reads the source code of the interpreted program and executes it.
从 源代码 到 可执行文件
问题:
- 代码写下来之后, 经历了什么, 才能被 cpu 执行?
- 比如说我写了个
hello.c, 然后执行gcc -m32 hello.c -o executable32, 发生了什么?
- 比如说我写了个
Claude:
代码从源代码到被CPU执行经历的编译过程主要包括以下几个阶段:
- 预处理:处理源代码中的宏定义、条件编译指令和包含的头文件等。
- 编译:将预处理后的代码转换为汇编代码。编译器在这一阶段进行词法分析、语法分析、语义分析、中间代码生成和代码优化。
- 汇编:将汇编代码转换为机器码,生成目标文件。
- 链接:将多个目标文件以及所需的库文件链接在一起,解决外部符号引用,生成最终的可执行文件。 当生成可执行文件后,CPU才能执行它:
- 加载:操作系统将可执行文件加载到内存中。
- 执行:CPU读取指令,解码,然后执行。执行过程包括取指令、指令解码、执行运算以及结果回写等步骤。 不同的编程语言有不同的编译过程。例如,C/C++遵循上述传统编译流程,而Java先编译为字节码,然后由JVM解释执行或即时编译(JIT)为机器码。Python等解释型语言则在运行时由解释器直接执行或编译为字节码执行。
详细解读 以及 claude-code-compile 预处理阶段 (.c 到 .i):
- 文章里执行了
gcc -E, 但我本地跑不起来, 没有这个 flag 编译阶段 (.i 到 .s) - 这里我直接用 .c 来执行 gcc -S, 生成的是个 assembly code (汇编代码)
- 编译阶段就是 从源头代码编程 assembly code 的过程
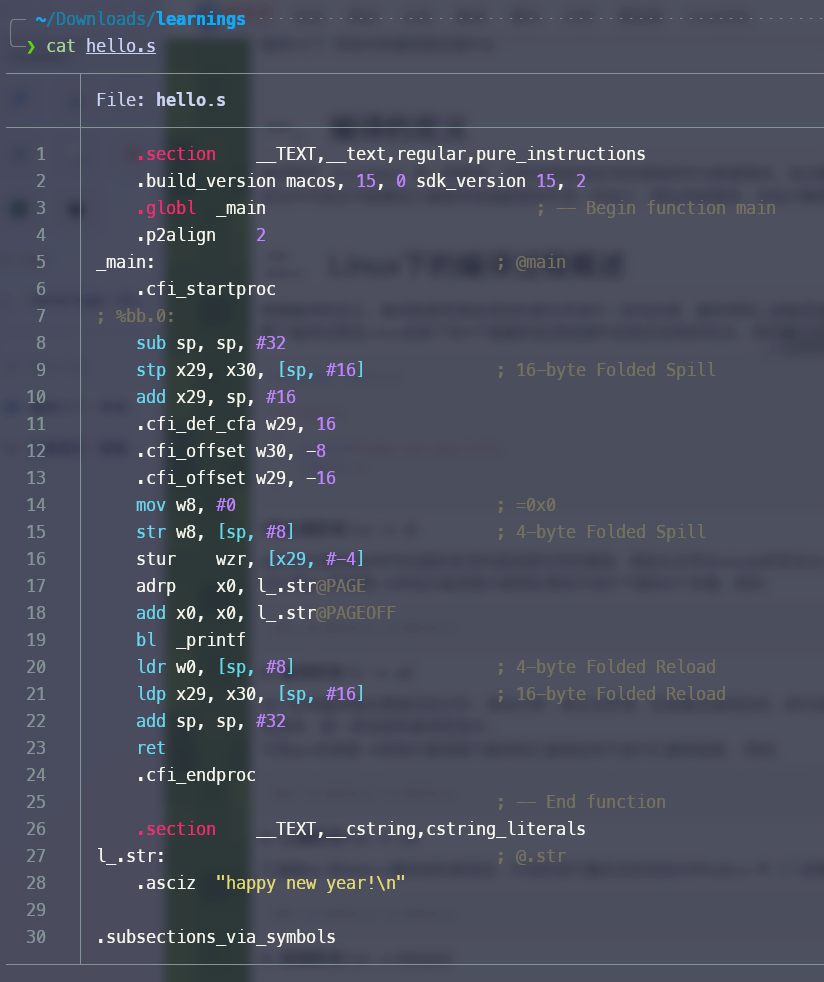 汇编阶段:
汇编阶段:- gcc -c 生成的
.o文件已经是 二进制文件 了, 里面全是 0 和 1 - 但是还不可执行, 因为这个二进制文件还没有和执行所需要的 library 链接起来
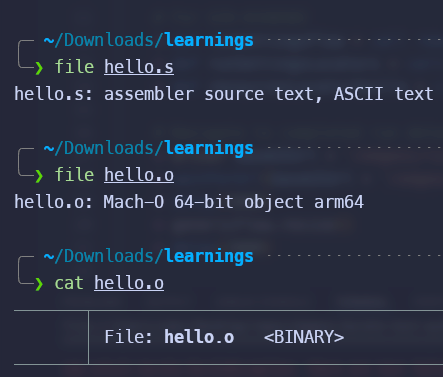
链接阶段
- 目的就是把用到的 library 和 executable binary 联系在一起
stdio.h就是个 library- 链接完之后就是最终产物了, 就可以被 CPU 执行
机器码、字节码
问题:
- 机器码 和 字节码 分别是什么, 差别是什么
- 编译出来的 可执行的二进制文件 (executable binary) 是什么, 属于机器码吧?
- 像 C 这样的语言, 是不是没有字节码
- 字节码应该还是要转换为机器码才能被CPU跑吧? 不管怎么样不是都是 CPU 在执行吗?
- 机器码是 assembly code吗
字节码
- 字节码是一种 中间代码形式, 介于 源代码 和 机器码 之间
- 是由 虚拟机 或 解释器 解释、执行, 而不是 CPU 直接执行
- 像是 java 就是由 JVM 执行, python 由解释器执行
- 同一份字节码可以在不同硬件平台上执行 (字节码应该还是要转换为机器码才能被CPU跑吧? 不管怎么样不是都是 CPU 在执行吗?)
- 代码最后还是要 CPU 执行的, 还是要有二进制文件
- 简单来说, 拿 python 和 来举例, 解释器会 1. 把代码转一行一行换成字节码 2. 根据字节码, 一行一行地调用 C 函数 3. CPU 执行这些 C 函数的机器码
- 这个例子是很简化且不完全正确的, 详细在下面 python 展开
机器码
- 就是由 0 和 1 组成的 二进制文件, 由 CPU 直接执行
- 机器码是二进制文件, 不是 assembly code
- 同一段源代码, 不同 CPU 的架构由不同的机器码 (x86, ARM, etc)
- C 的编译过程: 源代码 → 预处理 → 编译 → 汇编 → 链接 → 可执行文件(机器码)
- C 并没有 字节码 这个中间层, C 的 compiler 是针对 CPU 架构完成
源代码 -> assembly code -> 二进制这个过程的 (所以 C 的很高效很 performant)
- C 并没有 字节码 这个中间层, C 的 compiler 是针对 CPU 架构完成
compile & runtime
- compilation error: happens in compilation, when the code is being compiled to machine code
- runtime error: happens when the compiled code (executable) is being run
python
Important
执行一个 python script 的时候,
python script.py, 这里的 executable 是python, andpythonhappens to take an argument, which is the path to the script.
换句话说, 执行python script.py的时候, 正在跑的不是你的代码, 而是在跑一个叫做python的 interpreter, 这个 interpreter 在解读srcipt.py的内容.
这一点和 C 就完全不一样了; C 是需要先用 compiler 来 compilegcc code.c -o code.o,gcc是这里的 executable, argument 是code.c; 生成的产物code.o是个 executable, 执行./code.c执行这个产物
CPython
官网:
The canonical implementation of the Python programming language
CPython can be defined as both an interpreter and a compiler, as it compiles Python code into bytecode before interpreting it.
- 从官网的那个表述里, 要注意 implementation 这个词, 这样理解: Python 是个更 high level 的语言, 底层是 CPython (在标准的做法里, canonical, 说明 Python 底下也可以不是 CPython)
- 这个 implementation 写的, 和 软件 的 implementation 是一样理解的
- 这个软件是用 C / python / java 实现的; original Python 是用 CPython 实现的
- Python 的其他 implementation:
- Jython → implements Python in Java, Jython 把 Python 编译成
- PyPy → 这个挺有意思的, 用 Python 来 implement Python, 比 CPython 还快 ‘which rightly should blow your mind. :-)’
- 这个 implementation 写的, 和 软件 的 implementation 是一样理解的
- 从 wikipedia 的表述里, 可以看出, 是 human 在 high level 的 layer 写好 Python code, CPython 再去 compiles + interprets
CPython happens to be implemented in C. That is just an implementation detail, really. CPython compiles your Python code into bytecode (transparently) and interprets that bytecode in a evaluation loop. … So CPython does not translate your Python code to C by itself. Instead, it runs an interpreter loop. There is a project that does translate Python-ish code to C, and that is called Cython. Cython adds a few extensions to the Python language, and lets you compile your code to C extensions, code that plugs into the CPython interpreter.
- 这个 evaluation loop 怎么理解
- CPython 解释器的工作方式是一个 loop
- 这个 loop 从字节码的第一条一直循环到最后一条
- 执行对应的机器码
- loop index 移动到下一条字节码
- 这里写了个 simple VM, evaluation loop 是什么一目了然
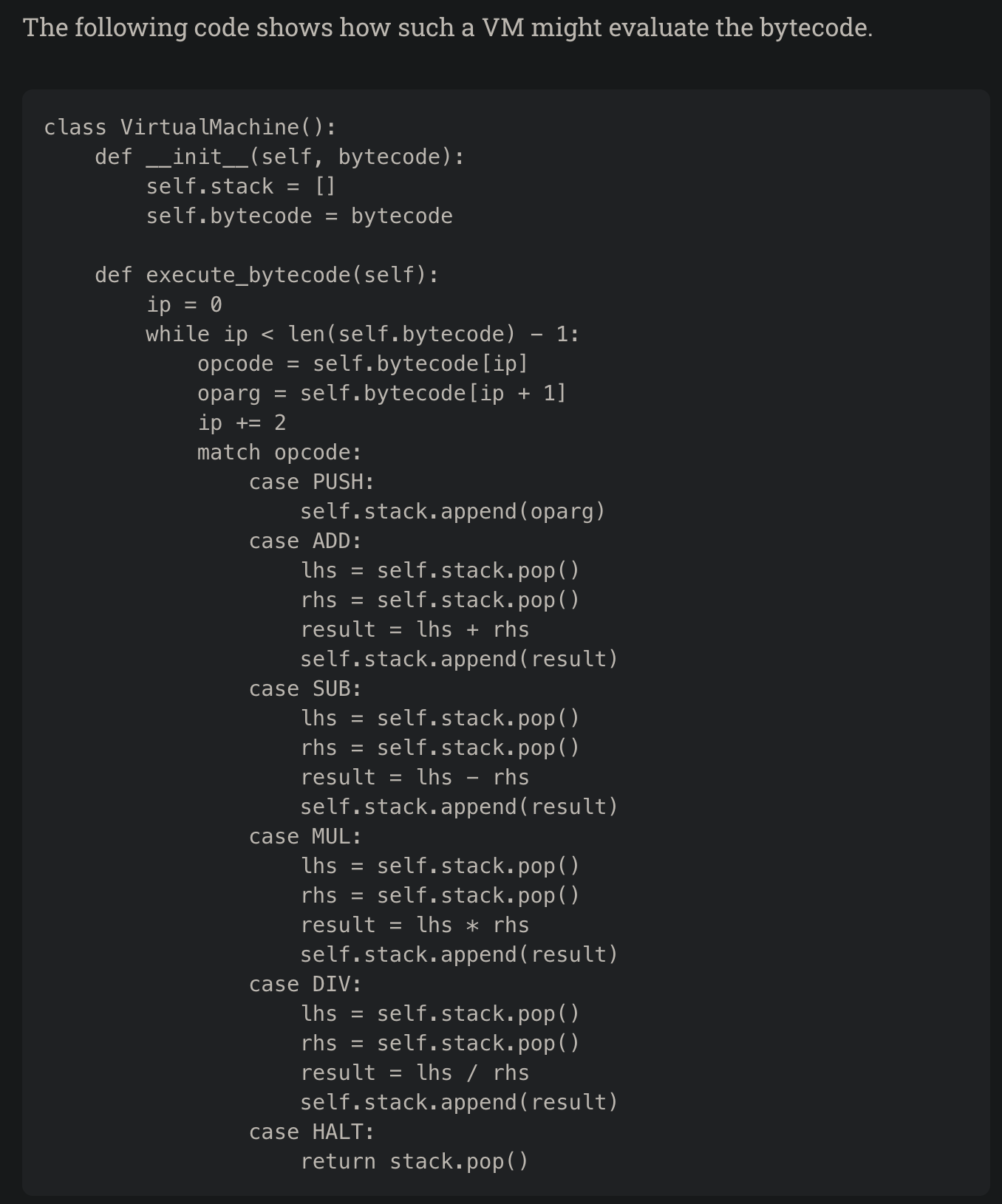
- bytecode 其实就是这样的, 一条一条的 instruction, 这些 instruction 就是这样加减乘除之类的指令
- 源码看下这个 switch, 这些 operation 就是这样被 loop 起来的
- CPython 实际上就是个 interpreter + VM
源码:
def add(a, b):
return a + b
result = add(2, 3)
print(result)字节码:
2 0 LOAD_FAST 0 (a)
2 LOAD_FAST 1 (b)
4 BINARY_ADD
6 RETURN_VALUECython
是个啥
- 首先, Cython 不是 CPython
- 官网: > “The most widely used Python to C compiler”
- 是个 把 python 转成 C 的编译器
- 官网: > “C extensions for Python”
- 看到有种说法是, Cython 是 Python 的 superset
- 和这说法类似, Cython is extending python with C 官网
The fundamental nature of Cython can be summed up as follows: Cython is Python with C data types. Cython is Python: Almost any piece of Python code is also valid Cython code.
- claude: “简单说,CPython是你日常运行Python代码的环境,而Cython是一个工具,帮助你将Python代码转换为更快的C代码。”
virtual machine
问题:
- 为什么一个 programming language 要 virtual machine? 是什么, 干什么, 解决什么问题
- 和那个装 OS 的 VM有什么差别
什么是 Virtual Machine
- 之前学 docker 写的: 容器从 OS 层面实现 virtualization, VM 从硬件层面
A VM is a software program that simulates the behavior of a physical machine, such as a computer or a device.
- 主要就是要模拟硬件
- VM 可以分成 process VMs 和 system VMs
- process VM 一般都会和一个 programming language associated 起来, 比如 JVM
- system VM 就是 full blown operating system
解决什么问题
- write once, run anywhere:
- Java code 写好了之后, 被 java compiler (javac) 编译成字节码 (.class 文件); 这一步与 JVM 无关
- JVM 把这些 字节码 加载到内存里
- JVM 通过 解释执行 (interpretation) 或 just in time 即使编译 JIT, 把 字节码 转化成 机器码(机器码是 executable binary, 不是 assembly code)
- CPU 执行 binary
- JVM 还有内存管理, garbage collection 这些功能
C 不是 write once, run anywhere 吗? 我写的 C 代码, 也可以在不同的 CPU/OS 上跑呀
- C 的源代码写完之后, 是要根据 CPU/OS 来编译的; 换了个不同的平台就要 重新编译
- 编译之后的二进制文件是 CPU / OS specific 的, 在 distribution 的时候是要多个 二进制文件的 (之前字节的 ffmpeg 在那编译平台上就有好多, 同一个版本, 支持不同的平台, 就要不同的产物)
- 有时候还会因为 CPU 不同, 需要改动源代码来优化
- 实际上 C 是 “write once, compile anywhere” 而 Java
- 源代码不需要针对平台改动, 也只需要编译一次, 生成一份字节码
- 只要机器有装 JVM, 就能够跑字节码
- java 源代码是不感知底下的 hardware 的
- JVM 也不是 静态编译器, 而是 动态地去优化生成机器码; 功能复杂得很, 内存管理、garbage collection etc
jvm 是怎么把字节码转换成机器码的?
解释执行 interpretation
- JVM 读取字节码
- interpretation engine 把字节码 映射 到本地机器码的指令
- 执行机器码 (执行与这条字节码对应的 一条或多条 机器码)
- 移动到下一条字节码 JIT
- 简单来说, 相当于是在 interpretation 的基础上, 根据代码的情况 (频繁执行的 func 或 loop 啥的), 进行优化
- 先不展开了
Note
对于 java 来说, 机器码是通过 “字节码到机器码的映射” 来产生的, 没有 assembly code这个中间产物;
对于 c 来说, 机器码是通过生成专门的 assembly code 来产生的.
自己总结下
- 对于不依赖 VM 的语言
- 要根据最后的执行平台和硬件来 编译产物
- 编译(广义)的时候是
源代码 -> assembly code -> 机器码 (executable binary)
- 对于依赖 VM 的语言
- 不需要关心代码最终会在什么地方跑, 只要最后的 host 上有 VM 就行
- 编译的过程是
源代码 -> 字节码 (就是一种中间产物) -> VM 转换成机器码
- programming language 里的 VM, 和之前那个 system 的 VM 其实是类似的概念
- 从 virtualization 的角度来说 (从本质的目的来说), 两者其实没什么差别, 都是 为了方便 application, 把 machine 给 虚拟化 了
- 甚至也可以说, VM 把 high level language 底下的 low level language 给抽象化/虚拟化了, 在写 high level 语言的时候并不需要像是写 low level 那样去主动管理内存之类的
TODO
Java VM 和 python interpreter 的差别是什么?