http 粘包
http 基于 tcp;
- 应用层的数据传到传输层之后, TCP 是不知道应用层数据的 message boundary的, 所有会产生 粘包 的问题 解决方法 → 在应用层里定义 message boundary:
- http request 用回车符、换行符作为header的边界
- content-length: 解决 request body 粘包的问题, content-length 作为body 的边界
http 缓存
强制缓存 (客户端的行为)
- 有一个固定的缓存时间, 如果缓存没过期, 客户端会直接读取缓存 → 是否使用缓存的决定权在客户端这边 虽然决定权在客户端, 但服务端也可以通过 cache control 这个 header 来限制:
- 浏览器请求服务端 → 服务端返回 header 里包含 cache-control 字段 → 浏览器要再次请求的时候, 先用cache-control字段计算是否过期
协商缓存 (客户端和服务端协商的行为)
- 核心: 客户端发送一个请求, 服务端来决定这个请求是否可以用缓存
- 请求的 status code 是304 → 服务端告诉客户端是否可以使用缓存 (协商缓存)
Note
协商缓存的时候, 客户端还是发了 http 请求
如何协商 → http 请求和返回中, 两种头部组合:
- if-modified-since 和 last-modified
- 第一次请求, 服务端 返回 header 里带上 last-modified的值, 告诉客户端这个资源上次修改是什么时候, 客户端缓存这些信息
- 第二次请求, 客户端请求头里带上 if-modified-since 的字段, 服务端对比, 看资源是否有修改, 然后决定返回 304 还是 200
- 这两个header里的内容都是时间戳 → 这种协议缓存是基于时间实现的
- etag 和 if-none-matched
- 第一次请求, 服务端 返回 header 里带上 etag 的值, 客户端缓存这个值
- 第二次请求, 客户端在请求头里 加上 if-none-matched: etag 的字段; 客户端对比这个 etag 对应的资源是否有变化, 然后决定返回 304 还是 200
- etag
- entity tag
- 服务端生成的, 用来标识某个资源的某个版本, 可以是哈希值, 可以是其他方法生成的; 资源内容改变的时候, 对应的etag也会改变
- etag / if-none-modified 的协议缓存是基于唯一标识实现的
- (etag比时间更可靠, 时间可能存在的问题: 时间会被篡改, 时间有精度, 服务端的时间可能不准确, 或者文件的内容没变但是文件的最近修改时间变了)
- 因此 etag 的优先级比 if-modified-since 更高
协商缓存 和 强制缓存
- 强制缓存是浏览器自己决定的, 优先级高于协商缓存
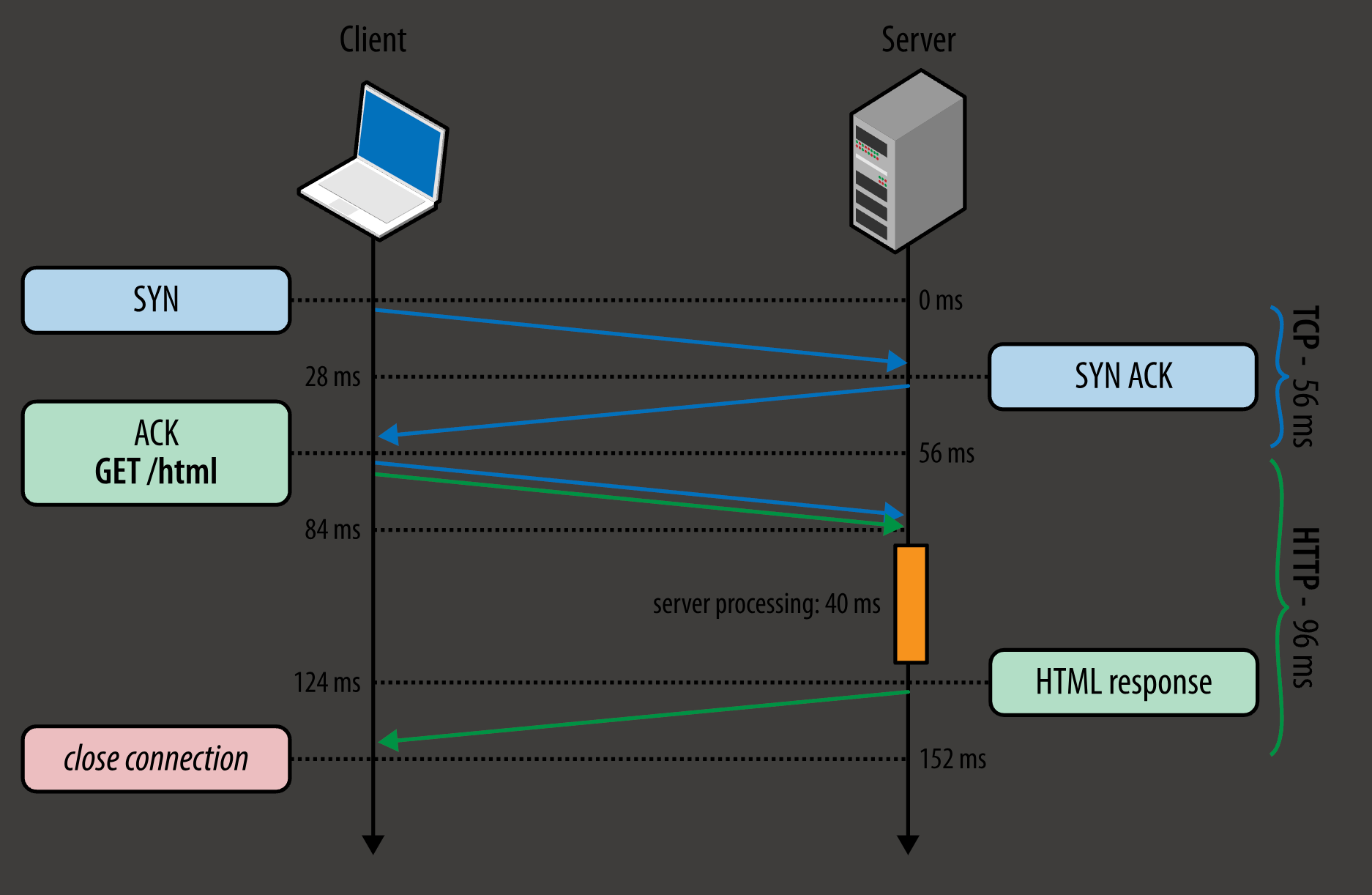
http RTT
- TCP 连接: 3次握手 1 个 RTT
- 发送、接收请求: 1 RTT
- 总共需要 2 个 RTT 才能完成一次 连接和请求
http 的 keep-alive 和 tcp 的 keep-alive
http keep alive
- 目的:
- 在 http 请求的过程中, 保持 tcp 的连接, 使得一个 tcp 连接下能发送多个 http 请求
- 减少 tcp 握手
- 实现: 是在 http 的层面, 也就是应用层实现的
- 服务器配置 keep alive time, 如果这段时间内没有任何请求, 就会关闭连接
- 这个 keep alive time 也是可以通过 http header 来协商约定的
- note:
- http keep alive 的机制在 http 1.0 和 1.1 里比较重要
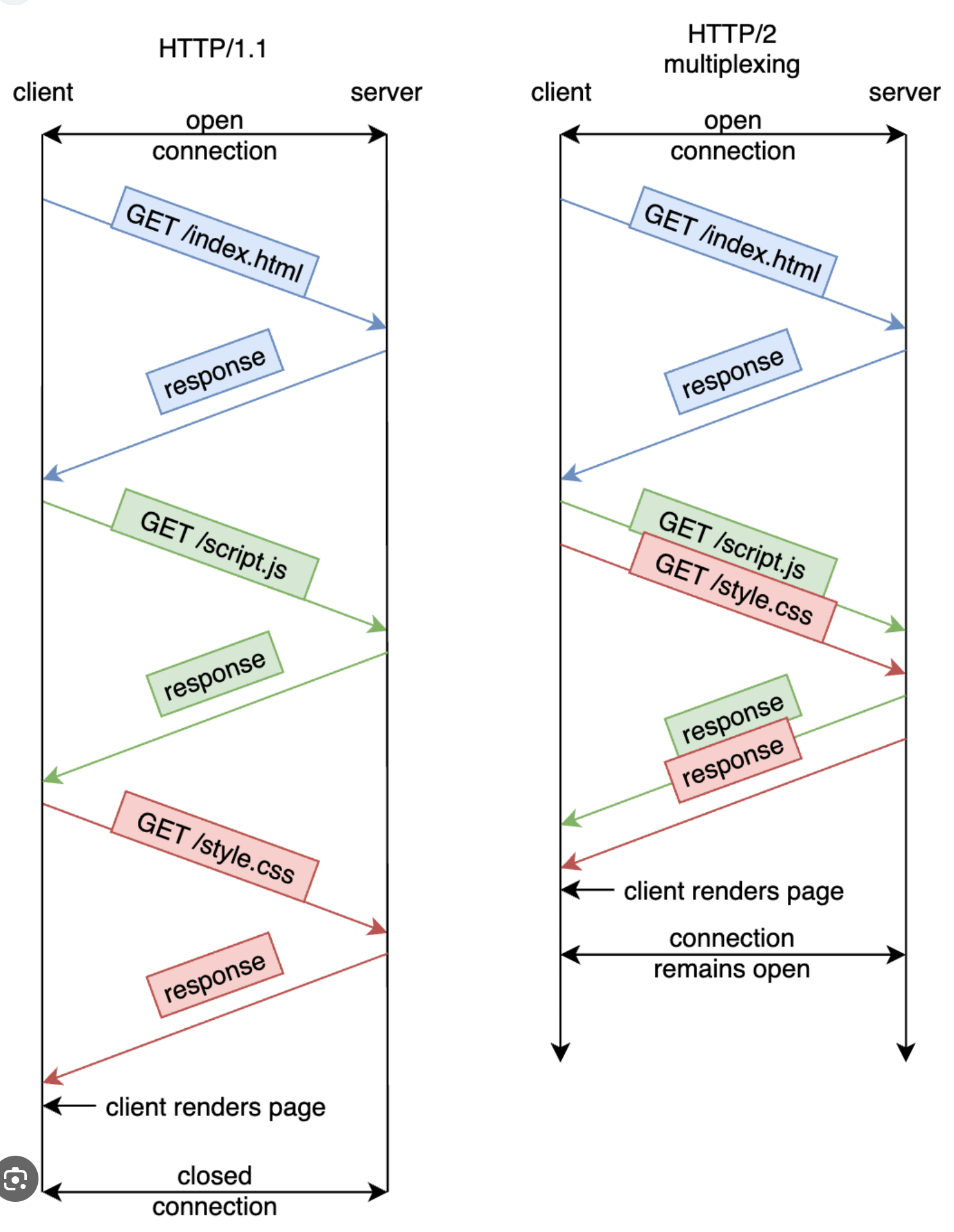
- http 2 引入了 stream 的概念, 在应用层实现了 多路复用 multiplexing, 不是那么依赖于 keep alive 了 → 怎么理解这两点?
- http 1.x 里, http 请求是挨个发的 (串行), 那么在请求与请求之间, 就会有空档; 就需要 http keepalive 在防止 TCP 连接在这个 空档 中被关闭; aka 通过 应用层 来保持 TCP 连接
- http 2 里, http 请求是拆分成 streams 来发的, 遵循着 TCP 字节流 的原则 → http 请求与请求之间的空档就小了 (甚至可以说是没有空档了), 也就不太依赖应用层的 keep alive 了
- 简单来说, 因为 http 2 的 multiplexing, 没有 keep alive 的情况下, 不同的请求也是通过 单个 TCP 连接来发的 → http 使用来看
- 而且本身从 http 使用的角度来说, 一般 http 请求都是 short burst
- 比如说 web browsing, 加载一个网页就是一阵 short burst, 把 html、css、images 啥的都在很短时间内一次请求完; 完了之后很长时间又不会再请求
- 这个和本身 tcp 长 连接、字节流 的主旨也有点违背
tcp keep alive
- 目的:
- 在tcp 请求闲置的时候, 连接的一方需要判断是否要结束连接, 探测 和 维护 连接的作用, 也防止tcp连接被防火墙等网络设备关闭 (保活机制)
- 本质是个 tcp 自己的 心跳 机制
- 实现:
- 是 内核 在 传输层 实现的
- 内核 会发一些 tcp 数据包去探测连接的另一方, 看对方是否还在线;
- 如果发出去的用于保活的 tcp segment (probe) 连续几次都没有响应的话, 就可以关闭连接了;
- 与 http 无关, 是 tcp 自己的一种机制
- note:
- 看对方是否在线 这点, 如果是应用层序崩溃, 内核是会发送 FIN 来主动结束 TCP 连接的;
- 会出现这种 tcp 保活没有相应的情况, 可能是因为对面的主机直接倒了, 直接宕机了
http/1.0
- 没有长连接 keep-alive, 每次都要重新进行 tcp 握手
- 并不是不支持, 可以通过
connection: keep-alive这个请求头开启, 但是默认是关闭的
- 并不是不支持, 可以通过
- 不支持etag (caching)
Note
http 的 keep alive 和 tcp 的 keep alive 不是一个概念:
- http: 一个请求发完后, 是否保持 tcp 的连接
- tcp: 要多久关闭这个 tcp 的连接 (如果有 tcp keepalive, 那么会定期地发个 probe 类的数据包去保持 tcp 连接)
http/1.1
http 是应用层的协议, http 下其他层的协议栈可以改 → 没有强依赖于传输层某个特定的协议 → http/1.1 和 http/2.0 是tcp, http/3.0 是UDP
http/1.1 特点
- 无状态(服务端没有记忆能力)
- 有响应阻塞的问题: 服务端收到多条请求, 如果第一条请求时间过长, 后面的请求也一直在排队等着, 会导致客户端长时间收不到回复
- 浏览器的解决方案是一次和同一个域名建立多个tcp连接, 多开几个tcp通道来发http
怎么样理解 http 1.1 是 无状态 的:
- http 1.1 的每个请求都是独立的, 这里是和 http 2 的 压缩头部 进行比较;
- 在 压缩头部 这个技术中, http 请求之间就不是完全独立的了; 后一个请求依赖前一个请求.
问题: 不是有 cookie 这个东西吗? 服务端通过让客户端在请求头里加上 cookie, 这样服务端不就 记住 客户端了吗, 不就有状态了吗?
- cookie 这个东西吧, 他本质就是个 header 里的值
- application code 可以通过 cookie 来判断客户端的状态, 如是否登录了等
- 但是本身 http 1.1 作为一个协议, 是 无状态的, 前一个请求是不会影响后一个请求的
- 当然, 前一个请求如果 删库 了, 那当然是影响下一个 查库 的请求的了
- 但是这个和 cookie 是一个道理, 这是 application 的问题, 不是 network stack 的问题
pipelining
-
client 可以连续发多个请求, 而不需要等到 收到第一个请求的响应 之后再 发第二个请求
-
即便又了 pipeline, server 还是只能 一个 response 一个 response 地 返回, 从 request queueing 变成了 response queueing
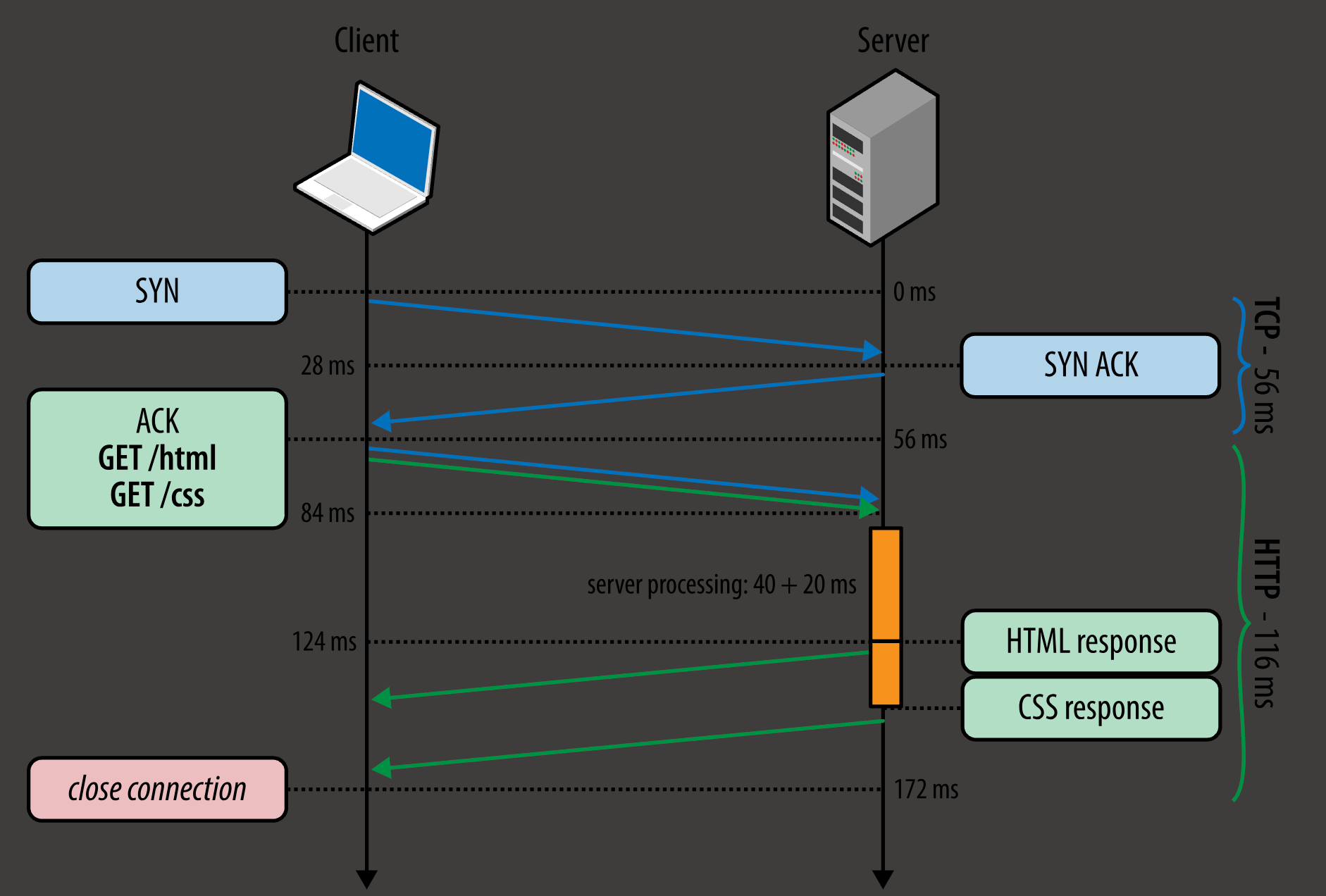 放图了也放个 credit 呗, 现在想看下原 blog 都找不到了, shoot myself in the foot smh
放图了也放个 credit 呗, 现在想看下原 blog 都找不到了, shoot myself in the foot smh -
如果 server 能够同时处理多个请求, 那 也能直接一次返回多个response
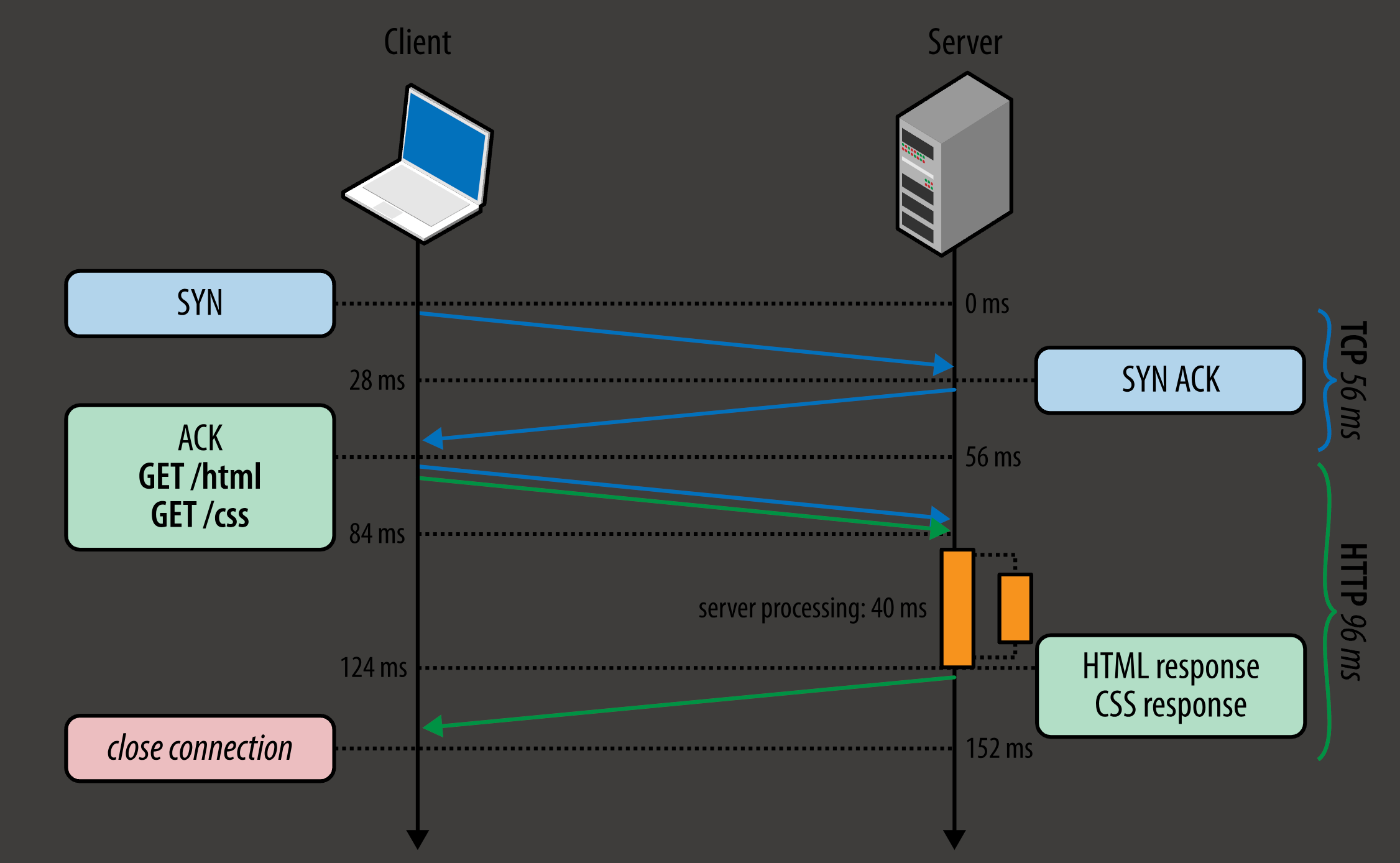
head of line blocking
- 上面那张图中, server in parallel 地处理 html 和 css 的 请求, 先处理完了 css 的, 但也只能等到 html 的请求处理完了之后才能发送 css; 因为服务端要按照请求的顺序来返回
- 换句话说, http/1.x 的请求、返回都是有序的; server 要返回了第一个请求的 response, 才会返回第二个请求的 response
- http/2 有 stream 咯, 虽然还是 TCP, 但 http message 都是无序的了
- 如果 html 请求被堵住了, 那后面所有的请求都被堵住了, 这就叫 队头阻塞 head of line blocking
- 这里是 http response 因为 http/1.x 协议的设计而被堵着了, 所以是 http 自身的 队头阻塞
Note
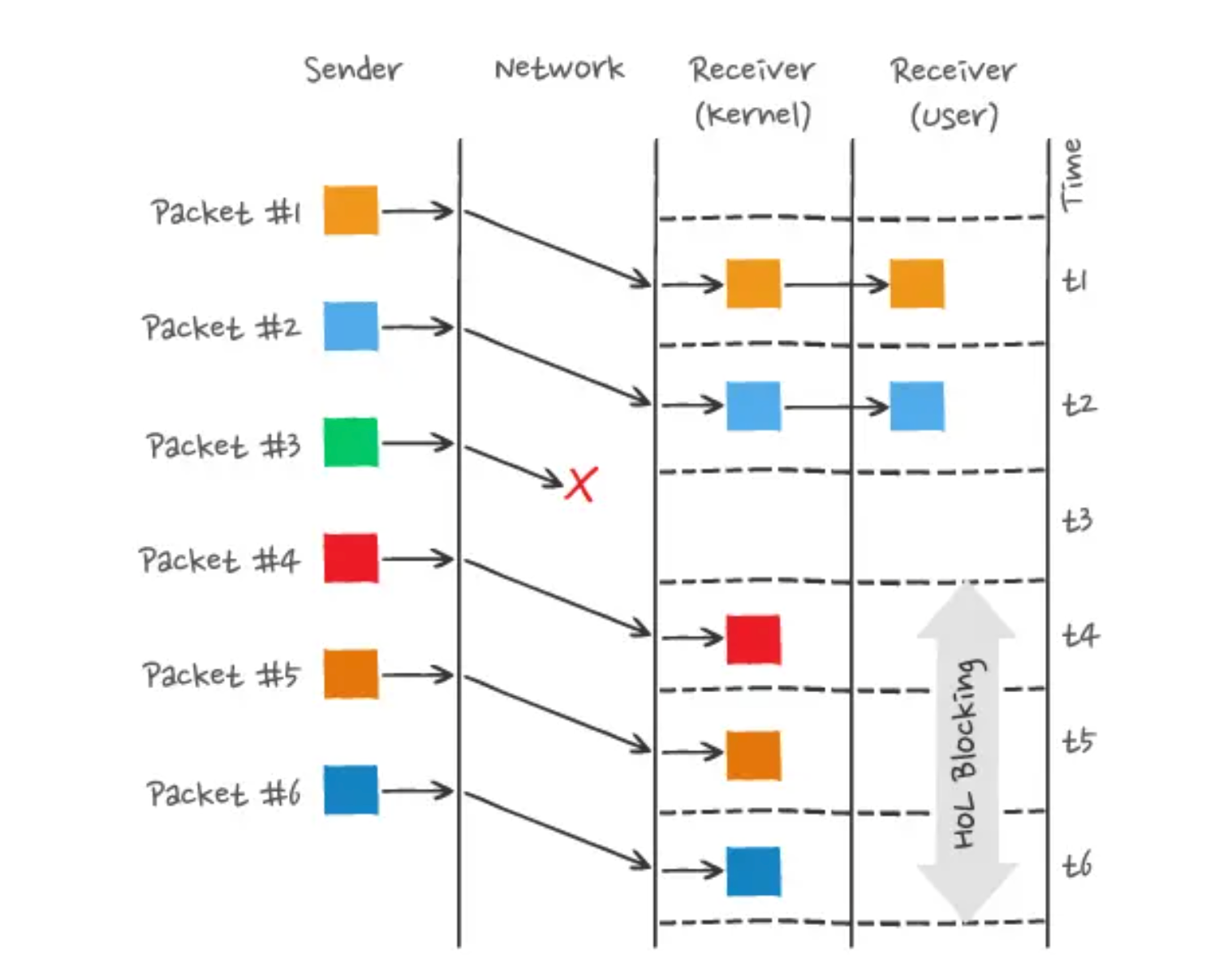
tcp 也有 head of line blocking, 因为 tcp 是有序的, 如果一个 tcp 数据包丢了, 那后面的数据包都要等这个包重传之后才会被处理
HTTP/1.1 pipelining 的问题
- 队头堵塞
- 如果客户端发了很多个请求 ABCD, 如果发生队头 A 阻塞的现象, 那 BCD 的 response 会被 buffer 住, 要等A发送了才会发 BCD;
- 如果 BCD 的 response 都非常大的话, 会把 服务器的 buffer 用完;
- attacker 可以这么攻击服务器
- 不是所有 intermediaries 都支持 pipelining, connection 可能会被 abort
Note
目前的情况仍然是 lack of reliable http pipelining support
HTTP/1.1 的弊端
- lack of reliable http pipelining support
- 请求头不会被压缩, 请求体会被压缩; 有很大的 protocol overhead
| 对比 | http/1.0 | http/1.1 | |
|---|---|---|---|
| 长连接 | 无, 每次请求都要重新握手、挥手(响应时间长) | 有 | |
| 管道 | 无 | 有, 因为有长连接, 客户端可以同时发多个请求, 不需要等到服务端回复了才发第二个(服务端也是按照请求顺序来处理)(管道其实都没开启, 很多浏览器也不支持)(有这个功能, 没咋被使用) | |
| etag | 无 | 有 |
https
-
http 是明文传输, 不安全
-
https 是在 传输层和应用层 之间, 也就是 http 和 tcp 之间 加了安全证书 Transport Layer Security (TLS), 实现了 http 报文加密传输
-
SSL: Secure Socket Layer
-
实现:
- 在 tcp 的3次握手过后, 还要经过 ssl/tls 的握手, 才能开始传输
- 其中涉及密使交换算法、证书相关的, 在此就先不学习了
- 在这里补充上了, 过后或许再重新 organize 下 transport layer security)
-
特点:
- 数据加密 → 通过随机数, 安全地交换密钥的那一套算法
- 身份验证 → https 确保的是 server 的身份, optionally 校验 client 的身份; server 的身份是通过 CA 发的证书来确保的
- 数据完整性 (通过哈希校验, 确保数据没有遗失或被篡改)
-
解决http的问题:
- 篡改问题
- 冒充问题
- 窃听问题
-
抓包工具是怎么获取 https 的信息的:
- charles 相当于个代理, 拦截进出流量
- 要想完成 https 的校验, 那么这个代理需要让 client 信任; 两种方法
- 获取到 server 的密匙假扮 server 或
- 自己整个证书, 并且让client信任 → 可行的做法
Note
https 涉及大量的加密计算, 是个 CPU计算密集型的协议, 不是个 I/O 密集型的协议
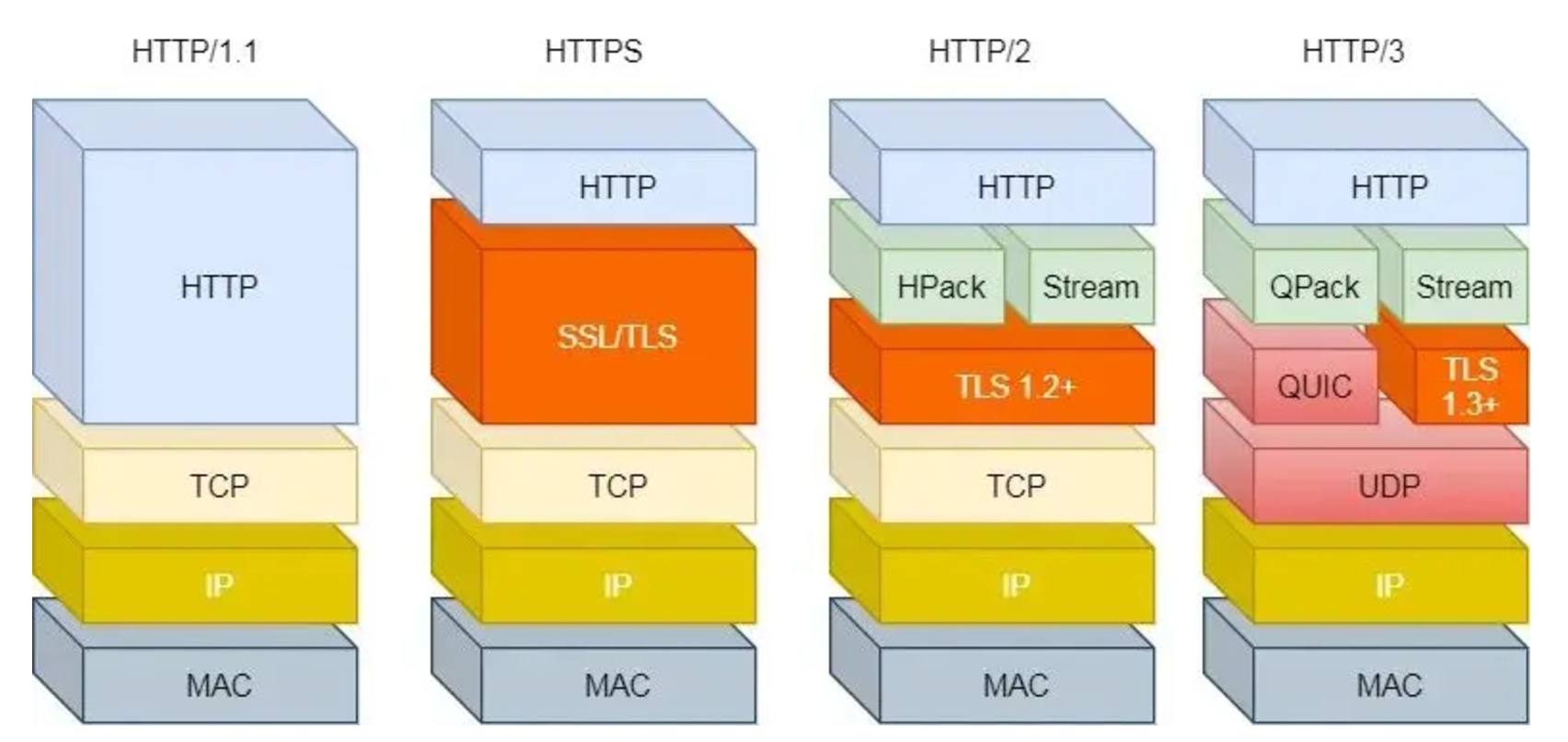
http/2.0 transport performance
http/2.0特性:
- 头部压缩
- client 和 server 共同维护一张 header 表, 如果 header 相同的情况下, 只发送对应的 index (这样对 server 的压力不是很大吗?)
- 二进制传输
- http/1.x 是文本传输
- 提高效率, 减少需要传输的字节数. 为啥二进制就高效了:
- 首先理解这个 “二进制传输“ 是个啥吧. 本身在网络上传输, 所有的数据不都是会被转换成二进制吗?
- 是的, 在物理层面上, 不管是啥数据, 都是转换成二进制的 digital signal, 再被转换成 analog signal, 才能在物理层面传输
- 说 http/1.x 是 文本传输, 指的是, 数据是 ASCII 编码的
- 首先理解这个 “二进制传输“ 是个啥吧. 本身在网络上传输, 所有的数据不都是会被转换成二进制吗?
- 并发传输
- 原有 tcp 连接的基础上, 引入了 stream 的概念, 用 stream id 来区分请求
- 无序传输: 可以先发个 stream1 的 header, 再发个 stream2 的 header, 再发 stream1 的 data, 过后再发 stream2 的 data
- 接收端会根据 stream id 来拼装成 http 消息
- 解决了 http/1.x 里 http 队头堵塞 的问题
- 服务器主动推送
- 服务端能够给客户端的 http request 发多个 response
stream
http2.0 引入了 stream 的概念. 一个 tcp connection 里可以有多个 stream
- http 引入的最重要的 performance boost: 能够把 http message 拆分 成多个 independent frame, 交织起来, 发送, 在接收端重新组合
- stream 是支持优先级的, 毕竟有时候 http 请求之间还是要讲究先后顺序的
Note
a “stream” is a single HTTP request and response exchange
stream 与 队头阻塞
在 http1.1 里, http response 的顺序一定是要按照 http request 的顺序来返回的; 在 http2 里, http response 的顺序不一定要遵循 http request 的顺序
假设同时请求:
- 一个大视频文件(A)
- 一个小图片(B)
- 一个CSS文件(C) HTTP/1.1:
- 即使小图片和CSS早就准备好了
- 也必须等大视频文件传输完成
- 严格按 A→B→C 顺序返回 HTTP/2:
- 小图片准备好了就先返回
- CSS文件准备好了也可以返回
- 大视频文件慢慢传输
- 最终可能是 B→C→A 的顺序http3
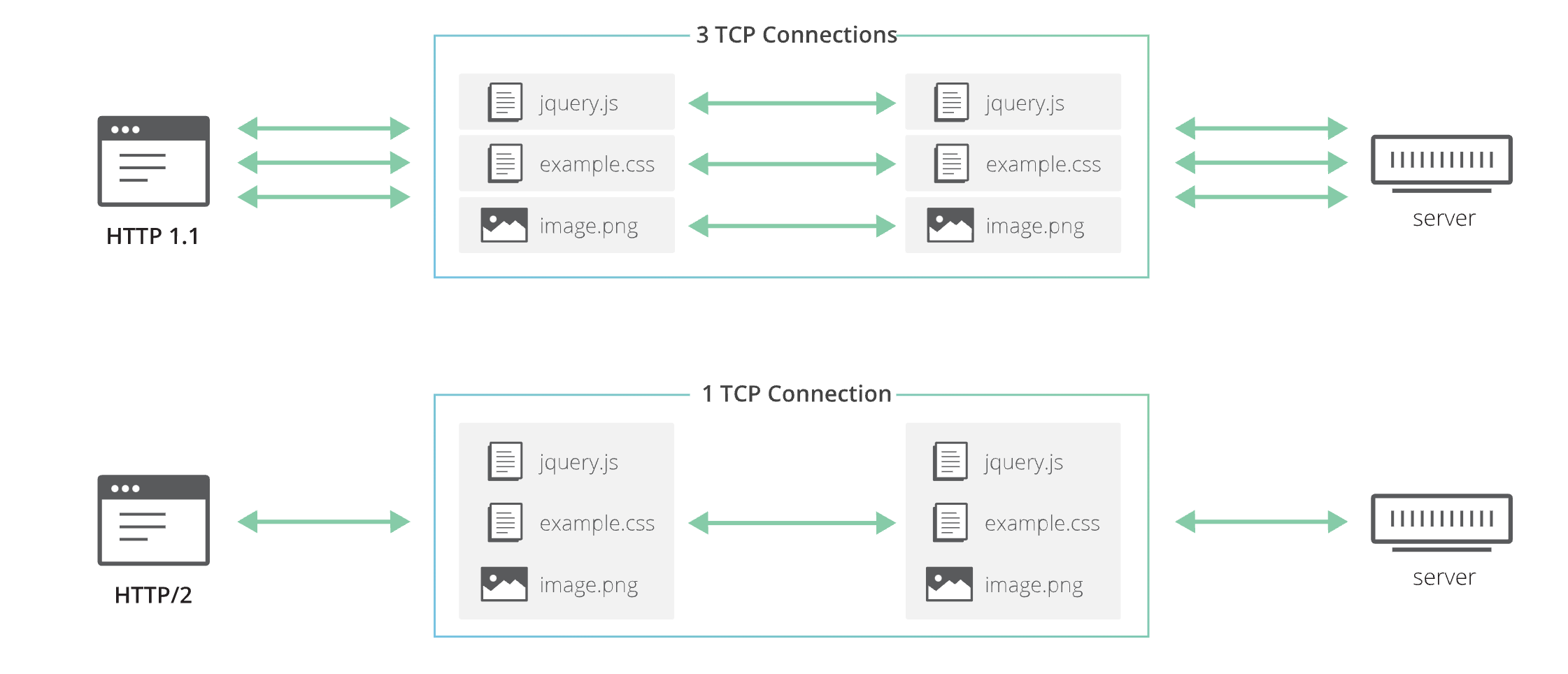
==http/2.0解决的队头堵塞的问题是在http层面, 但是tcp层面还是存在队头堵塞的问题==
- tcp 层的队头堵塞: tcp要求数据是连续的, 否则要重传; 如果出现了丢包的情况, 那就需要重传丢失的包, 否则后面的包也不会被处理, 这时候就出现了阻塞的情况
- 一个 tcp 连接像是一个 queue, 如果 queue 里有两个请求的数据 (AB), AB 是以并发的形式传输的; 如果 A 的某个包丢了, 那整个 Q 就卡着了, 导致 B 的数据也被卡着了
- 其实感觉说是 queue 也不太合适, 这里想要强调的只是 tcp 的 有序性, 和 queue 的有序性比较像吧
Note
Any existing website or application can and will be delivered over HTTP2 without modification → hpbn.co
- 这句话讲的是 application code 不需要 modification, 但是升级到 http2, 需要 server 和 client 都升级, 需要支持 binary framing; client 的 browser 和 library 这些可能也需要升级
stream 的优先级
Stream 1: GET large-image.jpg (低优先级)
Stream 2: GET style.css (高优先级)
Stream 3: GET script.js (中优先级)
服务器可以根据优先级调整资源分配和响应顺序
header compression HPACK
http1.x:
- http message 的头部都是 plain text,
- 没有被压缩, 并且有很多重复的 field
- 如果有 cookie 之类的 field, 请求头会变得非常大
http2 的改进:
- 引入静态表 static table
- http/2 协议定义的一张表 (包含 61 个常用 header ), 在 client 和 server 上都有这张表
- 静态表里存一些常用的 field, 比如 method, accept-encoding 等字段
- 在 http message 里, 就不需要传这些 field 的信息了, 直接传这些信息在静态表里的 index
- static 静态表, 内容不会变的
- 引入动态表
- server 和 client 各自维护一张表 (常用 header 以外的 header)
- 传输过的header会被添加到表里
- 过后再传输的时候, 只需要传输 header 在动态表里的 index 就行
- 引入了 Huffman encoding
- 压缩 header 注意:
- 引入表, 用了更多 memory; 服务器同时和那么多 client 连接着, 消耗服务器的资源
实际使用:
- 静态表大概是长这样
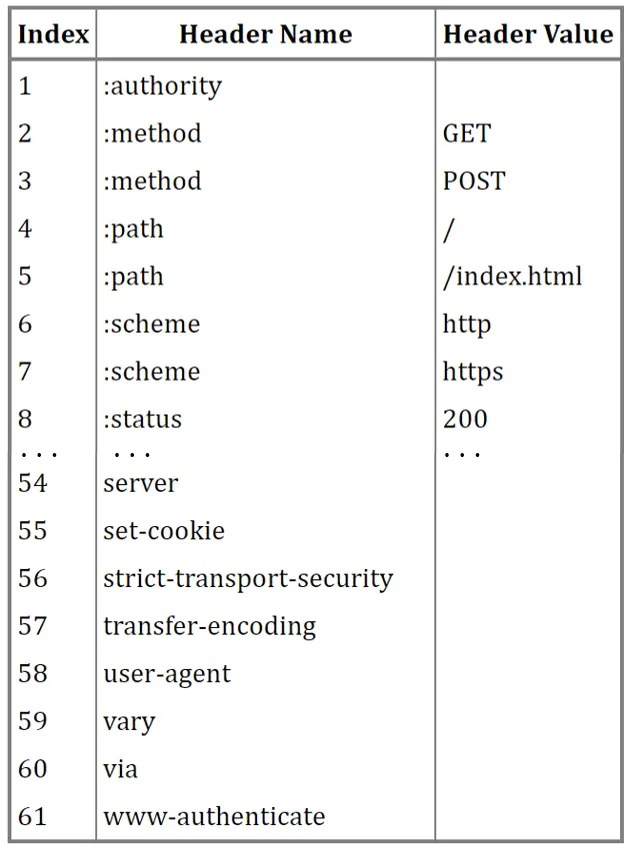
- 在请求的时候, http/1.x 得发
method get, 现在 http/2 只用发个2就行了
binary framing
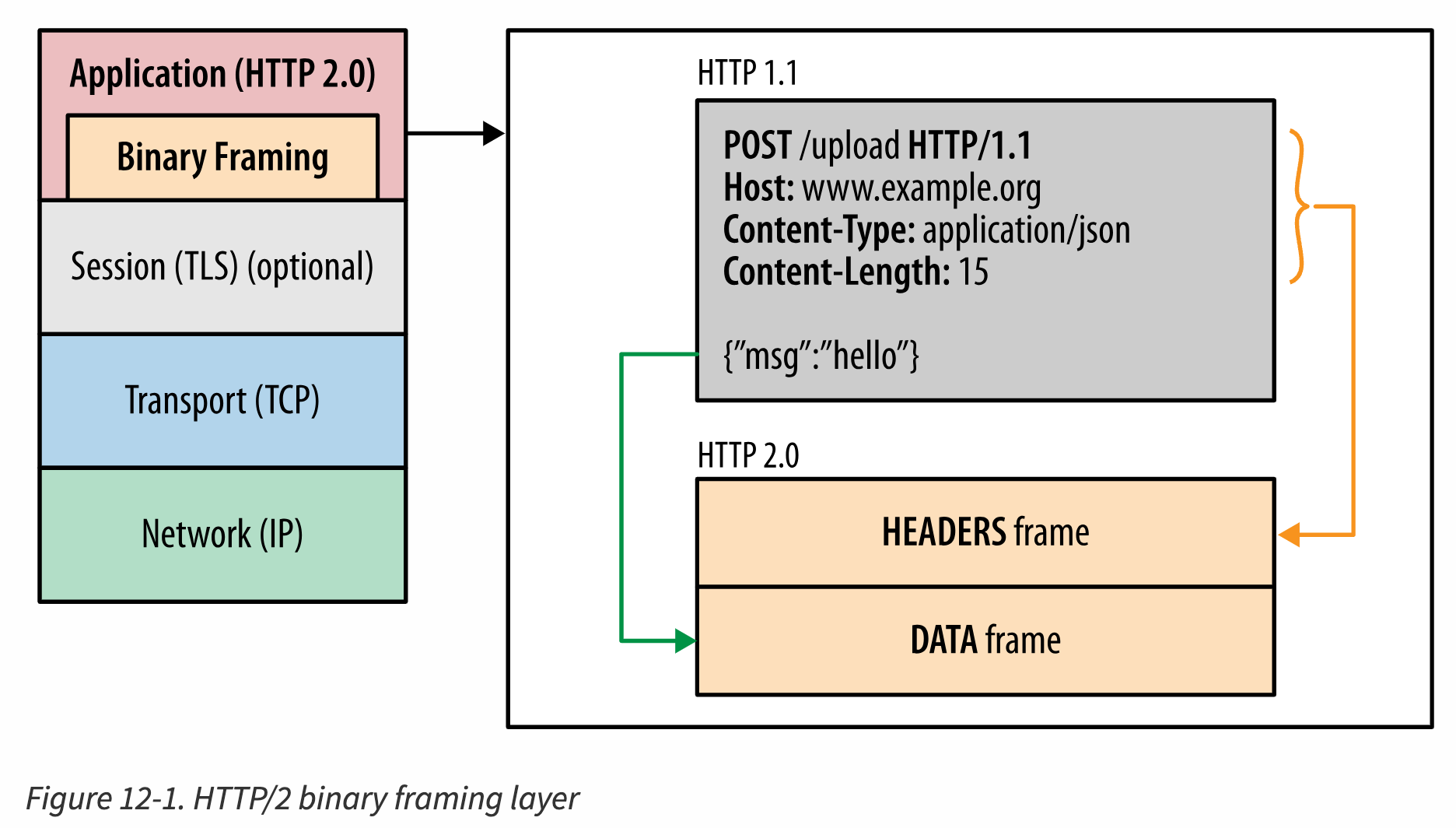 :
credit:
:
credit: 是什么:
- 在 application 层 和 transport 层 之间加了个 frame layer
- frame layer 把 应用层传下来的 http 消息 拆分, 加上一些 frames
+-------------------+
| HTTP/2 | 应用层语义(和 HTTP/1.1 相同)
+-------------------+
| **Frame Layer** | 新增的二进制分帧层, 把应用层的数据转成二进制
+-------------------+
| TCP |
+-------------------+
→ 从 http1.x 升级到 http2, 在应用层不需要有什么改变, 但是需要 服务端 和 客户端 都支持 frame layer
- 本身 http1.x 上, 应用层 只需要关心 请求头, 请求体, url; 在 http2, 应用层也还是只需要关心这几个; 所以可以平滑升级
- frame layer 在做的事情, 应用是感知不到的
例子:
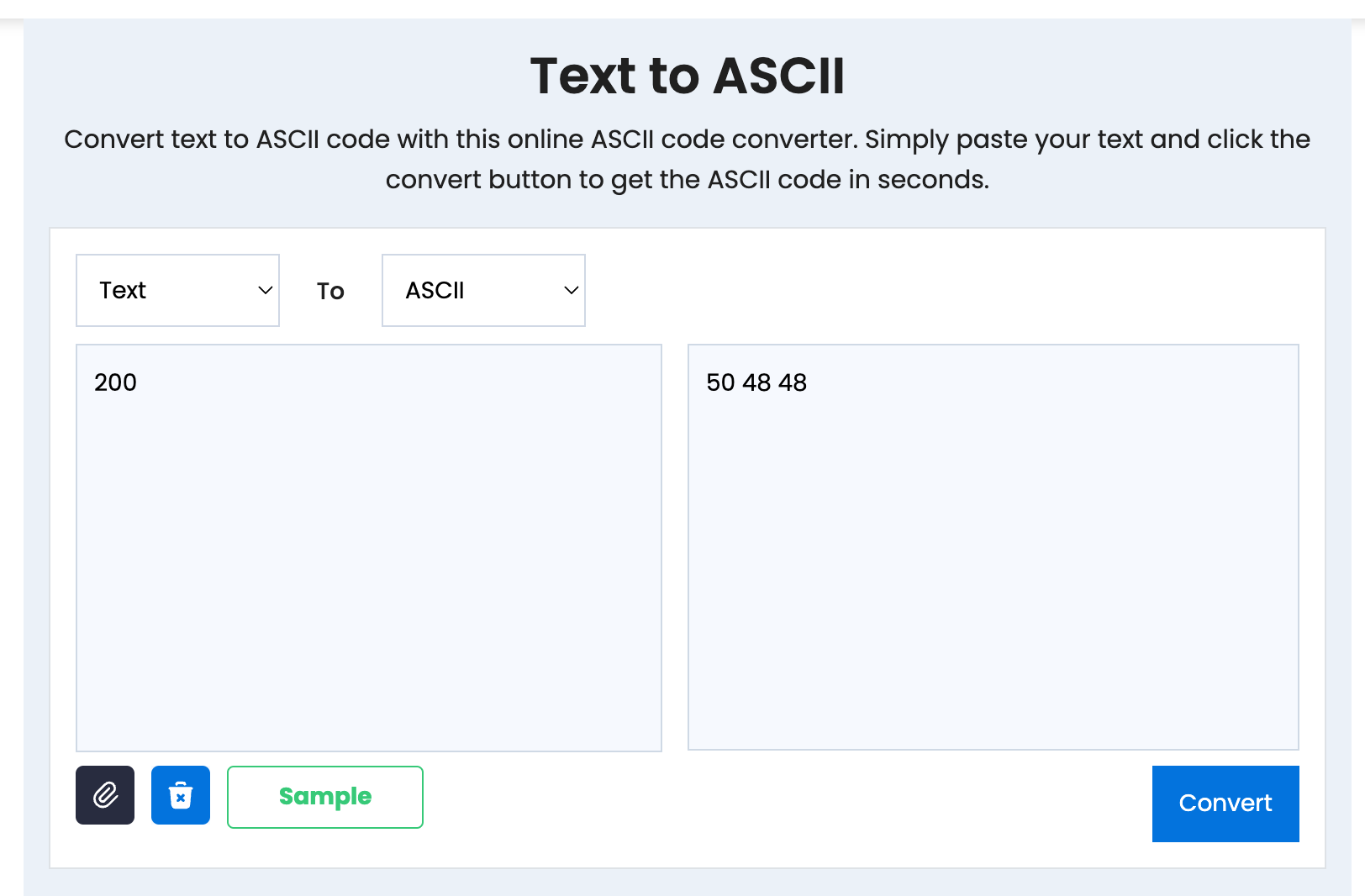
- http/1.x 中, 200 的 status code 转换成 ascii 是
50, 48, 48, 对应的二进制就是00110010, 00110000, 00110000, 一共要三个字节 - http/2 中, 看下面那个静态表, status 200 是 8; 经过 binary framing, status 200 变成了
1000 1000- 具体是为啥变成了
10001000, 看小林里有具体展开; 总体来说就是经过 binary framing, status 200 从 3 个字节减少到了 1 个字节
- 具体是为啥变成了
工作流程:
- 应用层:
- HTTP消息 → Frame Layer处理 → 拆分成帧 → TCP发送
- 接收方:
- TCP数据 → 读取帧头(9字节) → 根据长度读取帧体 → 重组HTTP消息
队头堵塞的问题
- http/1.0: 没有长连接, 请求一个一个处理, 第一个请求处理时间长, 一直没有返回的话, client连发下一个请求都发不出去
- http/1.1: 有 keep-alive 长连接 在收到返回之前可以发多个请求, 然后在 server 那形成个队列, server 按照顺序处理并返回; 这样不会卡请求了, 但是会卡响应
- http/2.0: 引入了stream的概念, 多个请求可以混着发(http层面的请求可以是不按照顺序的, 但tcp层面的数据sequence还是得是连续的), server 也可以多个请求并行处理, 但是如果出现丢包的情况下, 整条tcp连接就卡着了, 要等到丢掉了的包重传之后才能再继续; 这个是tcp层面的队头堵塞

- http/2.0, 图中不同的packet对应的可能是不同的请求的数据
http1.x 升级到 http2
- 在 应用 上, 不需要有任何改变; aka, application implementer 不需要改什么东西, 如果 server 和 client 都支持 http2 的话, 那就可以平滑升级了
- 平滑升级的前提是, 需要 server 和 client 都支持 binary framing;
- frame layer 相当于在 应用层 和 传输层 中间新增了一层, 需要服务器和客户端支持; 需要更新 Web 服务器(如 Nginx、Apache)和客户端(如浏览器)的底层实现
- 这个 binary framing 实际上不是 backward compatible 的! 所以 http/2 是 2, 不是 1.3
- 这个过程涉及到 infrastructure 的升级, 非常 labor-, capital-intensive, 所以是个缓慢的过程
- 要升级的是 infra, 不是 application code
- 现在主流上大部分浏览器都支持 http2 了, 会优先尝试 http2; 不行就会降级成 http1.1;
Note
Any existing website or application can and will be delivered over HTTP2 without modification → hpbn.co
- http2 改变的是 请求被 formatted 的方式、请求的传输方式
- 这些变动对于应用来说都是 不感知的; 所以能够直接平滑地从 http1.1 切换到 http2
- applications are unaware of the changes from http1.x to http2.
- 但是 server 和 client 的协议栈和 intermediary 要能够支持 http2; 一个 http 1 only 的 server 不能 decode http2 的信息; vice versa
啥叫 应用 不感知 http/2 的变动? →
- 这里把 应用 理解成 某个 app 的 dev, 就好理解了
- 不感知 指的是 传输层 的 透明性, 对于应用层来说, 传输层是 透明的
- http/1.x 升级到 http/2, 应用不需要变更,
- 指的是 http 定义的 应用使用 http 的方式 不变
- 比如 http header 还是那样, http status code 还是那样; 这些是 应用 使用 http 的方式
- 这个 app 的 dev 只要更新下 http 的包就行了, 他还是照样用以前的方法来使用 http
- GPT: 如果应用程序基于标准 HTTP/1.1 API 和框架开发(如 requests 或 Flask),在支持 HTTP/2 的网络栈上运行时,理论上可以直接无缝升级到 HTTP/2。
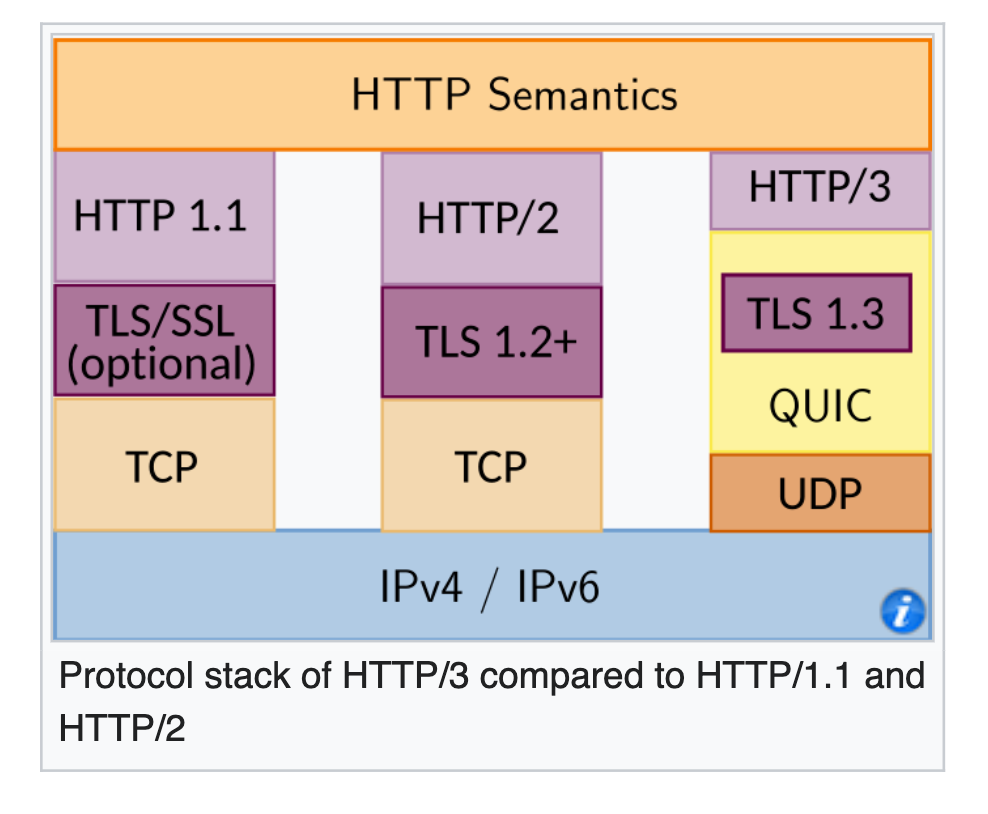
http/3.0
使用了 UDP, 使用了基于 UDP 的 QUIC 协议, 3个特点
- 无队头阻塞
- 更快的连接
- 连接迁移
- → QUIC 的每个连接有连接 ID, 按照连接 ID 来识别连接
- 在网络环境变化的情况下 (ip:port有变化, 用户从Wi-Fi切换到移动数据等), 通过连接 id 可以保持连接, 不用重新启动一个新的连接
- 是 保持连接 还是 快速启动新的连接?
Note
QUIC 是个 transport layer 的 protocol, 基于 UDP
QUIC: Quick UDP Internet Connections.
QUIC
- QUIC 是个 基于 UDP 的 传输层 协议
- 在 UDP 的基础上实现了 可靠传输, congestion control 这些
1 RTT 建立连接
- 相当于把 TCP 连接的 handshake 和 TLS handshake 合并
- 在 http1, http2 里, 先进行 TCP 的握手, 再进行 TLS 的握手
- http3 用了 QUIC, 把这两个握手合并了, 在 连接握手 的时候就 协商加密信息
0 RTT 复用连接
- 在第二次建立连接后, 可以在握手的时候发送之前的 pre-shared key, 加上 early data (application data)
内置加密
- QUIC 是强制要求 TLS 的, 而不是之前 TCP 那样, 可以选择是否需要加密
- 因为 QUIC 用了 UDP, 以数据包的形式传输, 所以 encryption 也是按照数据包为单位实现的; 一个数据包传送完成之后就可以被解密; → TCP 就不能实现这点, 因为 TCP 是 bytestream, 数据包的边界是 应用层的http 来划分的, 作为传输层的 protocol, 是感知不到应用层划的边界的, 所以要等到传输全部都完成了才能 解密
Note
QUIC is encrypted by default.
connection id
- 传统的 TCP/IP 通信依赖于 ip:port 来识别连接. 如果设备断开重连, 可能就有不同的 ip:port 了, 那就要重新连接
- QUIC 引入了 connection id 的概念, 在连接断开重连的时候, 传入 connection id, 能够快速恢复连接
- QUIC 的这个 connection id 独立于 ip:port;
- QUIC 通过 connection id 来 识别 一个网络连接; 传统的方式是通过 ip:port
连接图解
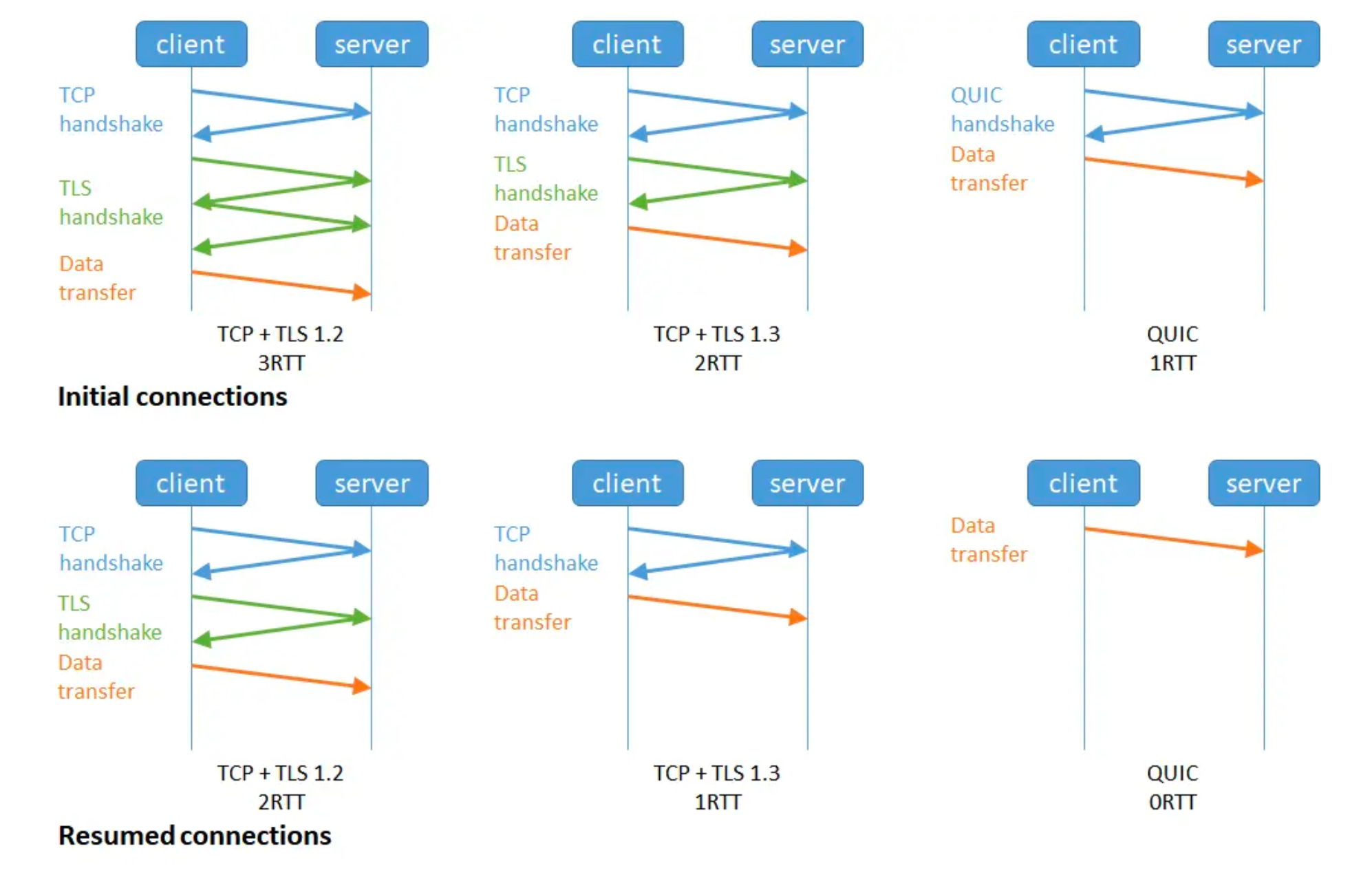
- 0-RTT 是指 第二次连接 的时候, 建立连接的 round trip time 是 0, 不需要 round trip time 就可以直接发消息
- 基于之前的连接id和密钥信息, 就可以直接发送信息, 服务端收到了之后校验没问题就可以返回了, 不需要再握手.
QUIC 能够快速恢复连接
基于以上这几点, QUIC 能够快速恢复连接:
- 0 RTT: 可以省略握手
- connection id: 如果 ip port 变了也能快速连接 如果只有 0 RTT, ip port 变化也要重新握手; 如果只有 connection id, 重新连接的时候也要重新握手 这两个 feature 相辅相成, 使得 QUIC 能够快速恢复连接
推广 QUIC 遇到的问题
设备支持
- 现在市面上使用的 NAT device 一般都不能解析 QUIC
- 比如说, NAT device 会用 UDP 的方式来处理 QUIC, 结果就把 QUIC connection 给 timeout 了
- 很多 intermediary, middle-boxes 都不支持 quic
- 在 ip port 有变化的时候, layer 4 load balancer 可能就把 数据包 给转发到其他 server 了, 即便还是同一个 connection id
UDP 无序和 QPACK
- http2 用了 HPACK 来压缩请求头, 并且用了 Stream
- 因为 TCP segment 是有序的, 所以 update header 非常简单
- http3 用 UDP 传输的时候, 因为 UDP 是无序的了, 不能确保 HPACK 压缩请求头这个流程还能正常运转, 例如:
- http3 同时发3个请求, 预期顺序是ABC, 如果 B 更新了 header, C 需要保持 B 更新后的header
- 但是 C 可能会比 B 还先到 receiver, 这时候就出问题了
以上问题的解决方法在这 cloudflare 的 blog 里 有讲到: (还需要再拓展下, blog 还没看完)
In the gQUIC protocol this problem was solved by simply serializing all HTTP request and response headers (but not the bodies) over the same gQUIC stream, which meant headers would get delivered in order no matter what.
- 在 gQUIC (Google QUIC) 这个 protocol 里, 所有 http 消息的 header 都会被序列化, 保证 header 是有序的
- downside 是, 本身用 UPD 是为了解决 TCP 带来的 head of line blocking, 这相当于又把 TCP sequencing 的概念引入了, 又会出现 head of line blocking
- 最新的 draft 里, 在原来的基础上多用了 两个 unidirectional streams 来解决这问题:
- 一个 stream 是 sender 发 header update 的信息
- 另一个 stream 是 receiver 来 acknowledge 收到了 header update 的信息
队头阻塞
-
也用了 stream 的概念 (stream 在 http/2.0 里是指一个 tcp 连接可以不按顺序地发 http 请求, 一个 stream 对应一个 http 请求, http/3.0 是基于UDP的, 已经不需要 TCP 连接了, 这里的 stream 怎么理解? ) → HTTP/2.0 基于TCP, TCP segment 有 sequence 的概念, 一个 sequence 丢了, 这个 sequence 后的所有 segment 都要等到丢包重传之后才会被应用层使用
-
HTTP/3.0 基于 UDP, 没有这个 sequence 的概念, 在 QUIC连接 后, 丢了一个 stream 的某个包, 也不会影响其他 stream 的数据被应用层使用
-
解答上面的问题, http/3.0基于UDP, 是没有TCP连接的概念了, 但是引入了 QUIC 连接这个概念
HTTP 和 TLS
QUIC
- TLS 在 TCP 中是可选的, 但是 QUIC 里是 内置 的, 一定有的
- 原来 TCP 和 TLS 要单独握手; 在 QUIC 里, 一次握手里就包含了 建立连接 和 加密握手 的信息, 所以一次握手就够了
如何优化http1
Note
no request is faster than a request not made
优化http的3个思路:
- 避免请求
- 减少请求
- 减少请求数据的大小
避免请求
→ 缓存
减少请求
减少 redirect
- 一次 redirect 意味着 DNS lookup, TCP、TLS 握手全部都要从头开始
- 针对有 redirect 的情况, 应该在服务器代理的层面完成 redirect
这个图里 reverse proxy 让 client 完成 redirection, 效率就低了: client reverse proxy server | -request--> | | | <-redirect- | | | | | | -request--> | | | | -request--> | | | <-response- | | <-response- | |这个图里 reverse proxy 自己完成 redirection, 效率就高: client reverse proxy server | -request--> | | | | -request--> | | | <-redirect- | | | | | | -request--> | | | <-response- | | <-response- | | - 返回如果是301或308 (permanently moved / redirect), 浏览器就在本地缓存好变化, 以后浏览器就在本地替换新的url之后再请求
合并请求
Note
弊端: 多个文件合并成大文件, 如果其中一个小文件改变了, 那也得全部重新请求
concatenation
- 把 html css js 文件合并成一个请求, 一次性返回
- 虽然传输的数据 body 是一样的, 但是请求次数少了, 就意味着请求 header 少了
- 弊端:
- 浏览器的缓存 粒度 变大 (每次要缓存的最小单位变大)
- 把 js 和 css 放在一起, 那要等全部都传输完, client 开能开始进行渲染、加载等工作; 如果分开传输的话, 一个请求完了, client 就可以开始进行一些工作了
spriting
- 把多个小图片合并成一张大图
- 通过 css background position 的方法来找到需要的图片
concatenation 和 spriting 把 tcp 请求次数减少了, 需要付出的代价是在 application 这一层需要做的工作变多了 -》 application layer optimization
http2 的 concatenation 和 spriting
- http1 的请求头不会被压缩, 加上会发生服务端返回队头堵塞, 我们用 concatenation 和 spriting 的方式来 合并请求, 为了 减少 请求头的 overhead, 和 减少服务端返回的次数
- 但是在 http2, 请求头会被 HPACK 压缩, 请求头所带来的 overhead 就小了; 并且多个请求的返回能够不按照顺序传输, 也就不存在 服务端返回 队头阻塞 的问题了
- 所以在 http2, 需要从新考虑 concatenation 和 spriting 的 pros and cons
concatenation 和 spriting 的 cons:
- 本来是 css 和 js, 两个合并之后, 如果只是 js 有改变, 那 css 也要重新通过 http 请求获取
- spriting 把所有图片都放在一起, 如果只有一个小图片改变, 那也要从新获取 (并且 spiriting 依赖 应用层 通过 background-position 来实现图片定位, 增加了应用层的复杂度)
- 客户端的 execution 也变慢了; 资源 1 和 2 bundle 在一起, 本来收到资源 1 之后就可以开始除了 资源 1, 现在要等到两个资源 (bundle) 都传来 才会开始处理 pros:
- 虽然 http2 能压缩请求头了, 但合并请求直接就减少了请求头, 所以还是有好处的
- 并且在文件压缩上, 相同类型的文件压缩, 压缩率会更高; 比如 10k 的文本能压缩成 5k, 20k 的文本可能能压缩成 8k
- 并且在操作层面上, 每次 cache I/O 和 网络 I/O 都是有 overhead 的, 合并请求之后, 减少了 response 的个数, 也就减少了这个 overhead 所以 http2 也没有完全 eliminate concatenation 和 spriting.
domain sharding
- http1 一次最多只能和一个 host (origin) 有 6~8 个 tcp 连接; 有这么个 tcp 最大连接数 的限制
- 那针对不同的资源, 服务端可以通过 domain sharding 的方式来 分散资源; 比如说,
- 客户端本身是向 resource.example.com 请求所有资源,
- 现在服务端把资源分别放在了 resource{1,2,3}.example.com 上;
- 那客户端就可以分别和这些 domain 进行 tcp 连接, 变相地增加了 tcp 最大连接数, 从而提高了效率
→ 本质就是分散资源, 让 client 和 server 之间能有更多 tcp 连接
caveat:
- http1 需要 domain sharding 的原因是, 服务端只能依照 请求的顺序 来响应 返回, 这样会出现 response head of line blocking 的现象
- 通过 domain sharding, 资源被分散, 客户端向 不同的服务端 请求资源, 缓解了 response head of line blocking
- 但是这里出现了 多个服务端, 意味着 多个 tcp 连接, 这不是啥好事, 因为 tcp connection is expensive (1 个 RTT); 只能说在 http1 上, domain sharding 的 benefits outweigh 了 cost
- 在 http2, 服务端可以不按照请求顺序返回响应了, 那就不需要多个 tcp 连接, 也就不需要 domain sharding了
- 在 http2, domain sharding 的 benefit 不能 outweigh cost, 应该减少 或 eliminate domain sharding
- domain sharding 只是 http1 的一个 workaround, domain sharding 还增加了 DNS lookup 的次数!
个人想法:
- 其实 domain sharding 的本质是, 向不同的 host 请求资源, 增加了 parallelism;
- 本身在 http1.1 之上, 请求可以通过 pipeline 来传输, 服务端也可以并行地处理 多个请求; 只不过 服务端 还是得 一个一个地返回请求, 所以会堵塞
- domain sharding 是增加了不同的服务器, 所以在 客户端 同时获取多个资源的时候不会堵塞了
- http2 的 stream 已经解决了服务端响应堵塞的问题, 所以不需要 domain sharding 了
- By contrast, HTTP/2 performs best when a single connection is used → hpbn.co
减小请求的大小
→ 压缩, 有损无损压缩
使用 CDN
- 缩短 客户端 到 服务器 的距离, 缩短 RTT
客户端 caching
no request is faster than a request not made.
cookie (待拓展)
http 是 无状态的 (stateless), 每个请求之间是没有关联的; 但有时候需要保存客户端的状态, 比如:
- 身份验证
- 跟踪分析 (收集数据分析用户行为)
cookie 实际上是 client-specific metadata cookie 的功能是保存 会话状态 但很多时候, 特别是获取 static asset 的时候, 是不需要 client-specific 的
工作原理
- 服务端返回的 header 里 包含 set-cookie: cookie_value
- 客户端在接下来的每次请求里都带上 cookie: cookie_value