referen:
TCP/IP & OSI
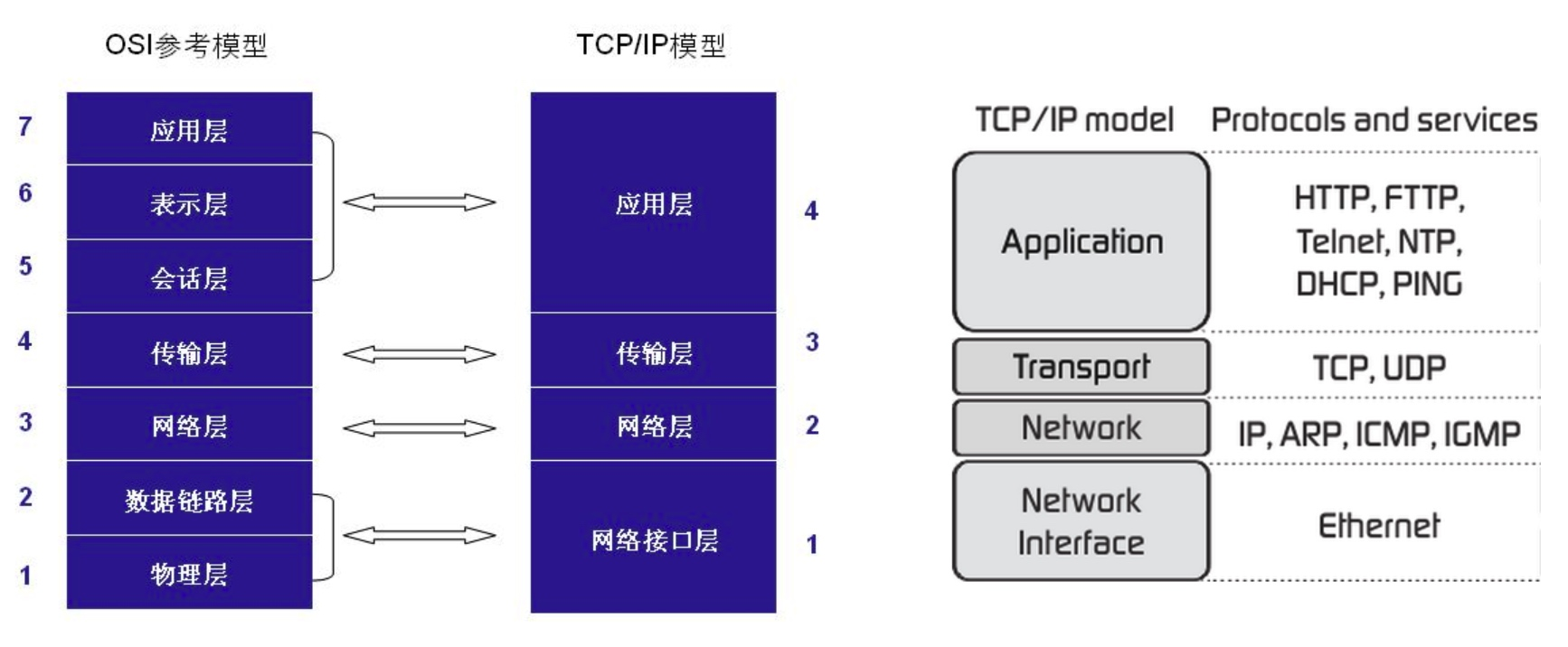
- OSI 7层, 是个更复杂的模型
- TCP/IP 也是个模型, 4层 (应用层、传输层、网络层、数据链路层[网络接口层])
- Linux 的网络协议栈是根据TCP/IP来设计和实现的
- Linux 在内核中实现了 TCP/IP 协议栈
- 什么叫“协议栈”? protocol stack: 一层一层的protocol 叠在一起就是个协议栈; TCP/IP 就是个协议栈
7层和4层load balancer是从OSI的角度出发的
- 7层load balancer是在应用层
- 4层是在传输层
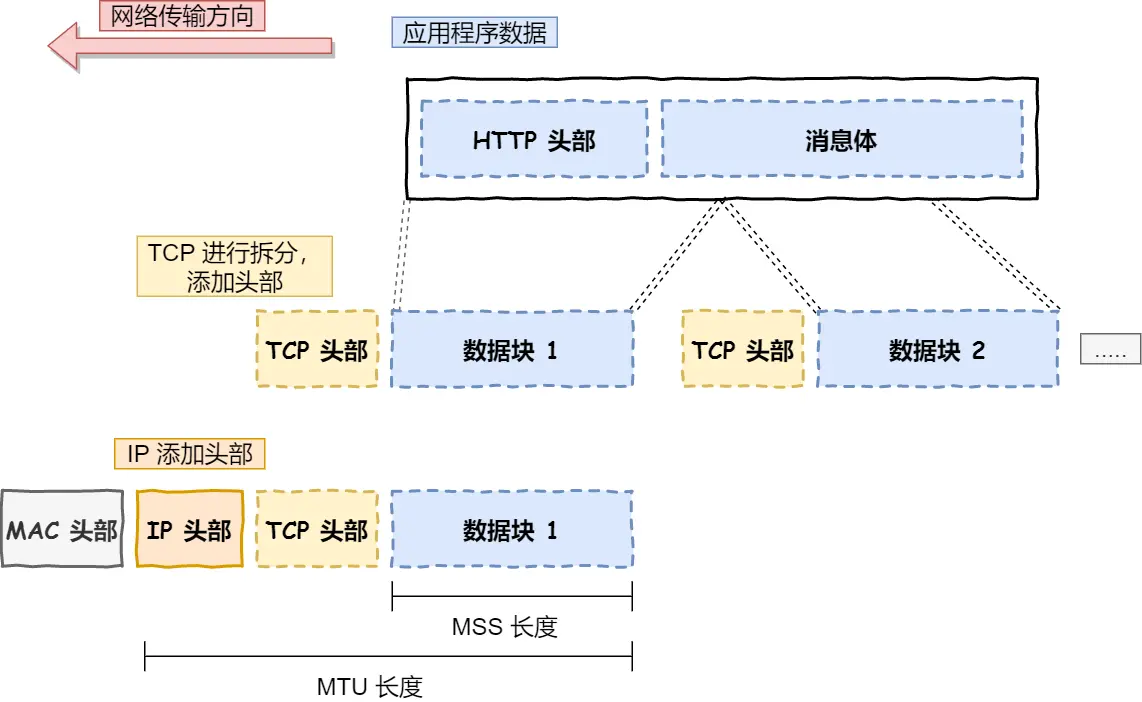
(网络层的限制)以太网中, 能传输的最大的数据包是 1500字节, MTU, Maximum Transfer Unit, 也就是单个IP包最大只能是 1500
- MTU 是 IP 包大小的上限, 不包含 MAC 的header
应用层 (第7层)
- 手机、电脑的应用都是在应用层实现的
- 应用层不关心数据是怎么传输的
- 应用之间需要通信的时候,就把数据传到下一层,也就是传输层
- HTTP、DNS、SimpleMailTP、FileTP 是应用层的协议
问题
而且 应用层 是工作在操作系统中的 用户态,传输层及以下 则工作在 内核态。
- 用户态、内核态是什么意思
- 用户态内核态是 CPU 的两种执行模式 (ring 0 ring 3), 由 操作系统 管理
- 用户态权限少, 不能直接和硬件资源交互, 用户态之间相互独立; 应用程序都以用户态执行
- 内核态是操作系统内核执行的模式, 有最高权限, 能直接操作 硬件资源、内存、网络、CPU调度等
- 应用程序需要和底层硬件交互的时候, 是先调用 system call , 然后操作系统切换到内核态, 再由内核态完成 system call的
- 这句话是什么意思
- 在网络协议栈中, 应用层的协议, 如 HTTP、DNS 等, 是在用户态实现的; 他们定义了应用程序是如何和网络进行通信的, 但是不直接和 网络数据包 打交道, 不涉及数据包的 传输和组装
- 传输层、网络层、数据链接层的协议, 需要 和硬件打交道、重组网络包、管理网络链接状态 (TCP握手建立连接), 是内核态实现的
- 为什么 http 不涉及数据包的 组装?
- http 只定义了 请求和响应, 并不关心数据包的封装; 换句话说, http 这个协议没有说 怎么发送数据, 只是定义了用户想要传输的数据的格式, http 没有定义数据包的 header 这些
http
dns (domain name system)
dns 是个 应用层 的协议
工作原理:
cloudflare - the 8 steps in a dns lookup 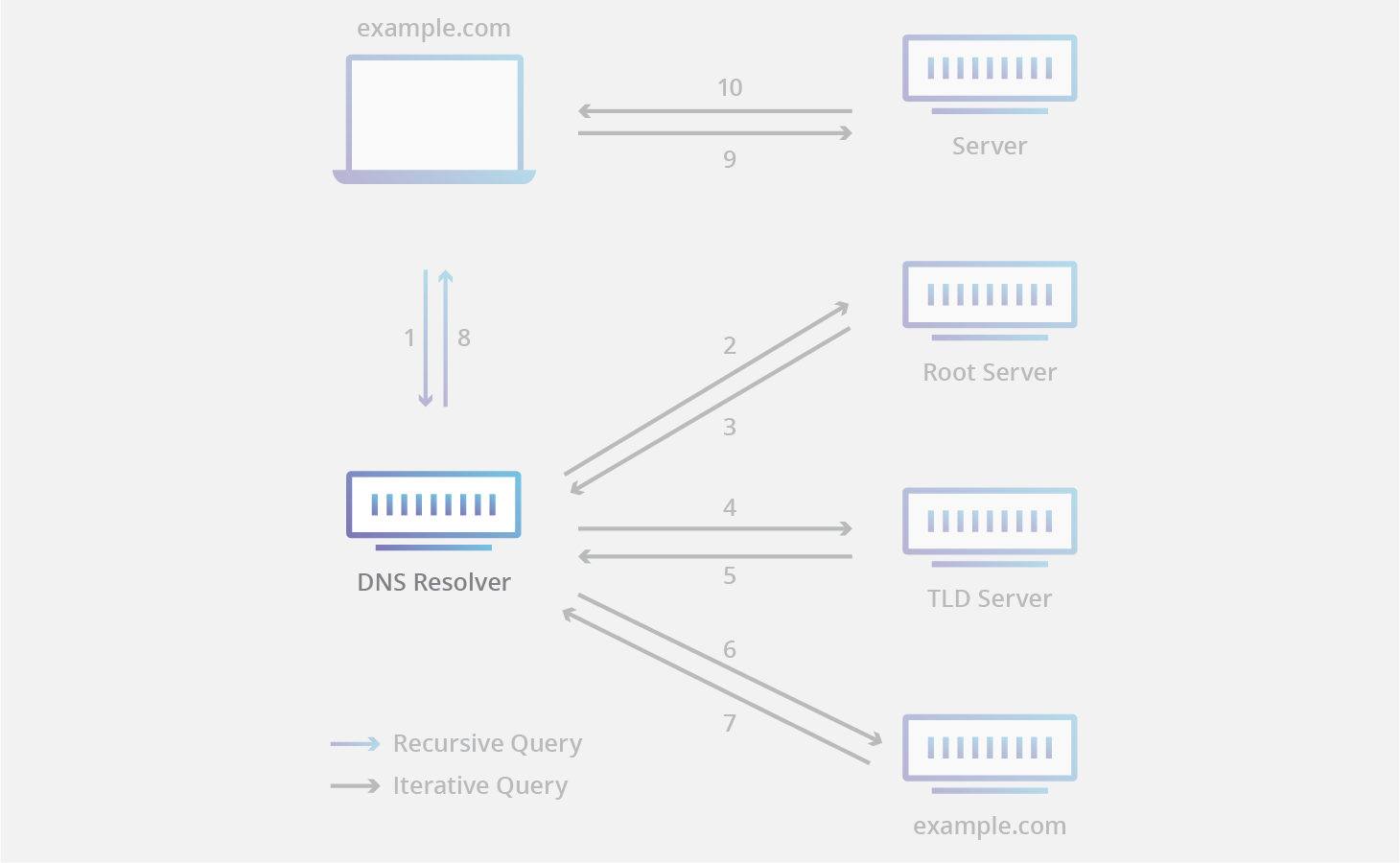
- 一般来说, dns 是基于 udp, 但是如果返回结果过大, 可以通过 tcp
- 每个电脑都有 13 个 root domain name server 的 IP 地址
- 需要找一个 域名 的 ip(www.example.com) 地址的时候, 就 从上到下 地 递归 (recursive) 查找:
- root → top level → authoritative
- root 返回 能够查询
.com的顶级域名的 域名服务器 - 能够查询 .com 的顶级域名服务器返回 能够查询 example.com 的 权威域名服务器
- 权威域名服务器 能够找到 www.example.com 的 ip
Note
注意, 每一次 域名服务器 返回的都是 下一层域名服务器的信息
本身 域名服务器 和 要访问的网站 之间没什么关系
nameserver 种类
- dns recursor (dns resolver)
- 帮忙去 recursively 递归请求 dns query 的 dns server
- cloudflare 的 1.1.1.1, local isp 的 nameserver 都是 dns resolver (aka dns recursor)
- root nameserver:
- aka
., 世界上有 13 个, 每个 recursive resolver 都知道这 13 个 root dns nameserver -
“根域名服务器:全球共13组(逻辑组,实际物理服务器更多),由ICANN、Verisign等机构管理.”
-
“Note that while there are 13 root nameservers, that does not mean that there are only 13 machines in the root nameserver system. There are 13 types of root nameservers, but there are multiple copies of each one all over the world”
- aka
- Top level domain nameserver:
.com,.net,.org这些
- Authoritative nameserver:
- dns query 的最后一站, 到了最终能够敲定 dns query 结果的 server (所以叫做 authoritative)
- ==在注册一个域名的
A record,CNAME record的时候, 就是和 authoritative nameserver 注册==- 所以 authoritative nameserver 能够把完成最后
domain name -> ip的这一步 - 如果这个 domain 解析出来还是个 CNAME record, 那 authoritative nameserver 会给出这个 CNAME record 指向的 域名; 然后 dns recursive resolver 由从头再来一次 dns lookup
- cloudflare: “if the domain has a CNAME record (alias) it will provide the recursive resolver with an alias domain, at which point the recursive resolver will have to perform a whole new DNS lookup to procure a record from an authoritative nameserver”
- 所以 authoritative nameserver 能够把完成最后
- authoritative nameserver 大多数都是第三方的, 如 Cloudflare、AWS、GoDaddy
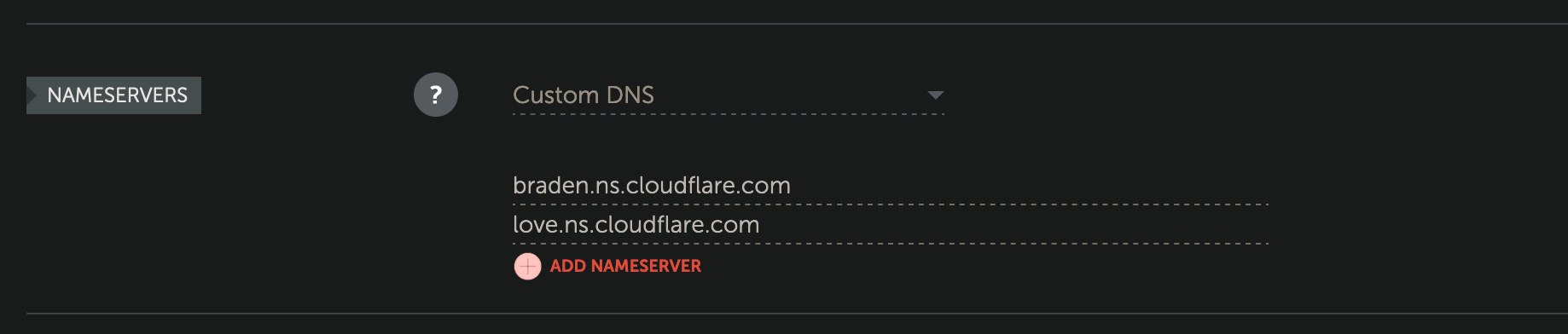
- 也会存在 二级权威域名, 我在 namecheap 上面就是把 authoritative nameserver 设置成 cloudflare 的了:
Note
dns lookup 是个 自上而下 的过程. (从 root 开始)
迭代 iterative 和 递归 recursive
- 一般情况下, ISP 的 DNS server 会作为一个 resolver 的角色, “根域名-顶级域名-权威域名” 的这个查询, 是 iterative 的, 每次都需要 resolver 自己去查 (resolver 发了多个请求 - iterative 迭代请求)
- 对于客户端来说, 这个过程反而是 recursive 的, 因为是 resolver 去查, resolver 一层一层深入, 找到 IP 之后返回 (客户端只发了 1个 请求 - recursive 递归请求)
- cloudflare explanation
客户端是怎么和 dns 服务器发消息的?
问题: dns 服务器的 IP 地址是怎么来的?
- 通常都是配置的, 比如说 google 的是 8.8.8.8, cloudflare 的是 1.1.1.1
- 或者是 ISP 提供的 (也是预先就配置好的)
- 通过域名找IP, 我们总得要一个 IP 才能开始嘛, 这个 IP 就是操作系统上配置的 本地域名服务器 的 IP 地址
TTL
- 数据包在被 router 不断转发的时候, 有 TTL 的概念; 这里的 TTL 的单位是 次, 是指 数据包在 router 之间的 跳数
- dns 也有 time to live 的概念, 这里的单位是 秒, 指的是 dns entry 在 客户端本地 和 本地域名服务器 被缓存的 时长
dynamic domain name system (DDNS)
大部分人都没有一个 static IP, 大部分人家里的 IP 都是 由 ISP 分配的动态 IP 也就是说, 如果家里的 modem 重启过后 (从子网中断开后重新接入子网), 可能就会被分配一个新的 IP 如果用自己的 家庭网络搭建服务器, 怎么根据 DNS 通过 domain 再来找到 家庭服务器 的不断在变化的 IP 呢?
DDNS:
- 在路由器、服务器配置 DDNS , 每次在 IP 地址变更的时候, 会主动地和 domain name server 更新自己的 DNS 记录
- 这样每次有人 DNS 查询的时候, domain name server 就能够返回最新的 IP home server 怎么样更新自己的 dns 记录的?
- 通常有个软件, 如 inadyn, ddclient, 有的操作系统自己或许也可以实现?
- 软件里配置以下信息: dns server 的 IP 地址; 用户名, 账号密码; 需要更新的域名
- 监测到 IP 变动的时候, 就会把这些信息发给 dns server
Reverse DNS
反向 DNS: 通过 IP 来找到 域名
web socket
是什么?
- 应用层的协议, 建立在 TCP 之上
- 借用 http
原理
握手阶段:
- 依赖 1 个 HTTP 请求来握手, 请求头中有
upgrade的字段, 请求升级为 WebSocket - 服务端支持 WebSocket 的话, 会返回
101 switching protocol的状态码 通信阶段: - protocol switch 之后, 就会不再依赖 http, 直接通过 tcp 通信
- 全双工通信, Full Duplex
使用场景
- 游戏, 聊天: A 给 B 发消息, B 不需要主动发 http 请求去 fetch, 而是 server 直接推送给 B
好处
- 实时性: 快
- 减少带宽和其他资源消耗: 不需要 轮询 这种机制, 减少了请求量
- 双向通信
传输层 (第4层)
- 传输层是给应用层提供网络支持的
- 传输层有两个协议: TCP、UDP → TCP、UDP是传输层的协议
| TCP可靠 | UDP简单、高效 |
|---|---|
| 超时重传、流量控制、堵塞控制、顺序控制 | 只管传送,不管数据是否到达 |
| 基于字节流 byte stream, 没有 message boundary | 基于数据包 datagram, 有 message boundary 的概念 |
- UDP可以在 应用层 实现一些TCP的特性,比如:顺序控制:为每个发送的 UDP 数据包加上序号,接收方可以根据序号来重新排序数据包。
- 这样应用层的实现,需要数据传输的双方达成一致共识,难度大
TCP
- TCP协议传文件,是按照 tcp segment 来传的 (tcp 的 数据包 叫做 tcp segment);有最大的segment大小 maximum segment size (MSS)
- 当数据包超过MSS的时候,就要把数据报拆成多个 segment
- 传输过程中有某个segment丢了的情况,只需要重新传对应的segment就行
端口(针对数据接收方)
- 同一台设备可能有多个 进程 在接收数据,因此需要端口来区分、识别, 这里想要强调的是: 端口是根据进程需要分配的
- IP是地址,端口是门
- 例子:浏览器中的不同标签页都是独立的进程,都有不同的端口,由OS临时分配
TCP的一个数据包是怎么样的
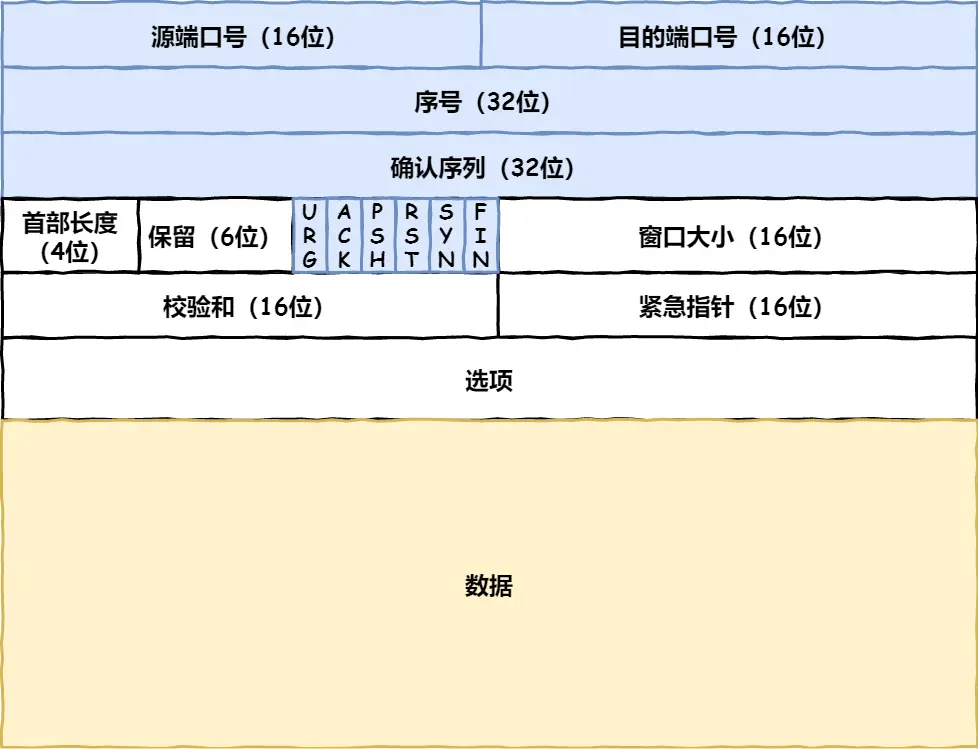
- port: 就是ip:port里的port, (TCP是传输层的协议, 在网络层协议IP之上)
- sequence number 序号: 是这个 tcp segment 在一整个 tcp 连接中发的包的顺序, 用来防止丢包的
- ack sequence number 确认序列: 确认收到了发送方的序号 (对应收到的tcp segment的序号)
- 一些control flag: ack, syn, 发送这个tcp segment的状态, 用来建立、维护、结束tcp连接的
- 窗口大小: 发送方能够接受的数据的窗口大小(单位是字节), 用来控制流量
- checksum 校验和: 用来确认传输过程中这个tcp segment是否发生了错误
Note
要注意的是, 端口 是 传输层 的概念, 不是 网络层 的概念, 端口和 IP 虽然写成 IP/Port 的形式, 但是两个是不同层面的概念
- IP 是 地址, 端口是 门, IP 负责找到 主机, 不负责找到主机上的 进程;
- TCP 是传输层的协议, 负责 服务应用层
- 应用层指的就是 进程 了, 所以 传输层的协议 在 网络层协议 找到 主机 的基础上, 再去找 进程
- 到了对面的主机过后, 要怎么找到对应的进程, 就是对面主机的事了 (对面的主机是通过 socket 找到进程的哈, 进程通过 socket 来进行网络 I/O)
- 从 物理传输 的角度上来说, 网络层是找到了 物理主机, 传输层负责 数据传输, 是由 操作系统(socket) 来把数据 路由 到对应的 进程
TCP连接的三次握手是怎么样的
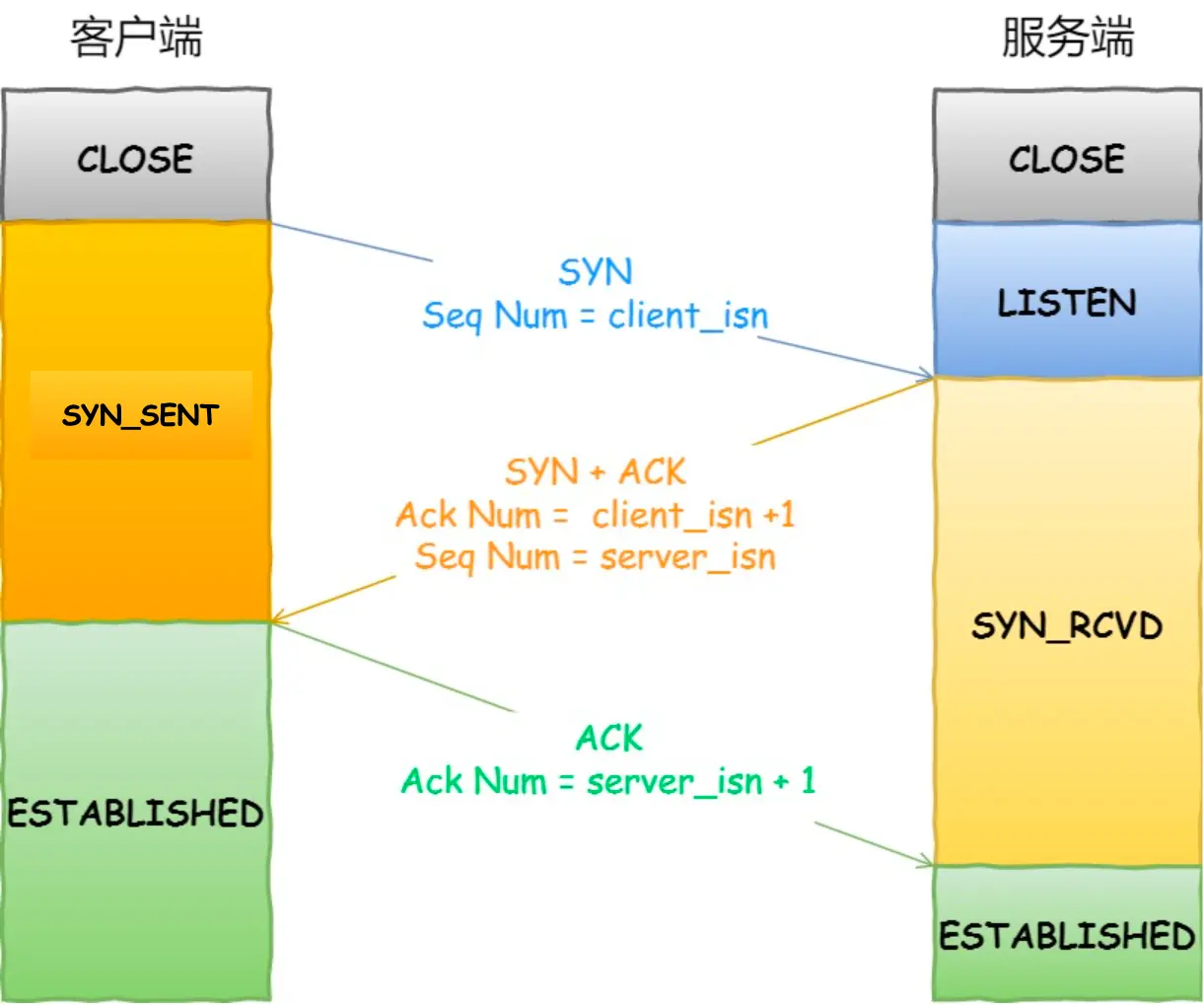
- 握手1: 客户端发送 syn 和 sequence=x
- 握手2: 服务端收到 syn, 发送 syn 和 ack, sequence=y, ack seq=x+1
- 握手3: 客户端收到 syn 和 ack, 发送 ack, ack seq=y+1
- 发送的ack是收到的seq加1
- 第三次握手客户端没有发送seq
Note
tcp 的重传机制也适用于握手:
在握手阶段, 如果某个 tcp segment 丢了的话, sender 会重传丢失的 segment
四次挥手
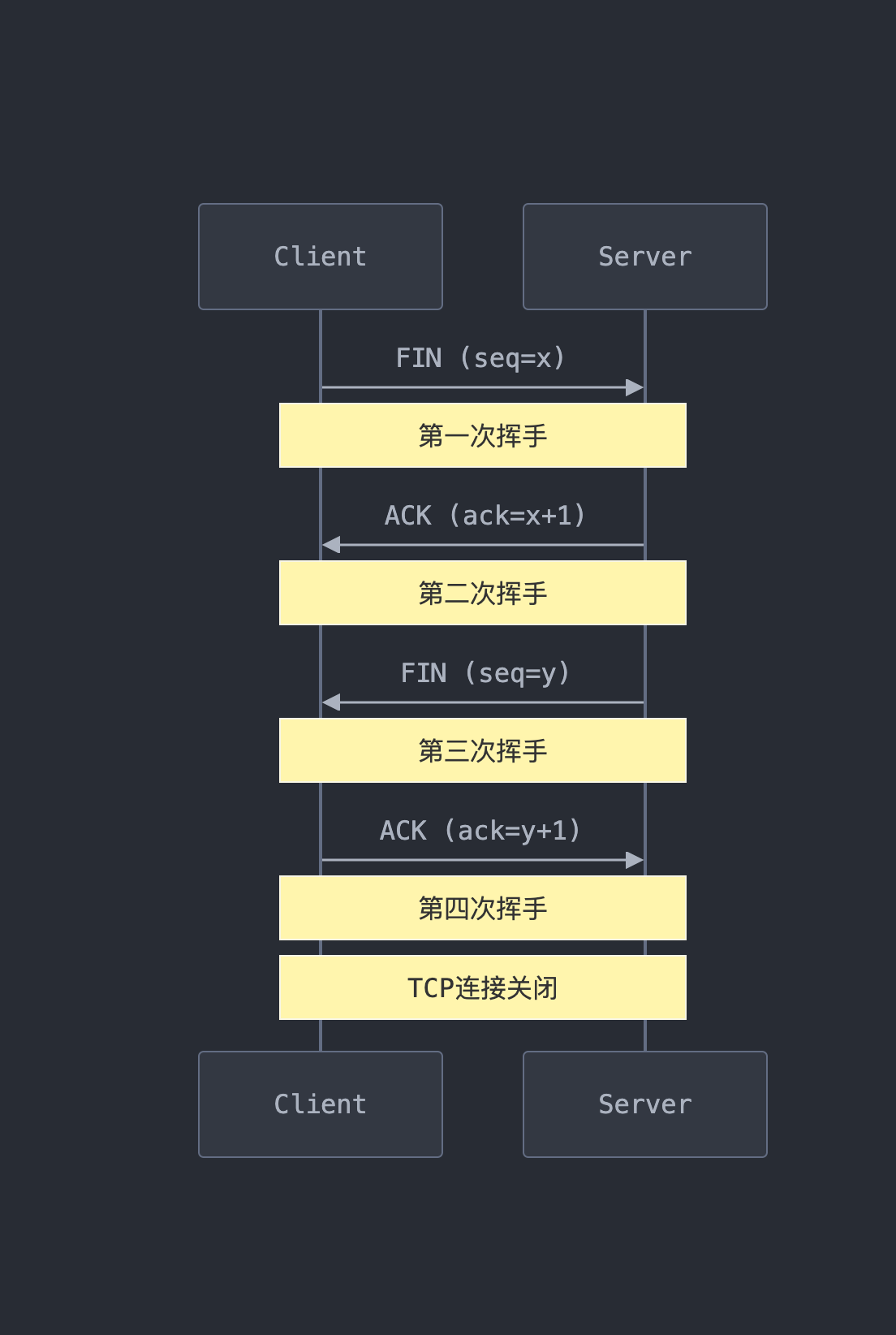 四次挥手:
四次挥手:
- 客户端会先发送fin
- 服务端收到后, 发ack来 acknowledge 收到fin
- 然后服务端发 fin, 代表能够正常结束连接
- 最后客户端发 ack, 来 acknowledge 收到了 fin
为什么第二三次回收, 服务端的 ack 和 find 不一起发? 在握手的时候 ack 和 syn 就是一起发的
- 客户端发 fin 的目的是, 发一个 “关闭连接” 的信息, 发了fin之后客户端就不会再发数据了
- 服务端收到fin之后先发ack, acknowledge 收到了 fin
- 但是服务端可能还有数据要发给客户端, 还不能发 fin
- 等服务端发完所有数据之后, 才会发 fin
- FIN 的意思更像是在说 “我发完了”; 只有客户端真正把数据发完了, 才会发 FIN
全双工
- TCP是全双工通信 单工 → 只能有一方发消息 (hafl duplex) 半双工→ 双方都能发消息, 在一个时间只能有一方发消息 (full duplex) 全双工 → 在同一时间双方都能发消息
TCP是个字节流协议
- 在使用 tcp 协议传输数据的时候, 传输的数据是一条 字节流, 数据是 字节序列
- TCP 作为传输层的协议, 是不知道怎么分割这条 字节流 的; 对于 TCP 来说, 这些数据流 没有边界的概念, 就是 一条流
- 应用层来的数据被 内核 分成一个一个的 TCP Segment, 这些 segment 可能是 任意大小的 (内核会根据 窗口、堵塞 这些情况来 动态调整 TCP segment 的大小)
- 需要传输的双方达成协议 (http), 来确定好发送的时候要怎么打包, 接收的时候要怎么拆分
- UDP 是个 面向数据报 的协议→ UDP 发送的数据都是 以消息为单位 的, 保留了 应用层数据的边界, 一个数据包就是一个消息
- 当然, 会出现消息超过数据包长度限制的情况, 这时候就需要应用层来处理了
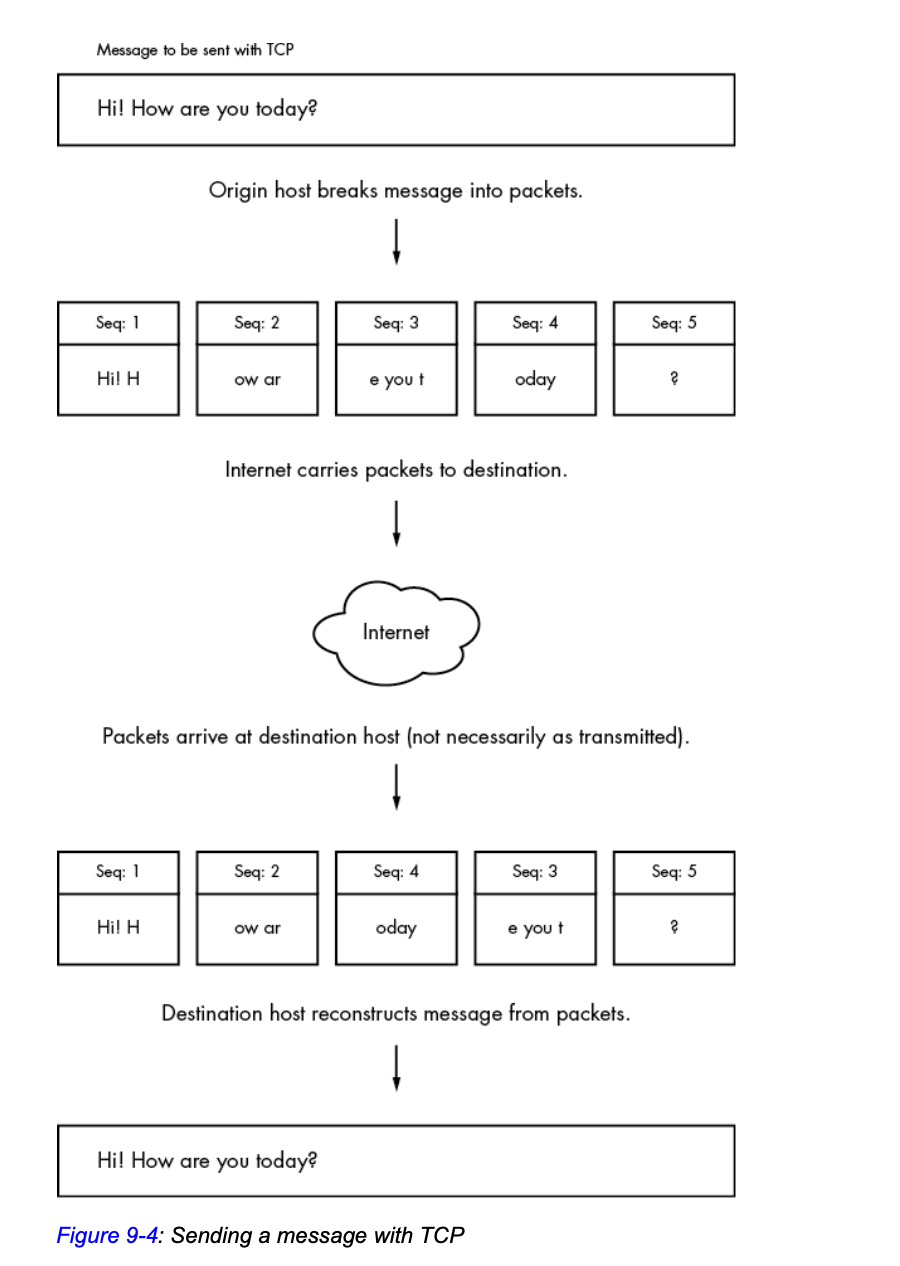 source: how linux works
source: how linux works
- 当然, 会出现消息超过数据包长度限制的情况, 这时候就需要应用层来处理了
TCP 是面向字节流的协议
- 在使用TCP的时候, 操作系统会拆分消息. (一个完整的消息, 可能会被拆分成多个TCP segment发出去)
- 这里指的操作系统是, 应用程序确认发送信息之后, 信息在内核又被处理了, 内核会根据拥堵情况, 窗口大小这些信息来调整发送的数据包的大小, 也就是会动态地拆分信息, 分割成不同的长度的TCP segment.
- 接收方如果不知道消息的长度, 那就不能把一个一个的数据包又拼凑回完整的消息
字节流 byte stream? 数据包?
明明 tcp 也是按照 segment 来发的, 也是一个一个的数据包, 为什么又说它是 字节流?
- 这里的字节流是说数据从 应用层 传到 传输层 的时候, 传输层是不会根据这个数据的 message boundary 去划分的
- 比如说, http 的请求是 500 byte; tcp 怂管, tcp 只会通过 congestion window、receive window 来调整数据包的大小, 而不会根据 http 请求的这个 消息边界 来拆分
- 所以在应用层还要特别定义, 防止出现 粘包 sticky packets 的问题
TCP 粘包
- 不知道数据包的边界在哪, 不知道怎么样拆分数据包, 才能得到有效的信息
- 解决方案:
- header 用 回车、换行、空格 等特殊符号作为区分
- body 用 header 里的 content-length 区分
- 以上解决方案都是http的处理, 也就是 应用层 的处理
问题
TCP 的超时重传、流量控制、堵塞控制分别是怎么实现的
- 超时重传: sender没有收到receiver的ack, 一定时间过后就会重新传送没有被acknowledged的tcp segment
- 丢包重传: sender发的某个包没有被acknowlegde, 会重新发送 (丢包可以理解为超时很久了就判断为丢了)
- 流量控制: tcp segment的头部中包含了window size, 告诉 receiver “sender能够接受的最大字节数”, 也就是告诉receiver, “我一次能够接受的流量最大有这么多”; receiver会根据sender的窗口大小来调整自己发送的速率 (通过窗口和MSS算出每个周期能发多少个segment?)
- 拥堵控制: 慢启动, 根据接受的速率动态调整控制发送的速率
拥堵控制还是不是很懂
TCP 的流量控制 flow control
是什么:
- 流量控制是控制 数据包发送的速度, 来防止出现 接收方 接收不过来的现象
- 一句话: 防止发送速度超过接收方处理的速度
- 本身接收到的 TCP segment 会放到 接收方 的 缓冲区 里, 缓冲区是有大小的 原理:
- 在 TCP segment 里有 窗口大小 的字段, 在 TCP segment 来回传输的时候, 接收方会告诉发送方 自己能接受的窗口大小 (缓冲区的可用空间)
- 发送方会根据这个窗口大小来调整自己发送的 速率
- 接收方会根据自己缓冲区的使用情况 动态调整 这个窗口大小 问题:
- 窗口大小的 单位 是什么? 字节吗?
TCP 拥堵控制 congestion control
为什么会发生congestion?
- 如果网络状态差导致延时、丢包等, RTT超过了最大的等待interval的话 (发出去的包一直没被acknowledge), 就会重新发送同一个包
- 实际上只是速度慢, 并没有丢包的话, 在同一个tcp连接上就会有很多个相同的 tcp segment
- → more and more copies of the same datagrams into the net, use up receiver’s buffer
- 比如说: 用户1在以网络的最大速度从server1获取数据, 如果在同一个网络下的用户2突然开始大量使用网络带宽, 用户1能使用的带宽就少了; 如果server1又还是保持同样的速率的话, 那数据包就会堵塞, 很多可能就丢了; 并且对于超时的包, server 又回一直重传, 把 client 的缓存区都打爆了
是什么:
- 有几种不同的方法来实现 拥塞控制
- 目的是: 防止网络过载
- 和流量控制对比: 流量控制的目的是防止 发送方发送的速度大于接收方处理的数独, 而 拥塞控制 不只局限于 发送方和接收方, 而是从整条 网络链路 出发考虑的 原理:
- 拥塞控制有自己的 congestion window, 和 flow control 的 window 不是同一个
- congestion window 不是在 receiver 和 sender 之间传递的, 是传输方根据 ack 的数量和发送的包的数量 来决定的
- 被 ACKed 的数据包越多, congestion window 增长得越快
- 流量控制是由 窗口大小 直接决定的, 而 拥塞控制 是由 RTT、丢包情况、网络延时 等 网络状况 决定的 几种实现方法:
- 慢启动: 刚建立连接的时候, 不知道网络情况, 就发很少数据, 每次收到对方的 ACK 后, 就会增大数据传输量
- 拥塞避免: 如果出现丢包的情况, 会减小窗口大小, 减小数据发送量
- fast recovery: 丢包之后快速恢复
ports
- 注意端口的序号和虚线
- 能在这个 wiki page 看到, 每个端口都有一定的用途:
- 49152 到 65535 号端口是 临时端口, 用于 临时会话 和 客户端的应用程序
UDP
Note
记几个关键词, 面试啥的好回答 UDP 的特点:
- 无连接, 不可靠, 面向报文 datagram
Note
同样的, TCP 的特点就是和 UDP 相反:
- 有链接, 可靠, 面向字节流 byte stream
- 无连接、更轻量、不可靠、面向报文 (而不是tcp那样面向字节流)
- 包含一个很小的header和数据body
- 使用udp的话, 要在应用层自己实施一些错误检查、丢包的纠正机制, 来降低不可靠性 面向报文怎么理解:
- UDP的一个数据包就是一个消息, 每个包都是独立的, 包与包之间没有联系
- TCP的数据包之间可能是有相互联系的 (一个消息被拆成了多个数据包, 这些数据包就是一条字节流; 也有 seq number 啥的)
当然, UDP传输的数据包是有大小限制的, 超过一个数据包大小的消息, 会被拆成多个数据包发送;
- 接收方怎么知道要如何把这些数据包拼起来? 数据包都是无序的, 收到的顺序和发送的顺序甚至可能都不一样?
- → UDP 本身是不提供消息分割和组装的功能的, 操作系统不会对信息进行拆分; OS 加个UDP的头之后就交给网络层了
- → 超过大小限制的数据, 那就要在应用层处理, 在应用层标识顺序之类的 (QUIC)
==Port 不是 TCP 独有的概念, UDP 也是有 Port 的== → port 是 linux 上的概念
Note
DNS 是 基于 UDP 的协议
DHCP 也是基于 UDP 协议
→ connectionless 的一般都是 UDP
另一个理解 UDP 的思路
(UDP) is little more than an interface to IP…
it merely pushes the datagram out on the net and accepts incoming datagrams off the net.
UDP adds two values to what is provided by IP. One is the multiplexing of information between applications based on port number. The other is a checksum to check the integrity of the data. → rfc 1180
理解这句话
- multiplexing: handling multiple data streams simultaneously
- 电脑上跑着多个程序的时候, 程序 A 用 port 123, 程序 B 用 port 234,
- UDP 根据不同的 port, 来处理来自不同程序的 data stream
UDP preserves the message boundary defined by the application. It never joins two application messages together, or divides a single application message into parts.
QUIC
是什么
QUIC 也是一个 transport layer protocol, 基于 UDP → QUIC uses UDP instead of TCP as its basis.
网络层 (第3层)
IP协议
-
传输层并不负责从设备到设备之间的传输,传输层只服务应用层,不管数据在网络上是怎么样传输的(网络上传输指的是地址、路径、节点这些)
-
IPv4 → 4 * 8 = 32 位
-
怎么通过IP快速找到设备 → 先找到这个设备在哪个子网里, 再找到设备是子网里的哪个主机
- 网络号 → IP地址和子网掩码bitwise and operation得到
- 主机号 → 子网掩码的0和1invert下, 再和IP进行bitwise and operation
Note
The IP header contains the IP address, which builds a single logical network from multiple physical networks. → RFC 1180
子网掩码:
• /24(255.255.255.0):常用于小型局域网 • /16(255.255.0.0):用于较大的网络 • /8(255.0.0.0):用于非常大的网络 → 子网掩码 越大, 说明 网络号 占的位数 越多, 说明 主机号 占的位数 越少, 主机少说明 网络小 (子网掩码和IP地址做 bitwise and operation, 所以子网掩码的位数和IP地址一样, IPv4 的子网掩码是 32 位)
多个 IP 地址
- 一个主机可以同时用 IPv4 和 IPv6
- 一个主机可以有多个 IPv4、IPv6 地址
- 一个主机可以有多个网卡, 对应多个 IP;
- 一个路由器在多个子网中存在的场景?
- 一个主机也可以有一个网卡, 对应多个 IP ??
- 一个主机可以有多个网卡, 一个 IP??
CIDR - classless inter domain routing
传统网络
传统网络有分 A B C 类.
- A 类: 网络号是 前8位, 第一位必须是 0
- B 类: 网络号是 前16位, 前两位必须是 10
- C 类: 网络号是 前24位, 前三位固定是 110 简单来说, ==传统的IP是有 class 的, 不灵活, 还浪费资源, 导致路由器上的 路由表 不断膨胀==
CIDR
是一种 ==分配 和 路由 IP 地址的方法==
- 不用传统的网络的 class 了, 所以叫 classless
- 通过 IP地址的前缀 来识别网络, 不依赖 IP 地址的类来决定子网的大小
- ==CIDR主要表现是 子网掩码 的一种书写格式==
- /24 这个就是CIDR格式, 斜杠+数字
- 数字表示IP中, 网络号所占的位数
Note
简单来说, CIDR有两个重要的点:
- CIDR 和传统的类不同, CIDR 是 classless 的, 没有 ABC类这种固定的形式
- CIDR 用更灵活的方式表达子网掩码 (前缀长度)
→ any number of bits can be reserved for network
聚合路由:
- 路由器里面会存一个路由表, (路由表是干嘛的?)
- 用 CIDR 这种前缀长度的方式来标识网络, 就可以把 拥有相同网络号 的 IP地址 汇聚在一起标识
- 比如:
- 192.168.0.0/24 表示 256 个地址
- 192.168.1.0/24 标识 256 个地址
- 这些地址一共可以合并成 192.168.0.0/23
路由
- 路由就是根据IP地址中的网络号来转发的
IP 层的数据包
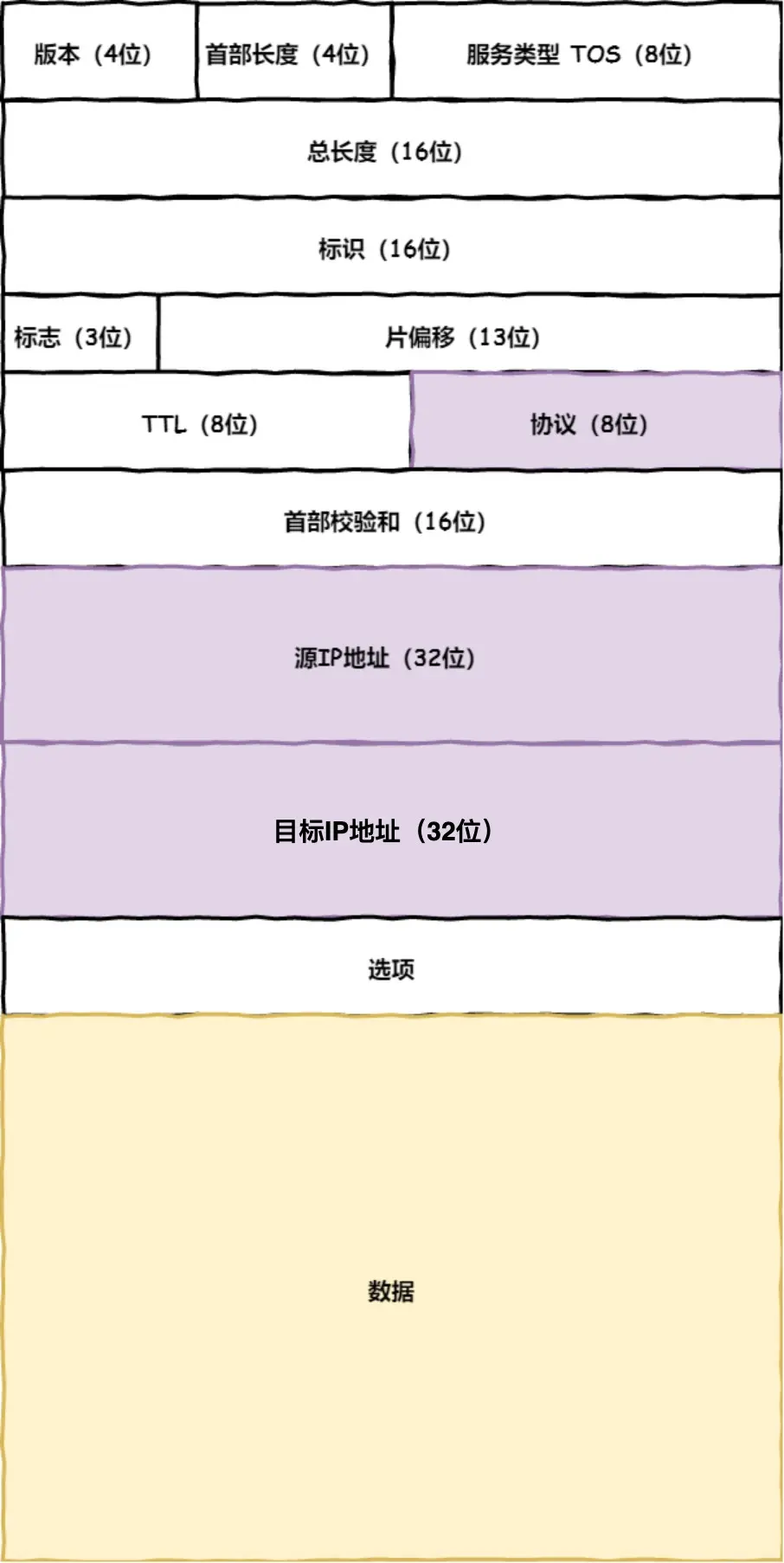
IPv4 IPv6
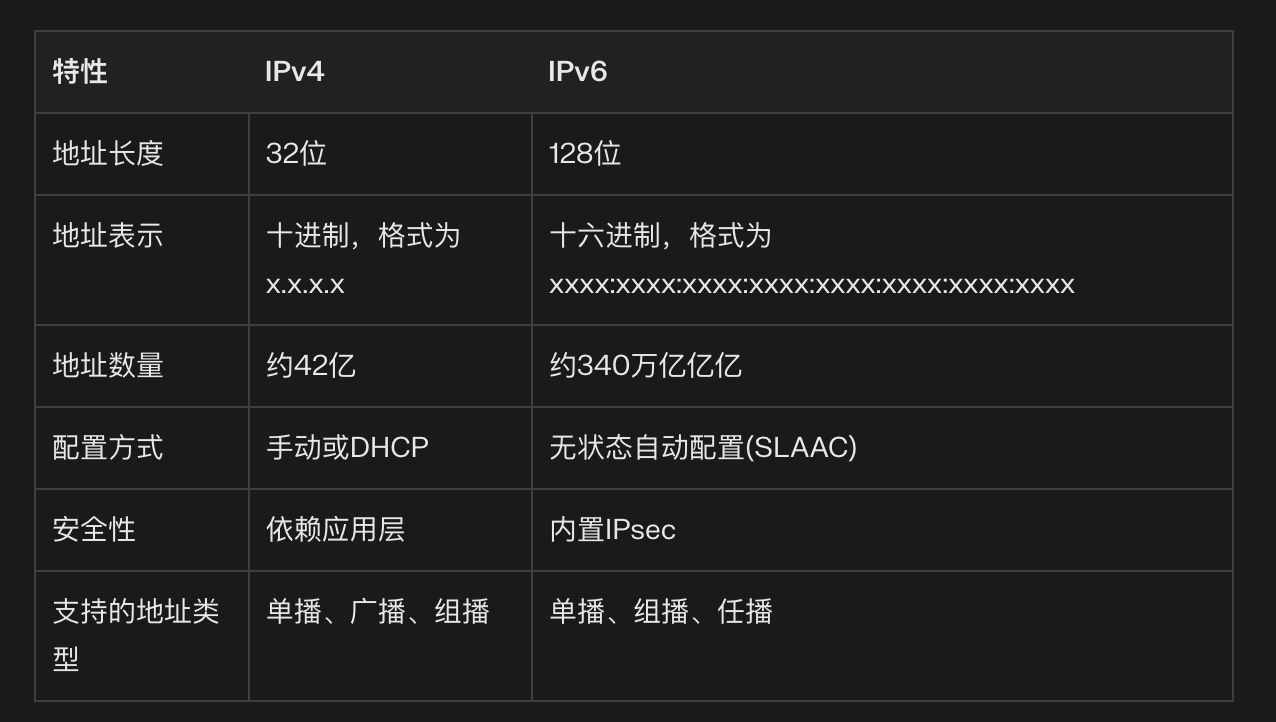
IPv4:
- 4 组 10 进制数字; 4 * 8 = 32 位, 能提供 2^32 个地址
- 安全性: 依赖 应用层, 没有内置的安全功能
- 依赖 DHCP (动态主机配置协议) 进行 IP 分配
IPv6:
- 解决了 ipv4 地址资源耗尽的问题
- 8 组 16 进制数字, 每组4个; 4 (每组4个数字) * 8(8组) * 4(一个16进制数是2^4, 需要4位) = 128 位
- 安全性: 内置了 internet protocol security
IPv6 没有广播, 没有广播地址
那是怎么实现广播的功能的呢?
- 不需要所有设备都监听一个地址, 让一些特定类型的设备监听对应特定类型的地址就行了
- 比如说, 定义一个地址, 专门用来发 DHCP 的信息, 只需要路由器这类设备监听这个地址就可以了
- 不需要像是 ipv4 那样, 所有设备都来监听
IPv6中常用的一些多播地址:
- ff02::1 - 所有节点多播地址 (等同于IPv4的广播)
- ff02::2 - 所有路由器多播地址
- ff02::1:2 - 所有DHCPv6服务器和中继代理的多播地址
这种设计更高效,因为:
- 避免了不必要的网络 广播风暴 Broadcast storm
- 可以针对特定的服务群组进行定向多播
- 提高了网络的安全性和可控性
IPv6 的书写
4 个 hex number 为一组, 一共 8 组
- 每一组 hex numbers 里, 如果开头是 0, 开头的 0 可以省略
- 如果一组 hex numbers 全是 0, 整个组都可以省略 → 简单来说就是 0 可以被省略
例子:
2001:0db8:6ffa:0000:0000:00ab:98bf:070a- 省略 0:
2001:0db8:6ffa:::ab:98bf:070a - 上面一共省略了 两组 全是 0 的 hex number, 所以出现了三个冒号相连的情况, 中间的冒号也可以省略
- 最终书写:
2001:0db8:6ffa::ab:98bf:070a
IPv4 IPv6 之间是怎么沟通的?
不能直接沟通
- 一个只支持 IPv4 的设备是不能直接访问只有 IPv6 的机器上的 content 的
- 只有 IPv4 的机器和只有 IPv6 的机器不能直接沟通
为什么 IPv4 机器不懂 IPv6 机器?
- 简单来说, 就是协议不同, 数据包也不同了
- 硬件不一定能接收这个数据包, 软件也不一定能够理解这个数据包
- 要是按 ipv4 的规范去解析 ipv6 的数据包, 那当然解析不了了
Note
Protocol Differences Are More Than Just Address Length
An IPv4-only device doesn’t simply lack an IPv6 address; it lacks the necessary software and, sometimes, hardware support to understand and process IPv6 packets
protocol 上:
- 两种 protocol 的数据包结构不一样, header 不一样
- 只有 IPv4 地址的机器发不出 IPv6 的数据包; 包头里, IPv4 的源地址不符合 IPv6 的规范 firmware 和 OS:
- 大部分的 OS 都支持 dual stack
- 对于不支持的要升级 硬件上:
- 现在大部分的设备都支持两种协议
- 老的设备可能不支持 IPv6; 某些特定的新的设备可能不支持 IPv4 其他 protocol:
- IPv6 有 IPSec 和 SLAAC, 只支持 IPv4 的机器没有这些功能
实际上是怎么实现沟通的?
NAT64 是其中一种方法:
- Network Address Translation 64
- 用 gateway 网关的形式来转换 IPv4 和 IPv6 的请求 IP tunneling:
- 在 IPv4 的包上封一层 IPv6 的头
- IPSec 使用了 IP tunneling
为什么 server 要用 IPv6?
- 现在开始有越来越多机器是 IPv6 only; server 支持 IPv6 的话就能够让这些机器直接和 server 沟通
- 现在大部分的 server 都是 IPv6(shared address) 和 IPv6(dedicated address), client 在和 server 沟通的时候用 IPv6 会有更好的 performance, 因为不用经过 NAT, 少了一层 translation layer
- when it comes to set up, 实际上 IPv6 的 setup 也会更方便, 因为不用 NAT 了; 特别是在 home server 的场景
- 对于 autonomous system (AS) - 需要很多地址的场景 - IPv4 比 IPv6 贵
如何从 IPv4 升级到 IPv6?
- 看自己的 ISP 是否支持 IPv6 → 是否能被分配到 IPv6 地址
- 看 router 是否支持 IPv6, 是否 enable
- 看设备 (硬件、软件、固件) 是否支持, 是否 enable
DHCP - 分配 IP
首先有个 DHCP server, 这个 server 负责 提供、分配 ip 地址.
- router / switch 可以作为 DHCP server (如家庭环境, 路由器就是个 dhcp server)
- 有大量设备的环境, 更好的方法是 set up 一个 dedicated DHCP server
Note
DHCP 基于 UDP 是个 connectionless 的协议
不需要 connect, 直接发就是了
→ 基于 UDP, 说明 DHCP 在 传输层之上, 是个 应用层 的协议
工作原理 DORA
- 一个新的客户端加入网络 (手机连上wifi), 这个客户端会 广播 发送一个 DHCP Discover 的数据包, 用来寻找可用的 DHCP 服务器; 广播的数据包中, 源地址为 0.0.0.0, 目标地址为 255.255.255.255
- DHCP 服务器收到 discover 数据包过后, 会检查自己可用的 IP 池, 以 广播或单播 的形式向客户端提供 一个(不是多个) 可用的 IP 和其他网络配置 (子网掩码, dns 服务器, default gateway address, lease time 等)
- 客户端 收到服务端 DHCP offer 过后, 如果确认使用这个 IP, 会向 dhcp server 发送一个 dhcp request 的请求, 表明接收 offer; 这个请求仍然是 广播, 因为可能存在多个 DHCP 服务器, 需要让每个服务器都知道
- dhcp server 会再发一个 dhcp ack, 正式把 ip 分配给这个客户端设备
Client --> [DHCP DISCOVER packet] --> Server
Client <-- [DHCP OFFER packet] <-- Server
Client --> [DHCP REQUEST packet] --> Server
Client <-- [DHCP ACK packet] <-- Server
Note
client discovery 的时候, broadcast 的地址是 255.255.255.255
OFFER 可以是广播也可以是单播, 由 client 决定
Note
在设备接入一个子网的时候, 通过 DHCP 被分配一个 private ip 地址; 除了 ip 地址以外, 还会得到一个 dns 服务器的地址.
路由器在 DHCP 中的作用
- 在一个没有专门的 DHCP 服务器, 路由器通常就是 DHCP 服务器;
- 如果子网里存在 DHCP 服务器, 那路由器不参与这个过程;
- 如果 DHCP 服务器在另一个子网里, 那 路由器 的作用是 DHCP relay
DHCP relay
目的:
- 避免在有多个子网的情况下, 每个子网都需要部署一个 DHCP 服务器;
- 多个子网可以共享一个 DHCP 服务器 流程:
- 路由器接收到客户端的 DHCP discovery 的时候, 会把这个 广播 的信号以 单播 的形式发给 DHCP 服务器
IP 地址是有 lease time 的, 需要续租
- IP 地址租期还剩 50% 的时候, 客户端会发送个 单播 的 DHCP request 给 DHCP 服务器
- 服务器如果回复了 DHCP ack, 那就续租成功了, 重新开始倒计时
- 如果服务器没回复, 那在租期还剩 12.5% 的时候, 客户端又会发一次 DHCP request
- 服务器还没回复, 那时间到了, IP 地址就过期了
- 客户端就得重新 DORA 了
DHCP 使用场景
- 设备连接到 子网 的时候, immediately
- 设备从 DHCP server 获取到的 DHCP info 会过期, 在消息要过期的时候会重新获取一次, periodically (这时候就不需要最开始的 broadcast 了, 直接都是 unicast)
IPv6 的地址是怎么确定的
首先, IPv6 地址还是可以通过 DHCP server 下发, 或是手动配置 IPv6 地址还可以由设备 自己生成
StateLess Address AutoConfig SLAAC
- 设备接入网络过后, 会先发送一个 路由器请求 (router solicitation)
- 路由器会返回一个 IPv6 地址的 前64位 (router advertisement)
- 设备根据 自己的设备信息(MAC) 生成 IPv6 地址的后64位 (设备自己生成)
怎么样确保设备 自己生成 的地址和其他设备不冲突呢? 通过发生 邻居请求消息 neighbor solicitation, 是个 ICMP(network layer) 的消息
- 设备生成好 IPv6 地址过后, 广播一个 ICMPv6 的消息, 包含自己生成的 IPv6 地址
- 如果收到回复, 代表这个地址被其他设备使用了
- 设备重新生成地址, 怎么样重新再生成, 就先不学了
- 如果没有回复, 代表没有设备在使用这个地址, 地址可以使用
Note
does not require a central server (as compared to DHCP which needs a DHCP server).
→ how linux works
IPv6 没有广播, 那 router solicitation 是怎么发的?
设备(新加入网络) 路由器
| |
|---RS----------------->|
| src: :: |
| dst: ff02::2 |
| |
|<--RA------------------|
| src: fe80::router |
| dst: ff02::1 |
ff02::2是 IPv6 中预定义的 组播地址 multicast- 网络上的所有路由器都会自动加入这个 组
- 只有路由器会处理这个组播消息
特殊的 ip 地址
IPv4
127.0.0.1:
- local host
- used by a computer to refer to itself 所有的 host bits 都是 0:
- 每个子网的 host 0 都是被 reserved 的
- 表示这个网络本身 (这个是被 reserved 来表示子网的, 不会被分配给哪个设备) 255.255.255.255 (所有的 host bits 都是 1):
- broadcast
- a place to route message to all devices on the network
- 用途: 在电脑通过 DHCP 获取 IP 地址的时候, 电脑不知道自己的 IP、子网掩码、default gateway, 啥都不知道的情况下, 就向 255.255.255.255 发个广播 0.0.0.0 (全是0):
- 未知地址或任意地址
- 在设备还未获取到 IP 地址的时候, DHCP 请求的源 IP 地址就是 0.0.0.0
IPv6
::1
- localhost
Note
IPv6 没有 broadcast 地址!!
IPv6 用的是 multicast
特殊的子网
IPv4
10.0.0.0/8 172.16.0.0/12 192.168.0.0/16
- private network 为什么 LAN 局域网的 IP 都是这个?
- 历史原因, 这个字段就是给 private network 预留的
公网和内网都隔离了, 内网里不应该用什么 IP 都可以吗
- 从技术上来说, 应该是的, 内网里想用什么地址里都可以
- 在配置 router 的时候, router 要怎么样知道哪个是内网呢? 应该是通过配置实现的; 在配置的时候, router 是否会允许 除了上面那三个规定好的 private network 以外的其他网络号?
- 即便 router 允许的情况下, 如果内网里的一个设备用的地址在公网上也存在的话, router 又应该要怎么知道一个数据包是应该发到哪个地址呢?
- 其中估计可是能够通过配置实现的, 但这个配置估计复杂得很
IPv6 的 cast
单播 unicast
组播 multicast
- 把信息发给 子网 里的 一组 IP, 而不是 所有IP 任播
同一个 IP 不同子网掩码?
是否可以给两个不同的电脑分配一个同样的 IP 地址, 但是是不同的 subnet mask?
- 不可以
- IP routing 的本质工作原理是基于 IP 地址本身, 而不依赖于 子网掩码
- 子网掩码只是 定义子网 的一种方式
- router 在 routing 的时候只能看到 IP 地址
- 两个 IP 完全一样, ARP 也不知道咋办 比如, 两台电脑的 IP 分别是: 123.123.123.123/16, 123.123.123.123/24
- 对应的两个子网就是 123.123.0.0, 123.123.123.0
- 子网 123.123.123.0 实际上是 123.123.0.0 的一个子网
- 所以 IP packet 在进入大的子网 123.123.0.0 的时候做 ARP, 是会得到多个 response 的
- router 就不知道要把 packet 转发到哪里了
ICMP
internet control message protocol
- 只是 网络层 的协议, 上面没有 UPD TCP 了
- connectionless protocol
- 发数据包只是发到 IP 地址 上, 没有 port 的概念 换个角度看问题:
- 从数据包的角度来看, 对于一个 IP packet 来说, tcp/udp 的信息都是 payload,
- IP 协议 作为一个协议, 主要关心的是 header; IP 协议不关心 payload 里面是个啥, 反正都是上层传下来的数据
- 那么这个思路放到 ICMP 也是一样, 它只定义个 header, 不关心 payload 里面是个啥
- ping 一个 ip 的时候, 说不定发的 ICMP 信息里, payload 都是空的
应用:
- ICMP 的主要作用是 error report, 如果一个数据包太大了被 receiver 拒绝了的话, receiver 会发个 ICMP 的信息回去
- ICMP 也可以用于 network diagnostics, 比如 traceroute 和 ping
- 在 ping 一个域名的时候, 发的就是 ICMP 的数据包
ping
ping 干啥的
- 检查一个 ip 地址是否可以到达 (reachable), 并判断 ttl 和 rtt 工作原理
- 发送 icmp 的包, 这个包是个 echo request
traceroute
traceroute 干啥的
- 顾名思义, trace 一个数据包在网络上的 route
- → 追踪一个数据包从 sender 到 receiver 的路径; 这个路径指的是数据包经过的 ip 地址 工作原理
- 给目标 ip 发送数据包, 数据包的 ttl 从 1 开始, 递增到达到目标地址, 或者达到最大跳数
- 为啥要这样递增? 这里利用的是 数据包 ttl 到达 0之后, 路由器会回复一个 time exceeded message 的特性 traceroute 返回结果里的三个星号儿是啥意思
- 这是没有 time exceeded message 返回的意思
- 某些路由器配置了不返回这个信息 (为了提高安全性, 防止被 ddos 啥的)
- 网络延迟或者丢包
- 主机不可达
- 三个星号儿是默认会探测 3 次, 即发 3 次数据包, 3 次都没响应就增加 ttl 到下一跳
traceroute -q 5 google.com这样会有五个星号儿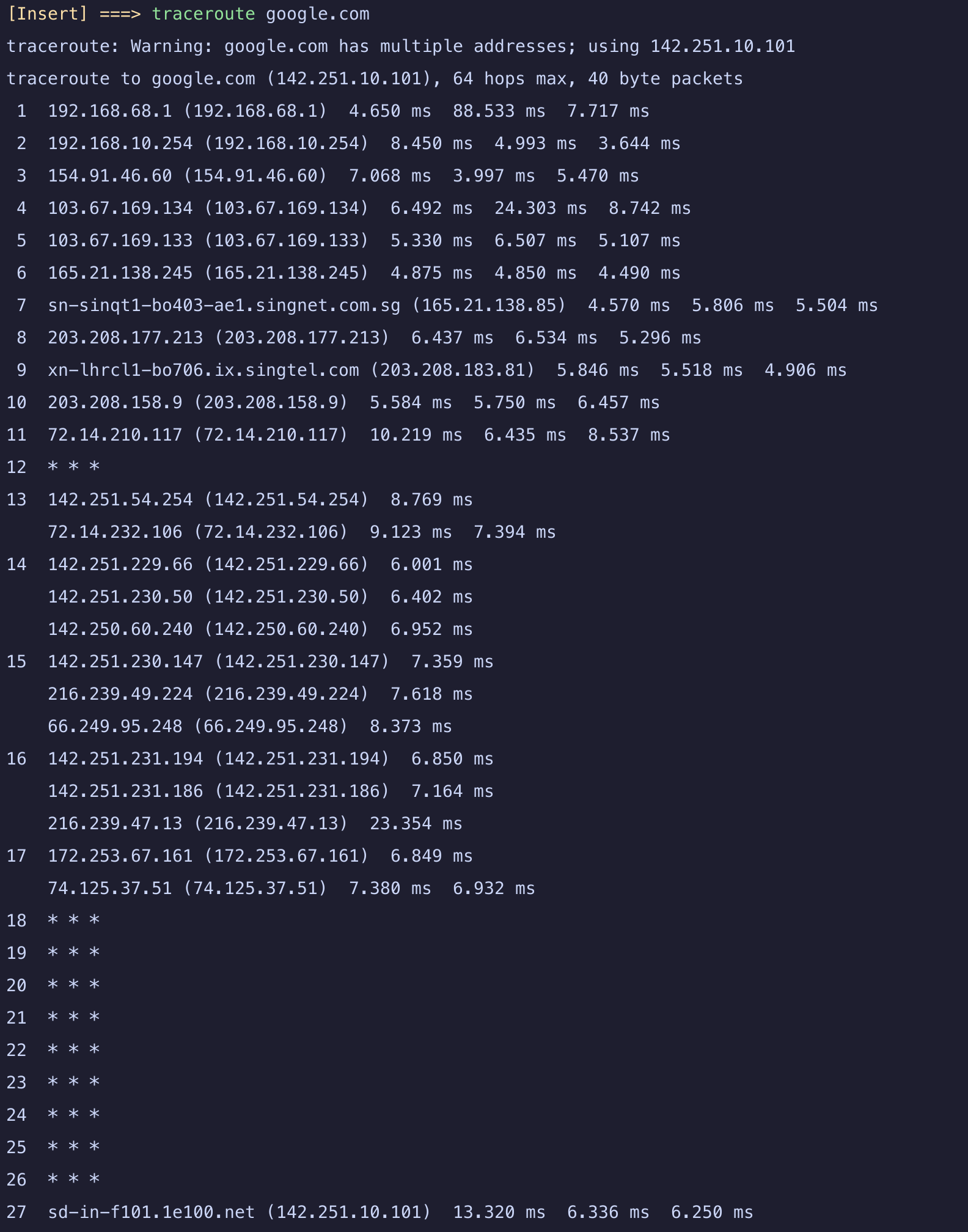
ICMP 和 DDoS
cloudflare echo request flood
- attacker 使劲发 echo request 的 ICMP 包, server 回复不过来了 smurf
- attacher 发个带有 spoofed source ip 的 icmp 数据包, 冒充某个 client 去给 server 使劲发 echo request
网络接口层 (第1, 2 层)
- 以太网: Wi-Fi也是以太网; 以太网有分有线以太网和无线以太网
- 以太网本身是个局域网LAN
- MAC: media access control 地址
- 每个以太网里的设备都有个唯一的MAC
- 以太网的传输以data frame的形式进行, 每个data frame包含:
- 源MAC地址
- 目标MAC地址
- 数据
- 帧校验序列
ARP (Address Resolution Protocol)
什么是 MAC地址?
- 网络中每台设备都有自己唯一的标识, 这个标识就是 MAC地址
- 是网络设备制造商烧录在硬件上的
- MAC地址是 12个16进制数, 2个一组, 6组, 如
00:1A:2B:3C:4D:5E - 由 IEEE 来管理, 实现全球唯一
Note
MAC 地址, 用于同一个 物理层面 的设备的通信(设备“直连”)
IP 地址, 用于 “没有直连” 的设备之间的通信
ARP (link layer protocol)
是个把 IP 地址转换为 MAC 的协议, 是个 link layer protocol, 用于在 同在一个 physical layer 的主机之间传输信息
工作原理:
- 主机A要找主机B的MAC, 主机A先检查缓存
- 缓存没有就在网络里发 广播 (ARP 请求), 包含自己的 IP 和 MAC 地址, 以及 主机B 的 IP 地址
(除了 broadcast frame 以外, 本身一个硬件只会监听发给自己 MAC 地址的 data frame)
(broadcast frame 上的 目标 mac 地址:
ff:ff:ff:ff:ff:ff) - 主机B收到广播后, 会 单播 一个 ARP响应 给主机A, 包含主机B 的 MAC地址
- 主机A收到之后把主机B 的 MAC 地址存到缓存里
注意:
- ARP 是 无连接 的协议, 不需要 主机A 和 主机B 进行连接就可以解析到 MAC 地址
- ARP 只在局域网里有效, 局域网以外的要依赖 路由器
- ARP 有安全性问题, 会有 ARP欺骗攻击, 数据包会被篡改
ARP caching
- 在 sender 通过 APR, 从 IP 获取到 receiver 的 MAC 之后, 会把这个结果缓存起来, 缓存时间可能是几分钟到几小时
会出现一种情况:
- sender 第一次发消息之后, 获取了 receiver 的 mac 地址并且缓存里起来
- 在第二次发消息前, receiver 从自己的 LAN 里断开了, receiver 原来在这个 LAN 里被分配的 IP 地址, 被重新分配给了另一台设备
- sender 第二次发消息的时候, 从缓存里拿到了 IP 对应的 MAC 地址, 但是现在的 MAC 地址对应的设备已经离开子网了
- 这时候再发消息, 发到 receiver 的子网里之后却找不到对应的 MAC 地址
- 这就出现了 communication failure sender 怎么知道出现了 communication failure?
- 如果是 tcp, 一直没有 receiver 回应的 ack 的话, 就知道丢包了
- 在 network stack 里, 可能有某些机制会给 sender 返回一个 unreachable 之类的 error message
ARP 全流程
- 一个 IP packet 从 网络层传到 data link 层
- ARP module 去 look up ARP table
- 如果 table 里没有这个 IP 对应的 ethernet address (MAC address), 就封装不了 ethernet frame. 此时会发生两件事
- IP packet 会被 queued
- ARP module 会 广播 一个 ARP request
---------------------------------------
|Sender IP Address 223.1.2.1 |
|Sender Enet Address 08-00-39-00-2F-C3|
---------------------------------------
|Target IP Address 223.1.2.2 |
|Target Enet Address <blank> |
---------------------------------------
TABLE 2. Example ARP Request
- 网络里的每个机器都在监听 广播信息, 他们收到这条信息之后, ARP module 会判断这个 ARP request 要找的 IP 是不是自己的 IP
- 如果是自己的 IP, ARP module 会回复一个 ARP response; 和上面的 ARP request 一样, 不过 sender 变成自己, target 变成 request 里的 sender
- 最开始的 sender 收到这个 ARP response 之后, 会更新自己的 lookup table
- 刚刚被 queued 起来的 IP packet 现在可以封装上 ethernet frame 了
注意:
- 一个电脑会为自己的每个网卡都各自维护一个 ARP table
- 如果一个 packet 发不出去, IP 层是不知道是 ethernet broken 还是 ARP 失败了
ARP 欺骗攻击
- 因为 ARP 请求 是以广播的形式发出去的, 局域网里的所有设备都会收到; 攻击者就可以 伪造 ARP 响应, 把自己的 MAC地址发给请求者 防护措施
- 用 ARP 静态表把 MAC 地址 和 IP 地址 一一绑定
- 在应用层使用 HTTPS 等 加密 协议, 即便发生了数据窃取, 数据也很难被解读
ARP 不在一个局域网的情况
- 如果 主机B的 IP 不是同一个局域网的, 主机A有主机B的IP, 主机A是可以知道的 主机 B 是不是在同一个子网
- 主机A知道主机B不是自己这个局域网的过后, 就会 广播 去找 默认网关 (通常是 路由器) 的 MAC 地址 (还是普通的 ARP 那套, 不过现在要找的是默认网关的 MAC 地址) → 注意, 这时候主机A直接就找路由器的MAC地址, 所以发广播的时候, ARP 请求的 destination IP 直接就是路由器的IP了 → 这时候数据包的内容是: source IP、source MAC, destination IP (默认网关的IP), destination MAC (广播mac地址)
- 然后路由器又 单播 自己的MAC地址给主机A
- 路由器之间是通过IP地址来传输的, 不需要MAC地址
- 不断地跳转到 最后一跳 的路由器后, 这个路由器又会用 ARP 广播IP地址, 最后主机B返回
Note
注意: 路由器不会转发 ARP 请求, ARP 是指在子网内部的!!
Note
“Remember that ARP applies only to machines on local subnets. To reach destinations outside your subnet, your host sends the packet to the router, and it’s someone else’s problem after that. Of course, your host still needs to know that MAC address for the router, and it can use ARP to find it.”
→ how linux works.
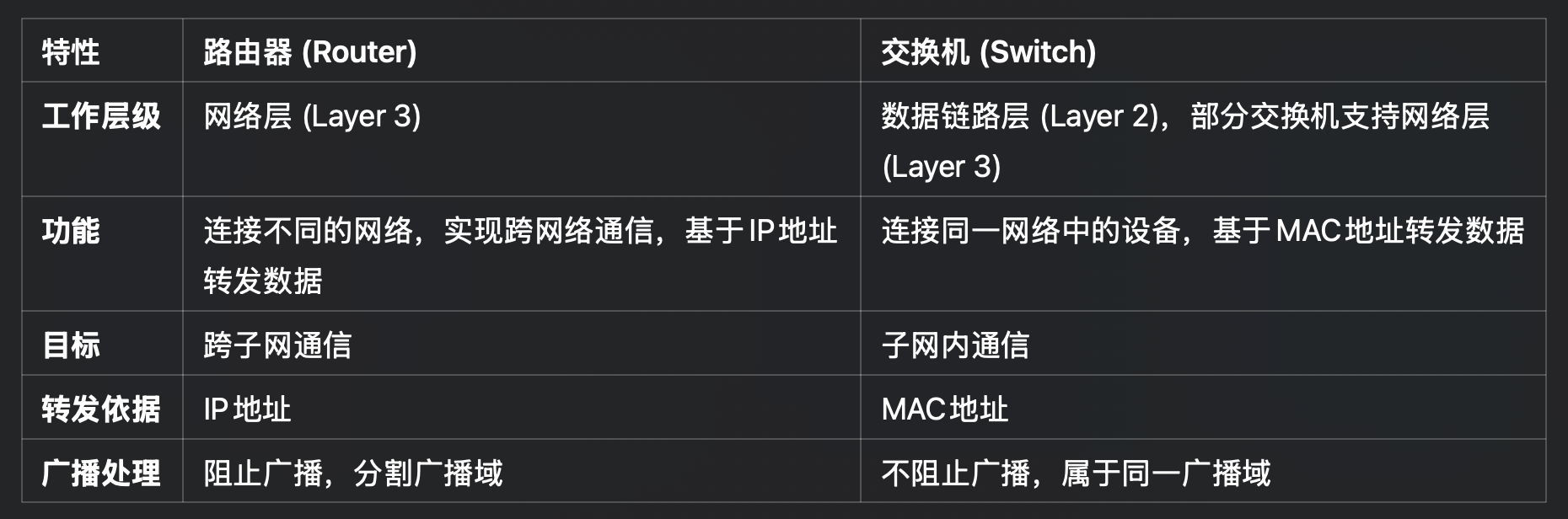
路由器 和 交换机
图源 gpt, 待 fact check
路由器
- 路由器负责在 不同的网络之间 转发数据包, 主要用于实现 跨子网通信
- 一个子网要连接到外网 (互联网), 路由器是必需的
- 查路由表决定数据包的转发路径
- 隔离广播域: 路由器可以接入多个子网, 但子网之间的广播消息不会被路由器转发
交换机
- 交换机连接 子网内部 的设备, 在子网内部中转发数据包
- 有 二层交换机 和 三层交换机 的分别
- 二层: 根据 MAC 地址进行数据包转发
- 三层: 根据 IP 进行数据包转发
- 二层交换机维护一个 CAM 表来进行转发:
- 要发送的 MAC 地址 → 这个 MAC 地址应该被转发到的物理端口
- 这个表的工作原理很简单, 具体可以看下面链接的 cloudflare blog
- credit - cloudflare

- 交换机扩展性极强, 交换机可以随意级联
one stupid example of switch’s use case
- 有两台设备要相互通信, 那就要把他们分别连接到同一个 switch 上
- 他们分别给这个 switch 发消息, switch 进行数据包的转发
交换机与 ARP
岁寒 假设局域网中一台 ip 为 192.168.1.2 的电脑(插在交换机接口 1 上)希望打开 192.168.1.3 这台服务器(插在交换机接口 2 上)上的网页,就会发生如下事情:
- 192.168.1.2 向局域网发出一个 ARP 包,询问拥有 192.168.1.3 这个 ip 的计算机的 MAC 地址,假设为 AA:BB:CC:DD:EE:FF
- 将 TCP 数据包放在 IP 数据包的内部,再将 IP 数据包放在 MAC帧 内部,通过 1 口将 MAC帧 发给了交换机
- 交换机拿到数据后,并不知道 AA:BB:CC:DD:EE:FF 这个 MAC 地址的设备插在自己的哪一个网口上,于是将这个 MAC帧 发送到所有口上,包括 1 口
- 应该不会包括 1 口, 看 cloudflare 这里写的:
- → It forwards Computer A’s message to all other computers on the network (except Computer A); this is known as “flooding”
- 2 口回应了,这时交换机就完成了第一次的自学习:AA:BB:CC:DD:EE:FF 这个 MAC 地址的设备插在自己的 2 口上,下次再转发就只发给 2 口就行了
- 交换机会自己维护一个 MAC地址 - 物理接口 对应关系的缓存表,并在一定时间内刷新这张表,重新缓存
路由器之间的转发
==对于不在同一个子网的路由器之间, 是通过 路由表 来发送到下一跳的, ARP 的原理是在 子网 中 发广播, 只能用在 同个子网 里== 路由器之间的转发是通过 查路由表 的方式来实现的, 具体在这就不展开了
- 每一次路由器转发的时候, 都会更新mac地址
对 MAC 地址更深层的理解:
- 本身 MAC 地址是在 data link layer 的概念
- MAC 地址只在同一个局域网或者同一个物理链路中有意义
- 超越了这个 物理界限 传输, 就需要 网络层 的协助, 也就是 IP地址.
路由表
(路由器怎么知道这个目标IP应该发到哪? 路由表!)
- 每个电脑、路由器都会存一个路由表, 路由表长这样:
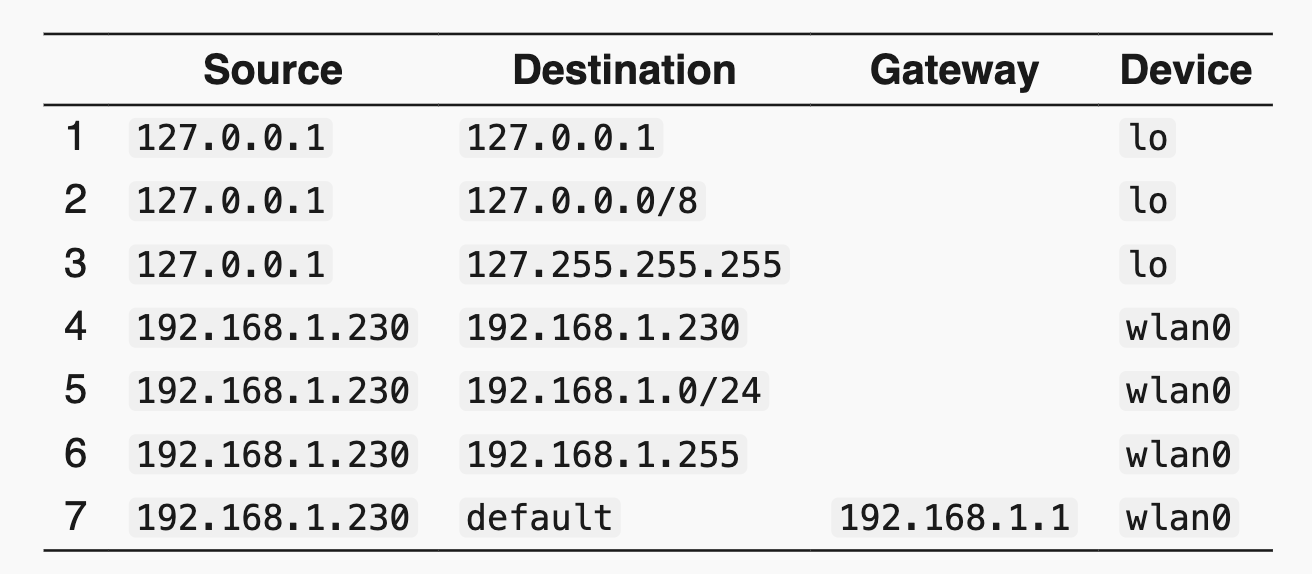
- 在发送 IP packet 之前会先查表
- 如果要发送的 IP packet 的 目标 IP 地址 不在 路由表 上, 就会发给 第7行 的 default, 是个 gateway, 也就是这个子网的 router
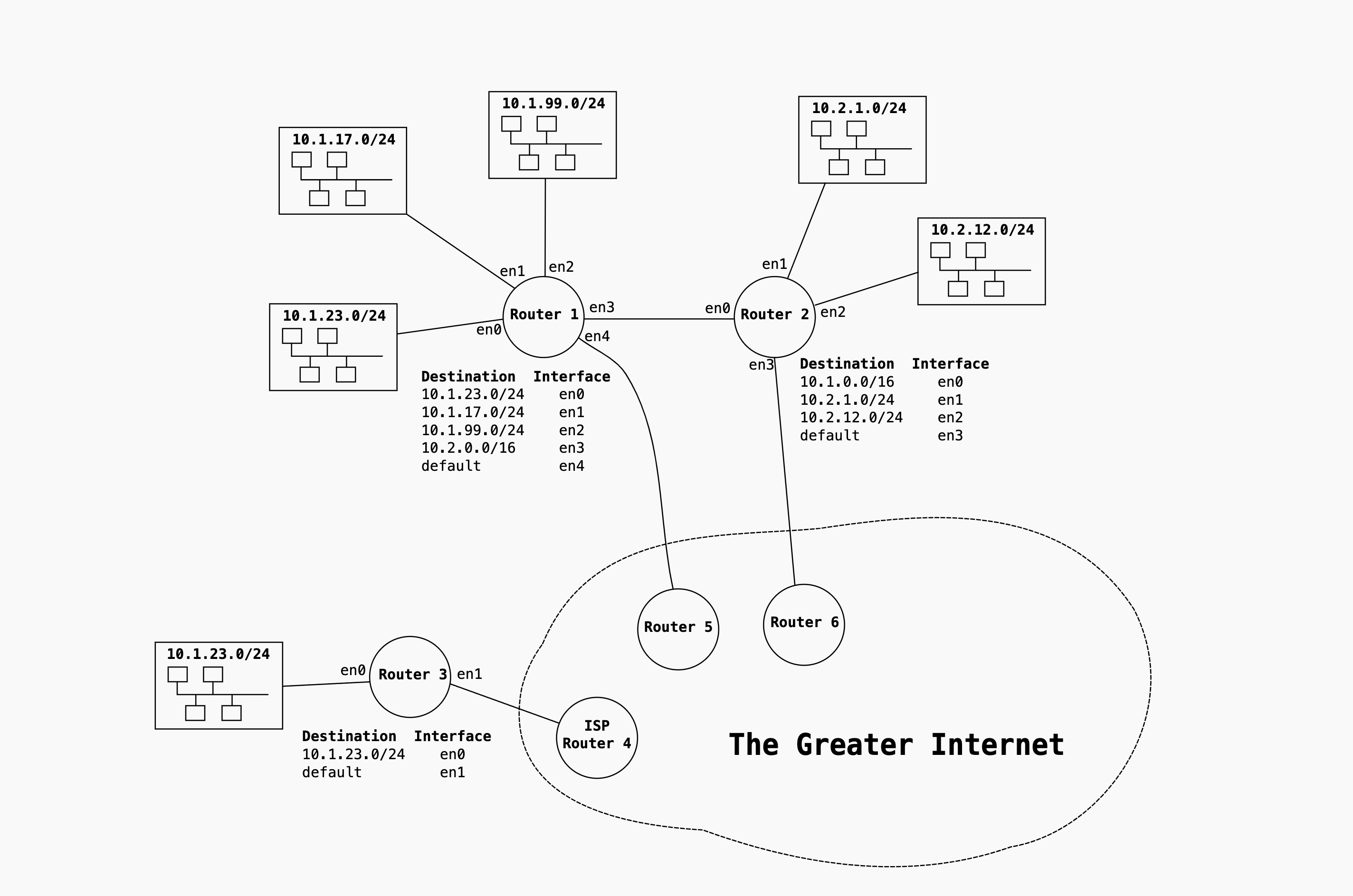
Note
一个 router 可以连接多个 subnet, 这个 router 在每个 subnet 都有一个 IP 地址.
下面这张图, router1 连接了 3 个 subnet, 在每个 subnet 都有个自己的 IP 地址
BGP broader gateway protocol
- 应用层 协议, 基于 TCP
- 用来决定 数据包 在 router 之间被转发的 most optimal route 感觉目前知道这个东西就行了, 不需要知道具体怎么工作的
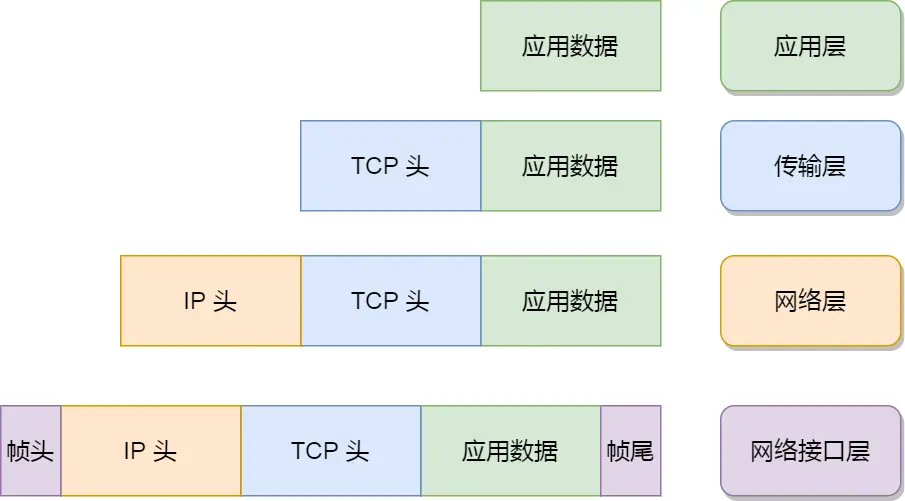
数据包里都有些啥
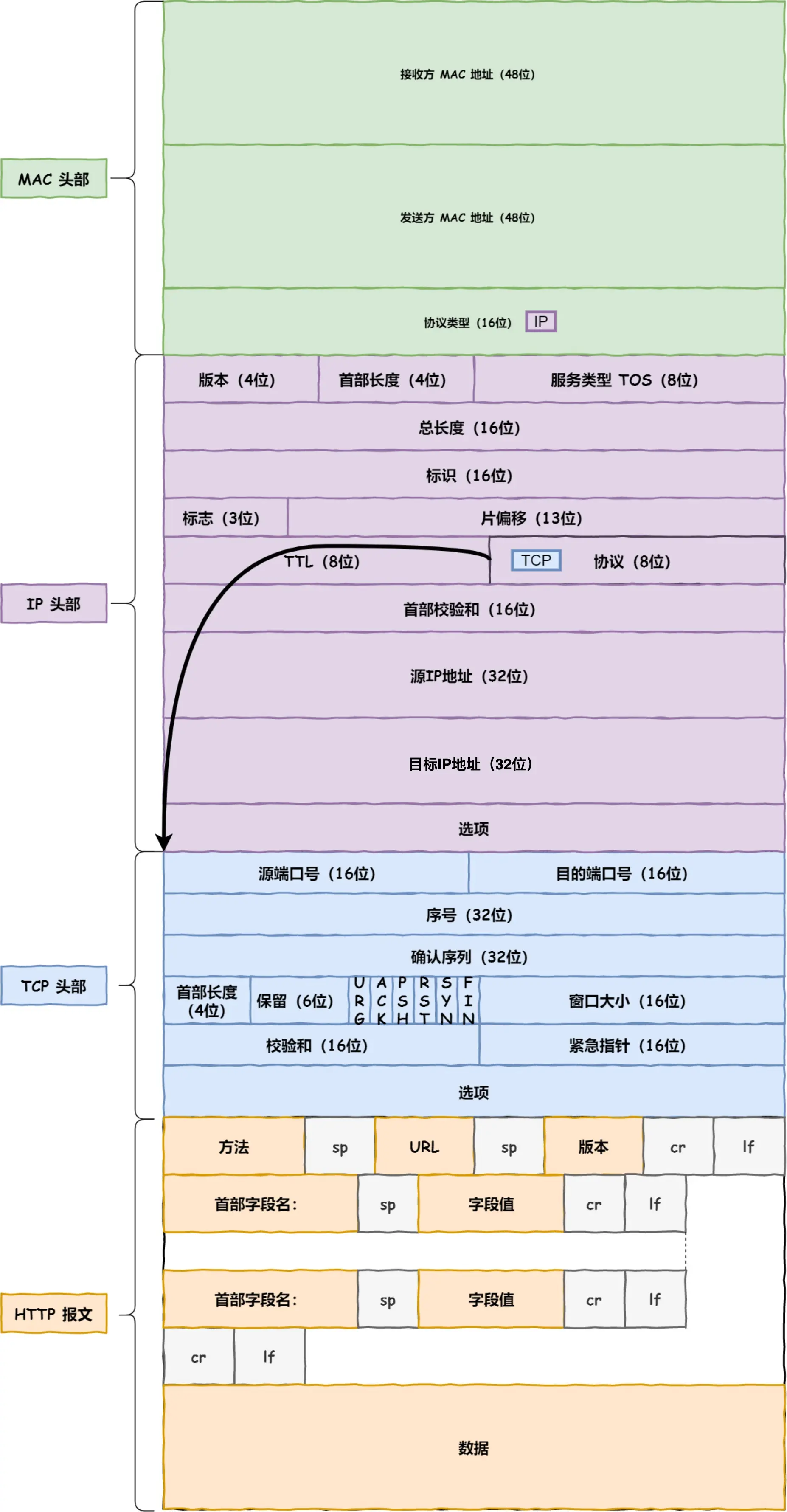
其他
url 和 uri
URL:
- uniform resource locator URI:
- uniform resource identifier
- URI 是一种字符串,用于标识互联网上的资源。它可以分为两种主要类型:
- URL(统一资源定位符):它不仅标识资源,还提供了资源的访问方法(例如,通过 HTTP 协议)。
- URN(统一资源名称):它标识资源但不提供如何访问该资源的信息。
- URI 例子:
- ldap://[2001:db8::7]/c=GB?objectClass?one
- mailto:[email protected]
- news:comp.infosystems.www.servers.unix
- tel:+1-816-555-1212
- telnet://192.0.2.16:80/
- urn:oasis:names:specification:docbook:dtd:xml:4.1.2
URL 是 URI 的子集
URI 用字符串标识某一互联网资源,而 URL 表示资源的地点(互联网上所处的位置)。可见 URL 是 URI 的子集。→ 图解 http
firewall
是什么, 干什么
通常是个 router, 接收、转发消息
- 会把一些消息转发, 一些消息拦截
- 比如说: router 会把所有 port 80 的 http 请求都进行转发, 但会拦截其他 port 的 incoming traffic 流量
- router 把数据包拦截的时候, 可以选择 do it silently, 也可以给 sender 回一个 “destination unreachable”
Network Address Translation NAT
场景:
- 假设有个组织从 ISP 那里拿来了一个网络号 68.123.0.0/16
- 这个子网下面可以有 2^16 = 65,536 这么多个 主机
- 但是假设还是不够怎么办?
- → NAT
Note
简单来说, NAT 把 内网 里的每个 ip 都映射成了个 公网 ip + port
NAT 工作流程
- 内网的 host 想要给外网发 internet packet, 这个 packet 被发到 router
- router 拦截 packet, 并且是由 router 来 determine the destination of the connection, and opens its own connection to the destination (意思是, router 会用自己的外网 ip 和外网 host 建立连接)
- 外网 host 并不知道内网的 host source - how linux works 9.23
NAT 的映射是怎么实现的 (port forwarding)
- 内网里的 NAT 设备会先给 内网里的每个 IP 都建立一个映射; 根据 source IP:Port 做一个映射 (例如,192.168.1.10:端口号 → 203.0.113.1:新端口号)
- 内网1 设备A 发送数据包给另一个内网2 的设备B, 包含自己的内网 IP:Port 和 receiver 的 NAT(router) 的 IP:Port (设备A不知道设备B的内网地址, DNS lookup 只能找到 设备B 的 NAT 设备的IP)
- 设备 A 的 NAT 设备(router) 接收到这个数据包, 把 source IP:Port 改成自己的公网地址, 再发出去
- 数据包在网络上被转发的时候, source IP 是 设备A 的 NAT设备的IP, destination IP 是 设备B 的 NAT 设备的 IP
- 发到设备B的 NAT 设备后, NAT 设备里已经有了 公网 IP:Port 到 设备B 的映射, 根据这个映射转发给 设备 B
router 把子网里的设备都转换成公网里的 IP:Por t
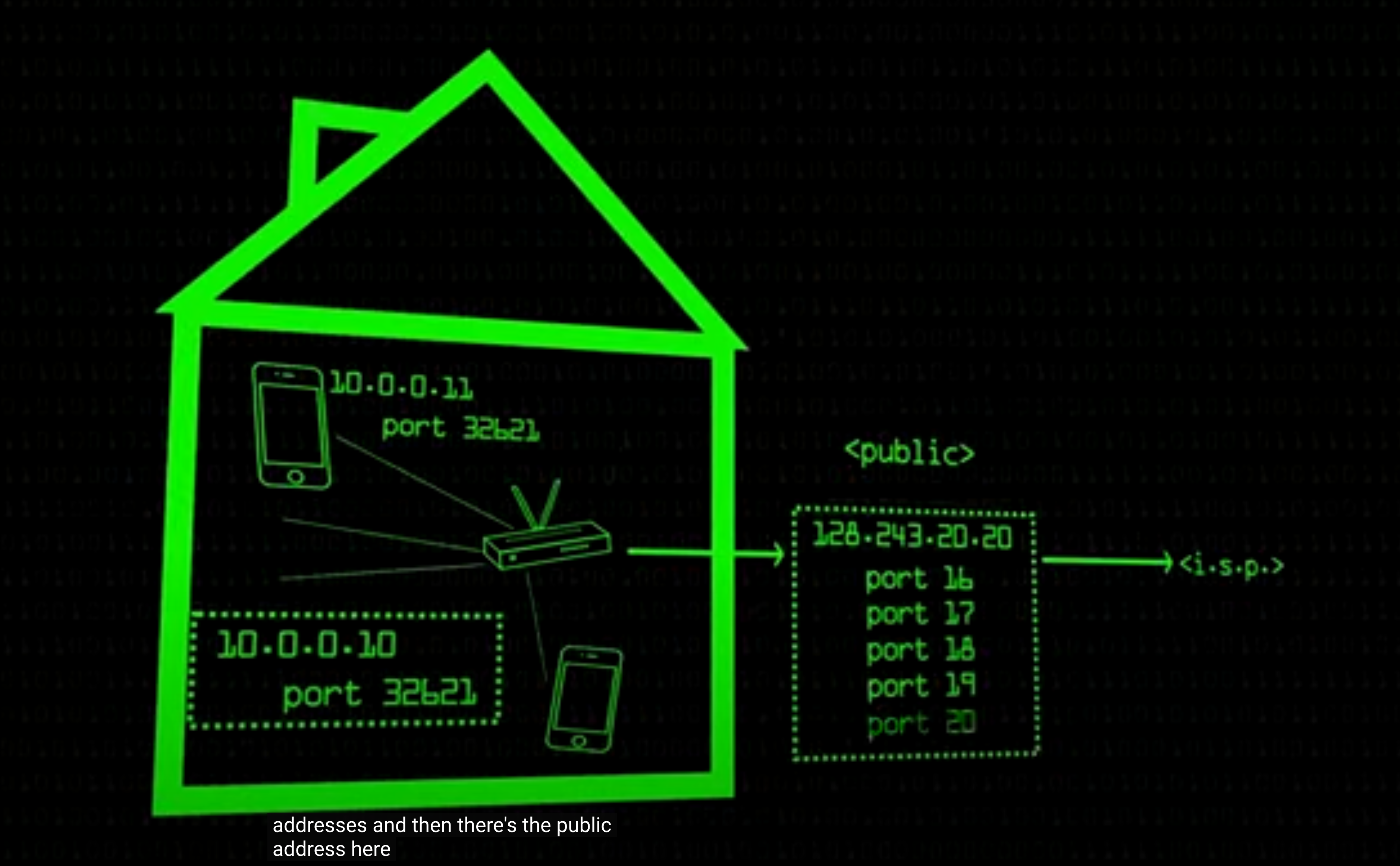
NAT 的好处
- 解决了 IPv4 地址干涸的问题 (address exhaustion)
- 内网的地址不会直接暴露到公网, 公网以外的设备一半不能直接给内网的设备发消息, 一定要经过 NAT; NAT 相当于是个 gateway, 提供了一定的安全性
NAT 的问题
- 有的 protocol 会被 NAT 给 disrupt. 比如 UDP , IPSec
- NAT 给 end to end encryption 增加难度 (影响连接, 不影响加密)
- NAT 导致很多 protocol 的实现都更加 complicated 了
- 这样的单一网关也是一个 single point of failure; 如果网关倒了, 那一整个子网都倒了
Note
注意, NAT 不只是简单的 forwarding, NAT 实际上是 intercept + transform.
内网的地址
10.0.0.0/8 172.16.0.0/12 192.168.0.0/16 -》 这些地址是有 Internet Engineering Task Force 专门给内网 private network 预留的
为啥要有 www 这个 subdomain? 有什么作用?
- 不同的 subdomain 用来管理 不同的服务
- 在互联网早期, www 主要是负责 万维网, 用来 serve web content; 也有 ftp 这个 subdomain, 用来提供 ftp 文件传输的服务
- 在互联网标准化的时候, RFC、IETF 啥的建议用 www 作为 web content 的 subdomain
- 到现在主要就是 convention 了, 没有一定要用 www 的道理
不过本身子域名的一个功能是进行 流量管理, www 这个 子域名 和其他子域名一样, 可以被用来 分发流量
端口
为什么协议要有固定端口?
- HTTP 是 80
- 共同协议, 简化请求, URL里不需要填端口, 就走默认端口
可以自定义端口吗
- 可以
- 但是可能会被 server 拒绝 connection
- 或者会被防火墙拦截
七层负载和四层负载
首先, 这里的 七层 和 四层 指的是在 OSI model 上的层 (Open System Interconnection). 流量分发的逻辑:
- 七层负载: 在第七层, 应用层, 主要是 HTTP 协议, 通常指通过 HTTP 请求进行负载均衡, 根据 url, cookies, header 进行流量分发 (在第七层进行流量分发)
- 比如说,
/image的请求全部都转发到处理图片的服务器上
- 比如说,
- 四层负载: 在第四层, 传输层, 主要是 TCP、UDP 协议; 基于第三层的 IP协议 进行流量分发 → 根据 IP地址和端口 进行流量分发
- 比如说, 发到
443端口的请求全部转发到 https 的服务器上
- 比如说, 发到
四层负载均衡只负责接收 IP 数据包, 不与客户端进行握手 (没有和客户端连接, 真正和客户端连接的还是后端 server)
- 主要工作是转发数据包, 建立一个转发的 mapping (实际上就是 NAT)
- 建立 mapping 需要五元素:
- source ip
- source port
- destination ip
- destination port
- protocol (tcp/udp)
NAT 的功能很简单, 有专门的硬件来完成 (NPU), 所以成本很低; 家用的路由器就是个 NAT device, 便宜得很
连接:
- 七层负载: 根据 应用层 的协议来进行流量分发, 说明在开始流量分发之前, tcp 连接就建立好了, 所以是 负载均衡器 和 客户端 进行连接, 负载均衡器进行 转发
- 四层负载: 根据 IP地址 进行流量分发, 在建立 tcp 连接前就分发了, 所以客户端和服务端直接进行 tcp连接, 但是负载均衡还是会在中间转发 TCP segments
优缺点:
- 四层负载更 高效, 只在 网络层和传输层, 不需要 应用层的解析, 适合对性能和低延迟要求高的场景
- 七层负载更 灵活, 流量分发的 粒度 更细致, 适合更 复杂的业务场景 (更大的开销)
测试环境泳道染色的常用实现方法就是通过七层负载
- url 或 header 中带上泳道标识
- nginx 等负载均衡器在应用层识别泳道标识
- 转发流量到特定的集群上