links
TODO
- 用以下结构重新梳理一下这些
- 功能解释
- flags
- 常见使用方法
- 解读返回
- 使用场景
unix, shell
unix 是个 操作系统 OS, 是 linux 的前身 shell 是用户和 unix 交互 的 interface
基本符号概念
/
root dir:
find /→ find in root dir (the whole computer)
root dir 是个 root, 是整个电脑里, 文件 hierarchy 的最顶层, 所有文件和目录都位于根目录下
- 需要 系统管理员权限 (root user) 才有 完全访问的权限
~
home dir:
find ~→ 在 home dir 里找- 是 user space 的目录, 每个 user 都有个 home dir
\
escape sequence
\n换行符号,\t打印个 tab 一行命令太长的时候, 用于换行:
echo "this is \
a very long line"以上命令和 echo "this is a very long line" 是一样的
&
run in background, 在后台运行命令
sleep 100 &- sleep 命令在后台执行, 会返回一个 PID, terminal 可以继续干别的事
- 执行完之后, terminal 会打印出进程执行完毕的信息 重定向符号
&>代表 同时重定向 stderr 和 stdout
&&
将多行命令写在同一行, 只有前一个命令成功了才会执行后一个
cat test2.txt && echo "\nnow running ls\n" && ls- test2.txt 不存在, 后面的命令全部都不会执行
;
将多行命令写在同一行, 并且按顺序执行, 前一个命令失败了不会影响后一个命令
cat test.txt ; echo "\nnow running ls\n" ; ls- test.txt 不存在, 返回 cat 的 stderr
- echo 正常打印
- ls 正常打印
+
个别命令有特殊意义, 如:
chmod +x script.sh给 script 添加执行权限 在 find -exec 里, 用+的含义find . -name '*.txt' -exec wc -l {} \+-
- 代表 find 找到的所有文件放在一起执行一次, 相当于
wc -l file1 file2
-
find . -name '*.txt' -exec wc -l {} \;- ; 代表 find 找到的文件各自执行一次, 相当于
wc -l file1 ; wc -l file2
Note
+ 的效率更高!
|
pipe 管道
- 把前一个 command 的 stdout 写到下一个 command 的 stdin 里, 不包含 stderr
- 如
ls | grep 'test' - 如果需要 stderr, 需要重定向
> and >>
重定向
# 只重定向 stdout 到文件
command > file.txt
# 只重定向 stderr 到文件
command 2> error.txt
# stdout 和 stderr 都重定向到同一个文件
command > all.txt 2>&1
# 使用新的语法同时重定向 stdout 和 stderr(更现代的写法)
# 下面这两行是一样的
command &> all.txt
command >& all.txt
# 把 stdout append 到 all.txt, 不覆盖
command >> all.txt
# 重定向结合 append
# 下面这两行是一样的
command &>> all.txt
command >>& all.txt实际应用:
ls . ./test
./test不存在- 命令打印出的是
ls ./test的报错 (先打印 stderr, 因为 stderr 会被 flush, 没有 buffer)ls .的输出
ls . ./test > log.txt
./test不存在- 命令打印出的是
ls ./test的报错- 没有
ls .的输出, 因为已经被写到 log.txt 里了
log.txt存的是ls .的输出
ls . ./test &> log.txt
./test不存在- 命令打印出的是
- 没有
ls ./test的报错 , 因为已经被写到 log.txt 里了 - 没有
ls .的输出, 因为已经被写到 log.txt 里了
- 没有
log.txt存的是ls .的输出- 先是
ls ./test的 stderr - 再是
ls .的 stdout
- 先是
ls . ./test > log.txt 2>&1
- 这个命令的功能和
ls . ./test &> log.txt一模一样 - 把 stderr(2) 重定向到 stdout(1)
重定向 的顺序
ls . ./test > log.txt 2>&1
- 为什么在这一行命令里,
2>&1写在最后? - 为什么不是
ls . ./test 2>&1 > log.txt?
解答:
ls . ./test > log.txt 2>&1
ls . ./test > log.txt先把 stdout 重定向到 log.txt (此时 stdout 还没有被打印在 terminal)2>&1再把 stderr 重定向到 stdout 当前的位置 (此时 stdout 已经在 log.txt 里了)- 所以 stderr 就跟着 stdout 走到 log.txt 里面了
ls . ./test 2>&1 > log.txt
- 在这一行里, 先把 stderr 重定向到 stdout 当前的位置 (还是 terminal)
- 再把 stdout 重定向到 log.txt
- 所以这一行的执行结果是: stderr 被打印在了 terminal, stdout 进了 log.txt
重定向 和 管道
# 丢弃 stderr,只传递 stdout
command 2>/dev/null | grep "pattern"
# 同时传递 stdout 和 stderr
command 2>&1 | grep "pattern"
# 将 stderr 单独重定向到文件,stdout 传递给管道
command 2>error.txt | grep "pattern"<
input redirection
cat < file
为啥要 input redirection, 直接 cat file 不就好了吗?
- 有的 command 不支持读取文件, 比如
tr - 如果想要用
tr处理文件里的内容, 就需要<, 比如 tr -d "$" < input_file
其他用法:
diff <(command_1) <(command_2), 比如:diff <(ls .) <(ls ./*)
文本
grep
grep “pattern” file_or_dir
grep 是用 regex 查找 文件 里的内容
grep -l and grep -L
-l: 只找文件名, 包含 match 的文件名会被打印出来
-L: 只找文件名, 不 包含 match 的文件名会被打印出来
grep -r
-r: recursively.
如果要查找 dir, 那要用 grep -r, 会把这个dir里的所有文件都找一遍, 然后打印出包含 regex 的那一行
- 如果不要行, 只要文件名, 那是
grep -rl
grep “pattern” dir
grep "pattern" dir: 报错, dir: Is a directory
如果要在 dir 里找, 那需要使用 -r
grep “pattern” dir -r
会在 dir 里 recursive 地寻找 pattern, 深入到每个 sub dir, 然后把 dir/file: 包含 pattern 的那一行 打印出来
grep “pattern” file (-r)
grep "error" test.log:
- 会打印 test.log 里包含 “error” 的每一行
grep "error" test.log -r: - 会打印 test.log 里包含 “error” 的每一行
- 开头还会带上文件名 test.log, 如下:
test.log: this is another error
本身 -r 用于 dir, 用在 file 上没有太大意义, 但也不会报错
grep ABC
grep "some text" -A 10: 把 match 的后 10 行也打印出来 (After)- B 是 before
- C 是 context, -C 1 是上下 各 1 行
grep -o
-o:
- 只筛选出 match 的部分, 而不是一整行都会打印出来
grep -E
- extended regex, force grep to behave like
egrep
awk
awk 是个 CLI 的 mini programming language 基本语法:
awk 'some condition {some action}' path/to/file- 注意, 是 单引号
- 注意, 单引号里要有
{}
code:
BEGIN {}
CONDITION {action}
CONDITION {action}
END {}-F
-F: 后面接 delimiter
awk -F , '{print $1}'
,作为 delimiter, 打印出 第一个 column 的内容
-v
定义变量
awk -v name=my_name '{print name}' text.txt
NF, NR, FNR
NF:
- number of fields, 这一行的 field 的数量
NR: - number of records, 行数
FNR: - 和
NR的差别是, 每个新的文件, 都会被重置 NR不会重置, 会一直叠加- 可以这样理解:
NR是 stdout 的行数,FNR是 File 的行数
复杂的用法:
command 1[TBC]:
awk 'NR==FNR {ages[$1] = $2; next} {print $1, ages[$1], $2}' file1.txt file2.txtfile1.txt
Alice 25
Bob 30
Carol 27file2.txt
Alice Developer
Bob Manager
Carol Designeroutput:
Alice 25 Developer
Bob 30 Manager
Carol 27 Designercommand 2[TBC]:
awk '!seen[$3]++ {print $3}' employees.txt如何理解这个 seen?
- 是新的变量吗
- 从
CONDITION {action}的结构看,!seen是个 condition - 如何理解 seen 有个
++
sed
edit text, most used for replacing text in a file
- sed: stream editor
用法:
sed -i '' -e 's/foo/bar/g' test.txt在 原文件 里把 所有 的 foo 替换成 bar- 解释:
tr
translate characters
tr find_character replace_character < path/to/file
-d:
- delete
tr -d "$": delete ”$” -s:- shrink, shrink multiple same character into 1
more & less
display long files one page at a time
- 在 wezterm 上跑起来, 貌似 more 和 less 都没有差别
- 在 linux 上跑了一下, 和 google 说的一样:
- more 使用上下 arrow 费劲
- less 好用很多
head
head —lines 10 或 head -n 10 展示一个文件的前 10 行, 可以和 pipe 结合 head —bytes 10 或 head -c 10 展示一个文件的前 10 bytes, 可以和 pipe 结合
tail
基本和 head 一样, 不过有个特别的是 -f 这个 flag
tail -f path/to/file
- 能够一直读, 打印最新的数据
- 如果是 cat 一个 命名管道, 内容打印出来后进程就结束了
- 如果是 tail -f 一个命名管道, 内容打印之后进程还会一直在跑; 有新的东西写到 FIFO 里就会被 tail -f 打印出来 不知道对这个文件有没有什么要求, 如果是普通的 txt, vim 写入 txt 之后不会被 tail 出来 但是如果是 FIFO, 就会被实时打印出来 gpt 说可以用 tail -f 来实时加载最新的 log
sort
display the stdout in a specific order
sort --field-separator=: --key=3n --output=output.txt /etc/passwd
test
文件 & dir
ls
- list directory, 打印这个 dir 里的内容 flags:
- -ld: l: long, d: directory
- -A: 全部文件, 包含
.开头的文件, 不包含.和.. - -a: 全部文件, 包含
.开头的文件, 包含.和.. - -d: 展示 本目录 的内容, ls -ld 能看到
.的权限 用法: - ls 只展示本目录;
- 如果要展示这个目录下的子目录:
ls -ld * - 展示 本目录 和 子目录:
ls -ld . ./* - ls 后面的参数是有层级的,
ls *是 depth=1,ls */*是 depth=2
Note
ls 后可以接多个path
ls -l 返回的结果:
total 0
drwxr-xr-x@ 5 bytedance staff 160 Nov 17 14:48 dir1
drwxr-xr-x@ 7 bytedance staff 224 Nov 17 14:48 dir2
drwxr-xr-x@ 3 bytedance staff 96 Nov 17 14:47 dir3
-rw-r--r--@ 3 bytedance staff 0 Nov 17 14:47 file1
-rw-r--r--@ 3 bytedance staff 0 Nov 17 14:47 hardlink1
lrwxr-xr-x@ 1 bytedance staff 5 Nov 17 14:48 softlink2 -> file1
- 第一个
-/d/l:- 文件类型;
-是普通文件,d是dir,l是 symbolic link
- 文件类型;
- 第二个
rwxr--r--: 权限 - 第三个
1: 指向该文件的 硬链接 数量 - 第四个: 用户 user
- 第五个: 用户组 user group
- 第六个: 文件大小, 单位 byte
- 第七个: 最后 修改时间
- 第八个: 名字
pwd
pwd 返回当前的路径
pwd -P
- 如果当前的文件夹是个 alias (soft link / symbolic), 这个会返回原文件的路径
- 如果当前文件不是 soft link, 那有没有 P flag 都一样
pwd -L
- 和直接 pwd 一样, 返回当前的路径
cd
直接 cd , 不加参数, 会回到 home dir, 不是 root, cd / 才是回到 root
rm
rm -R dir 强行 recursive 地删除 dir , 包括 dir 里所有的内容和 dir 本身 rm dir/* 删除 dir 里所有内容, 不删除dir本身 (实际上这个命令不会删除 dir 里 以 . 开头的文件) rm dir/{*,.*} 会删除 dir 里所有内容, 包括以 . 开头的文件
mkdir
mkdir 创建一个或多个 dir (如果 parent dir 不存在的话创建不了) mkdir -p
- 创建dir, 没有 parent dir 的话会把 nt dir 都创建了
- p → parents mkdir
- -m 创建dir, with permission
- (m → mode)
rmdir
chmod
修改权限, 3组 rwx, 分别代表 user、group、others
- 数字, rwx 的 二进制, 100 代表只有 r, 即十进制的 4
chmod 704 path/to/file给文件加上 user rwx, group 无权限, others r 权限
- 字母,
chmod u+r path/to/file给文件的 user 加上 r 权限, 也可以是o-xothers 减去 x 权限 - 修改 dir 里所有的文件权限:
chmod -R g+w,o-x path/to/dir
- 其他用法:
- 给文件所有角色加上读权限:
chmod a+r path/to/file - 移除一个角色的所有权限:
chmod o= path/to/file - 把 group 的权限设置成和 user 一样:
chmod g=u path/to/file
- 给文件所有角色加上读权限:
权限在文件和目录里的含义:
- r: 文件可读, 目录可查询 (可以使用 ls)
- w: 文件可编辑, 目录可 添加、删除、重命名 目录里的 文件和子目录, 即改变 目录内部的结构
- x: 文件可执行, 目录可进入 (可以 cd 进这个目录)
dir 权限展开: red hat blog
ls: readls -l: 需要 x 权限!rm,mv,cp,touch: write, 添加, 删除 需要 write, 因为是在改变 dir 的结构cd: 把 dir 变成 working dir, 所以需要 execution 权限
如何理解:
Lacking execute permission on a directory can limit the other permissions in interesting ways. For example, how can you add a new file to a directory (by leveraging the write permission) if you can’t access the directory’s metadata to store the information for a new, additional file? You cannot. It is for this reason that directory-type files generally offer execute permission to one or more of the user owner, group owner, or others.
→ red hat blog
所以, 有了 write permission 还是不能添加文件?
Note
是否有权限 添加、删除、重命名 一个文件, 取决于用户是否有这个文件所处 目录的 w 和 x
find
find path/to/dir -name 'pattern'
在 dir 里递归查找符合 pattern 的文件名, 会深入到每个子文件夹
flags:
-name: 简单的正则匹配文件名-type: 文件类型, f、d、l-size: 文件大小, 后面接 + -, 比如-size +100M, 筛选出大于 100M 的文件- 注意, find 的
-size是文件/目录本身的大小; find . -type d -size +100M是不能找出大于100M的文件夹的, 这个 size 是文件夹本身的大小, 不包含里面的内容
- 注意, find 的
-exec
# 错误示例
find . -type f -exec rm {} # 缺少结束符
find . -type f -exec rm {} ; # 分号没有转义
find . -type f -exec rm {} + # 加号没有转义
# 正确示例
find . -type f -exec rm {} \; # 使用转义的分号
find . -type f -exec rm {} \+ # 使用转义的加号
find . -type f -exec rm {} ';' # 使用引号包住分号
find . -type f -exec rm {} '+' # 使用引号包住加号+ 和 ;
- + 代表找到的所有文件 一起 作为
{}的参数 - ; 代表找到的文件各自 单独 作为
{}的参数
-exec 和 -execdir
pwd: print current working dir
find mydir -exec pwd:
- 命令在 mydir 里执行, 打印出来的都是 mydir 的 working dir
- find 出来几个结果, 就在 mydir 执行了几次 pwd find mydir -execdir pwd:
- 命令在 find 出来的文件的 dir 里执行, 打印的是 那个文件 dir 里执行 pwd 的结果

-print 和 -print0
-print:
- 打印的时候换行展示
-print0: - 打印的时候 不 换行展示, 换行符变成 null (
\0) 为什么需要-print0? - 和
xargs结合 - 假设我们要找到 大小超过 100M 的文件, 并把他们的实际占用都打印出来, 或许可以这样:
find . -type f -size +100M | xargs du -h
- 但如果有的文件是有空格的, 这个命令会报错, 用
-print0去除find打印的换行符:find . -type f -size +100M -print0 | xargs du -h
- 这样解决了换行符的问题, 但没解决 文件中有空格 的问题
find . -type f -size +100M -print0 | xargs -0 du -h
- 上面这行的作用是:
-print0告诉 find 打印的时候不要用换行符,xargs -0是告诉 xargs 要用 null 来做参数的切分, 不要用 空格 和 换行符- 所以文件名里有空格也可以正常打印
上面这行也可以这么完成:
find . -type f -size +100M -exec du -h {} '+'
问题
find /app -type l ! -exec test -e {} \; -print: 查找循环的 symbolic link
如何理解这段 find 的用法?
- 为什么要 -print, -print 一定要在最后吗
xargs
把 stdin 的输入转化为命令的 arguments, 一般结合 pipe 使用, 如:
echo "hello world" | xargs echofind . -name "*.log" | xargs rm
find . | xargs wc -l
find . | xargs wc -l 和 find . | wc -l 的区别是什么?
-
find . | wc -l- 先找出了当前 dir 里的所有文件, wc -l 再去数 find 的 stdout 有多少行
- wc -l 的参数是 find 的 stdout
-
find . | xargs wc -l- 找出 dir 里所有文件, 然后把每个文件都作为 wc -l 的参数传入
- wc -l 的参数是 dir 里的 每个文件
- wc 只执行了一次, 相当于:
wc -l . dir1 file1 dir2 file2
Note
find . -exec wc -l {} '+' 和 find . | xargs wc -l 的输出结果一样
-p
ask for permission before command execution
-0
xargs -0:
- 不使用 空格 或者 换行符 来切分参数
- 用 null 来切分参数
- 和 find 的
-print0配合使用
ln
A symlink (symbolic) is a type of file that points to other files or directories in Linux.
ln create links to a file or directory
ln -s creates a soft link (or a symbolic link).
- symbolic link (soft link) acts as a shortcut to a file or directory. → 就是个pointer
- 一个 hard link 就是个文件的 copy
创建的 symbolic link 可以直接被 rm 或 unlink
soft link (symbolic link)
创建 softlink: ln -s source_file symlink
softlink 创建之后, 相当于个 pointer, 指向 源文件
- 如果 源文件 被删除, symlink 不会自动被删除
- 比如:
touch test.txt; ln -s test.txt test2.txt; rm test.txt- 在这个场景, test2.txt 还存在
- 但是
cat test2.txt会报错test2.txt不存在, 而不是 test.txt 不存在
创建 softlink 的 source_file 甚至不需要存在, ln -s nonexistent_file symlink 不会报错
然后再重新 touch nonexistent_file 也是可以的
softlink 可以循环:
ln -s link1 link2; ln -s link2 link1


hard link
ln source_file hardlink
- 对 source_file 的修改,
cat hardlink也会体现 - 对 hardlink 的修改,
cat source_file也会体现 - 创建 hardlink 的时候, 如果 source_file 不存在, 会 报错
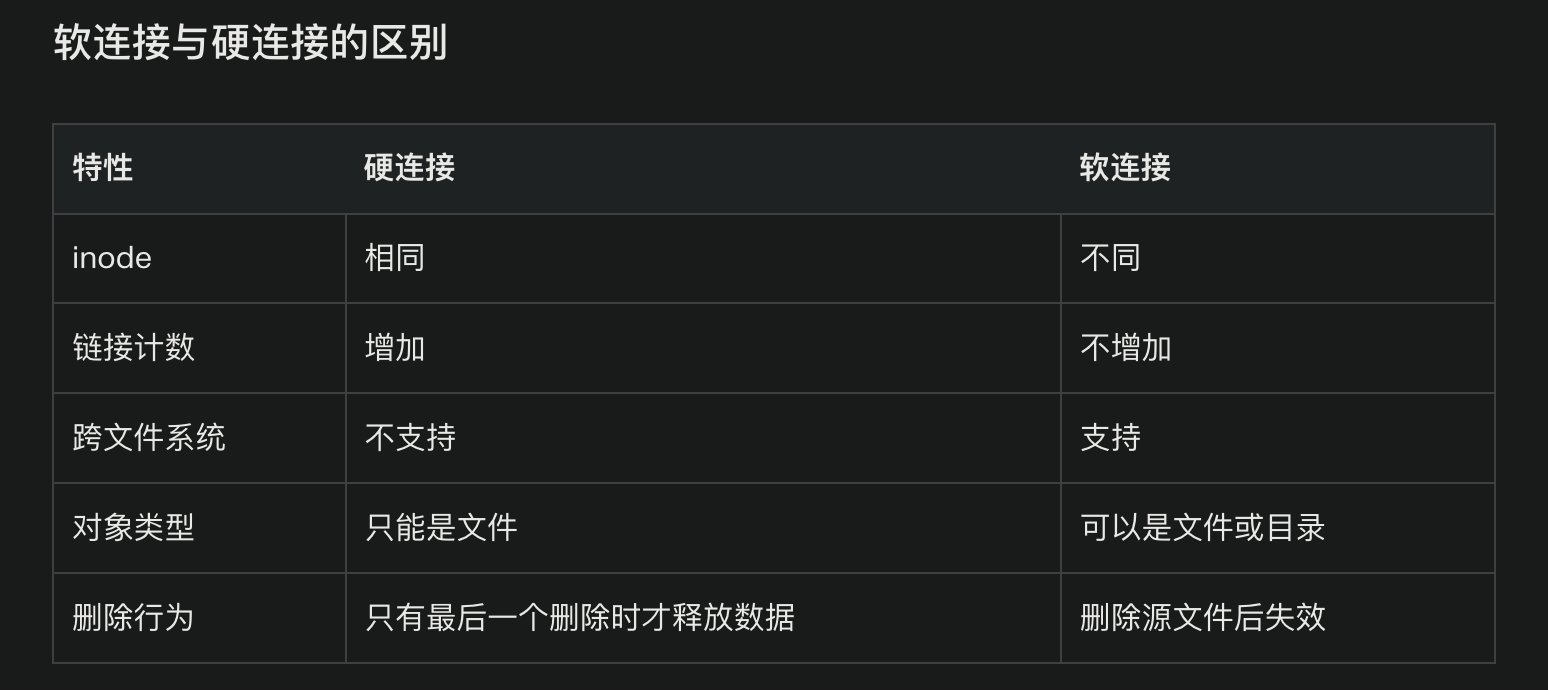
对比
- 软链接 储存源文件的 路径信息, 是指向一个源文件路径的 快捷方式
- 软链接 可以链接到 目录
- 硬链接 指向源文件的 实际数据, 硬链接和源文件共享 inode, 是同一个文件的不同 入口
- 硬链接实际上是 同一个文件的多个文件名
- 最后一个硬链接被删除的时候, 文件才会被删除
进程
ps
查看process: ps
返回:
- PID
- TTY: the terminal type you’re logged into (?)
- TIME: total amount of CPU usage (这个process使用的CPU时间的总和? )
- CMD: name of the command that launched the process
ps aux
- a: ps 只展示当前用户, a 展示所有用户
- u: 以用户为中心的进程信息 (面向用户的数据, 包括 cpu, mem 等信息)
- x: 显示不与用户终端交互的进程, 通常不展示 为什么 是 aux 不是 -aux??
- 从 claude 的解释上来看, 貌似只是 linux command 风格的问题
执行时:
h或?可以进入 help page
kill
→ ==虽然名字叫做 kill, 实际上是给进程发信号的, 啥信号都能发, 终止进程只是其中一种== kill PID 终止进程 kill -9 PID
crontab
配置定时任务
- crontab -e: edit
- crontab -l: list
- crontab -r: remove
crontab 配置里有 5个 *
- 分别代表 分钟、小时、日、月、星期 各种符号的意思:
*: 每个; 如 小时位置是 * 的话, 代表每个小时-: 范围; 小时位置是 0-10 代表 0 到 10 点/: step; 小时位置是 */5 代表每5个小时; 0-10/2 代表 0-10点的每2个小时,: 枚举;
磁盘\内存\cpu
free
- 打印出 内存使用情况 和 磁盘上 swap 区域 的使用情况, 注意是 物理内存, 不是 虚拟内存
- -h: human friendly
例子:
free -g -t -s 5: - -g: 以 Gb 为单位
- -t: 展示 内存 和 swap 的 total
- -s 5: 5秒为一个 interval 打印一次 输出:
total used free shared buff/cache available
Mem: 137Gi 103Gi 4.6Gi 2.5Gi 28Gi 30Gi
Swap: 0B 0B 0B
Total: 137Gi 103Gi 4.6Gi- used: 已经使用的
- free: 完全没被使用 的
- buff/cache: 被用作 缓冲 buffer 与 缓存 cache 的内存, 必要时可以被回收
- shared: 共享内存, 已经被使用了, 是算在 used 里的
Note
total = used + free + buff/cache
available ≠ free + buff/cache
- 因为 不是所有的 buff/cache 都能够立即被释放
- available = free + (buff/cache 中可快速回收的部分)
相关知识:
- 低 free 值 不是坏事, 不代表内存不够了, 关键是要看 available 的值
- free 是 完全空闲 的内存, 相反的, free 太高了说明很多内存都没用上, 反而是坏事
- 一个健康的系统, 应该 free 的值应该处于一个 比较低 的数字; 这样说明大部分内存都被拿来做 buff/cache 了
- available 的值处于 15~20% 是 good sign, 说明系统正在 performing optimally; 没有太多内存被浪费, 没有太大压力;
- available 的值太高了说明系统被 over-provisioned 了 (more resources are allocated than necessary)
- 如果 swap 的 used 很高 的话, 说明系统在频繁地进行 内存交换 (server is paging to a disk), 是内存不足的表现, 需要 investigate
du
- 打印出 dir 下 每个 dir 的 disk usage
du -flags path/to/dirflag 和用法:- -h: human friendly
- -k/m/g: 用 k/m/g 单位来打印
- -s: single dir, 只打印当前 dir, 不 recursive
- -a: 打印出 dir 下 每个文件 的 disk usage
- 本身 du 只会打印 dir 的 disk usage, 要加上
-a才会打印出这个 dir 下每个文件的 disk usage
- 本身 du 只会打印 dir 的 disk usage, 要加上
- -d 2: depth=2, 深度
- -c: accumulative, 最后打印一个 总和
du */*.log: 所有.log文件的 disk usage
Note
disk usage 磁盘占用和文件大小的差别:
- disk usage 一般比 file size 大,
- file size 是文件里存的数据的大小,
- disk usage 是这个文件在磁盘上占用的空间, 是磁盘上给这个文件 allocate 的空间大小.
实际使用:
du -h --max-depth=1 | sort -rh | head -n 10
- 按照 human readable 的 format 打印出 du, 深度=1
- reverse (从大到小) 排序, 按照 human numeric 的逻辑;
- 比如说 120K 和 20M, 如果直接 sort -r, 120 > 20, 120k 会在前面
- 有 -h 的话, 是按照 human numeric logic 来 sort, 20M > 120K
df
- disk free, 参见 free;
free是看内存和 swap, disk free 是看 disk - filesystem 的使用情况 和 挂载点
df path/to/file_or_dir: 展示这个 file 所在的 filesystem 的使用情况 flags 和 用法:df -h: human friendly, 以 Gb Mb 展示, 不以字节展示df -hT: 打印出 filesystem 的 type,ext4啥的就是实际的物理硬盘对应的 filesystem- -c: accumulative, 展示总数
为什么需要
df -i, 为什么要看 inode 的使用情况? - inode 可能会被耗尽, 如果小文件、log文件很多的话, inode 的消耗速度很快
df 的输出里可能有
tmpfs这一项, 这是什么, 有啥用? - temp filesystem, 基于 内存 的虚拟文件系统
tmpfs对应的是内存上的数据- 比如说, 系统运行的时候创建一个 tmpfs, 挂载到
/run上, 用来存储系统运行的临时数据 - df 的返回里可能有多个 tmpfs
其他:
- 有时 df 的输出和 du(磁盘使用分析)结果不一致,因为 df 基于文件系统元数据,而 du 基于目录实际占用的文件数据
- 返回的 overlay filesystem 是个啥
- 是 linux 中 重叠 filesystem 的概念, 有 可读的 lowerdir, 可写的 upperdir, 和临时存储的 workingdir
- 感觉好像是和 docker image 里分层 snapshot 一样的概念, 过后再学吧
实际使用

挂载点
挂载: 将一个文件系统 file system 附加到现有 目录树 的过程
/dev/sda1mounted on / 代表/dev/sda1挂载在 /- 意思是, 根目录 下的 文件 实际存在在 /dev/sda1 设备上
文件系统挂载点挂载点
- 文件系统是在 物理储存设备 和 用户 之间提供了一个 抽象层
- 用户只需要写到 file system 里, 不需要处理:
- 数据在磁盘上的具体物理位置
- 数据是如何被分割、储存
- 如何管理存储空间
- 一个物理存储设备可以被分区, 一个分区就对应一个 file system
- 一个 file system 也可以跨越多个物理设备 (多个硬盘)
- file system 也可能不对应物理设备, 如 网络文件系统
例子: 用户在文本编辑器里保存一个文件
- 文件系统 找到可用的存储空间
- 文件系统 分配存储空间给新文件
- 文件系统 创建元数据
- 文件系统 更新目录结构
lsblk
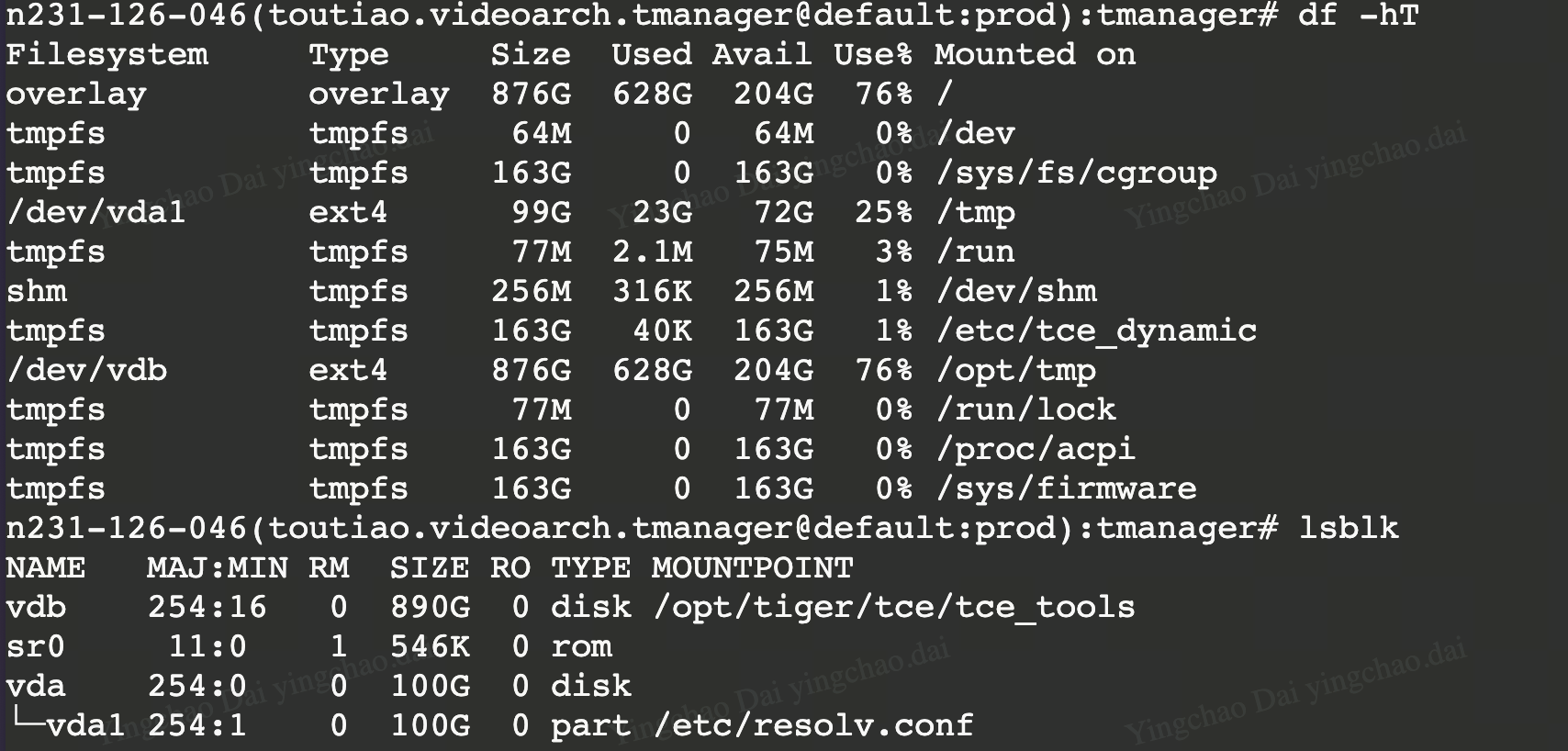 lsblk 展示 物理磁盘
可以看到 vdb 和 vda1 都在
lsblk 展示 物理磁盘
可以看到 vdb 和 vda1 都在 df -hT 的返回中有体现
这个也先不学了吧
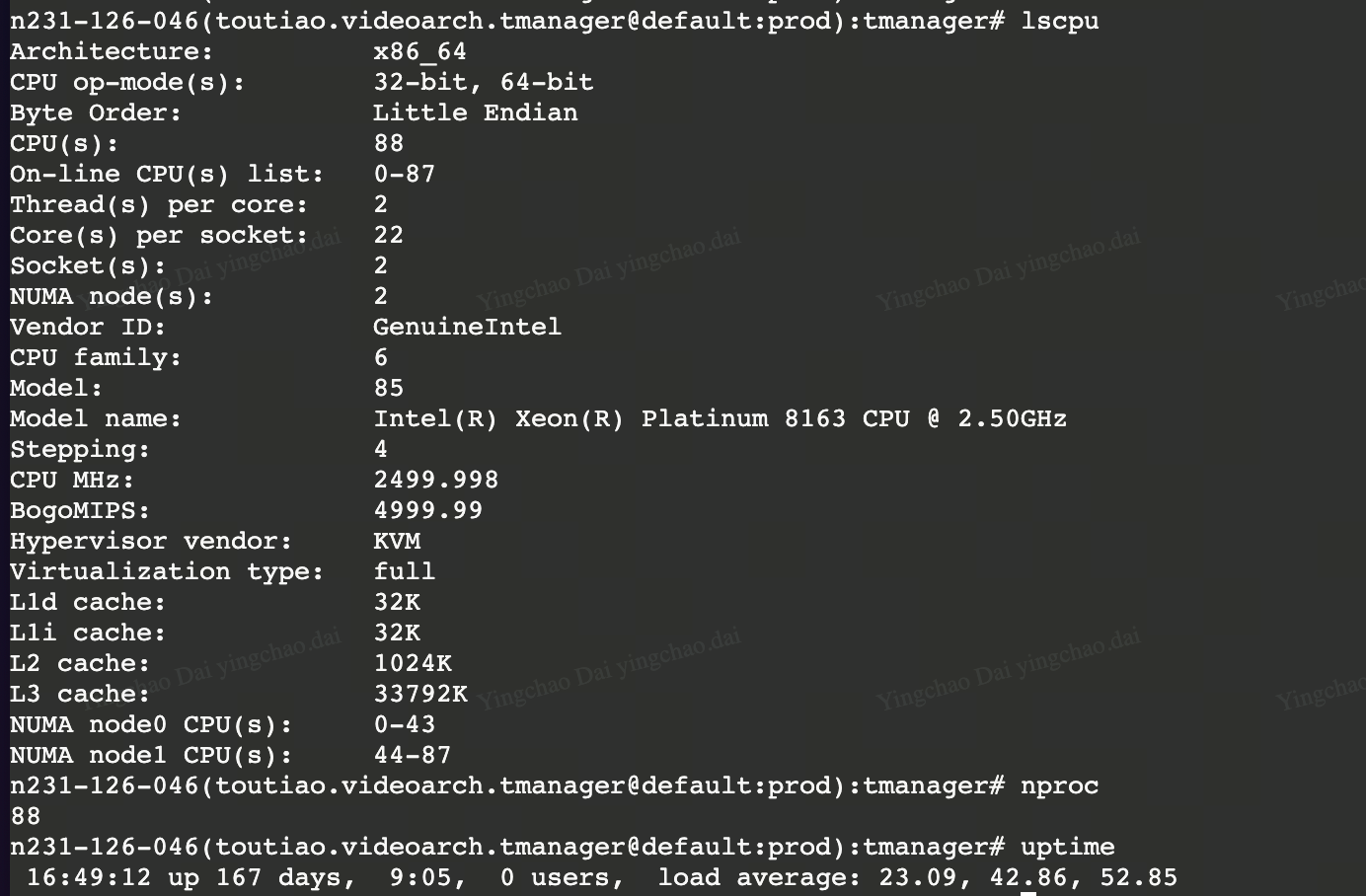
lscpu
查看 cpu 相关的信息, cpu 的数量啥的
系统、服务
systemd
什么是 systemd
- linux 中用于管理 系统 和 系统上运行的服务 的 工具
- 比如说: 电脑开机时, systemd 负责 启动操作系统 init
- 这里的 服务, 指的是 应用程序 (nginx啥的), 系统本身的程序 (网络啥的)
systemctl
systemctl 是 linux 中 systemd 这个工具的主要命令, 主要用于
- 启动、停止、重启、重新加载、查询 linux 机器上面跑的各种程序, 对应命令为
- start、stop、restart、reload、status
处理管理服务,
systemctl也可以管理操作系统本身: - 关机:
systemctl poweroff - 重启系统:
systemctl reboot - 挂起系统:
systemctl suspend - 休眠系统:
systemctl hibernate
journalctl
查看操作系统级别的日志, 比如说
- 服务启动的日志
- 操作系统本身执行的一些日志
journalctl -u service.name: - 用来查看和
service.name相关的日志journalctl --since today --until xxx: - 可以指定时间段来查看日志
uname
查看 linux 操作系统本身的信息, linux 版本啥的
uname -a, 返回如下:
Linux dp-3c4fb7d5cc-5fc86886cb-7jvbt 4.14.81.bm.30-amd64 #1 SMP Debian 4.14.81.bm.30 Thu May 6 03:23:40 UTC 2021 x86_64 GNU/Linux
uptime
没太多复杂的, 关注一下返回. 一般的返回如下:
0:41 up 2 days, 9:53, 2 users, load averages: 3.61 3.34 3.15
- 当前时间
- 已经 up 了多久
- 当前系统上登录的用户数
- load average 的那三个数字代表: 过去 1分钟, 5分钟, 15分钟内系统的平均负载
这 3.几 的数字是啥意思
- 只要数字小于 CPU 核数就是正常, 约接近说明负载越高
- 用
nproc可以查看当前的 cpu (核)数, numbers of processing units - 在我电脑上
nproc出来返回 10, 3.几还远远小于 10
怎么解读这个 average load
- 1分钟, 5分钟, 15分钟内, 系统 运行队列 长度(包括可运行和等待状态的进程)
- 也就是有多少个 进程 在 运行
- 负载数 < 核心数: 系统处于健康状态,CPU 有足够的能力处理当前任务
- 负载数 ≈ 核心数: 系统正在满负荷运行,所有核心都被任务占用
- 负载数 > 核心数: 系统超载,任务队列中有未分配 CPU 的任务,性能可能会下降。
dmesg
print kernel messages
netstat
iostat
networking related
ping
ping + 地址 ping 这个 cmd 在干嘛?
- 发 ICMP 的包给地址, 等待 echo
- 显示 roundtrip time 和 ttl 等信息
- 能够用来看连接是否正常、网络是否稳定、是否有丢包、网络抖动情况
ICMP:
- internet control message protocol
- 本身是个 基于 IP, 是在网络层, 还没有到传输层, 所有没有什么基于 UDP 还是 TCP
TTL:
- time to live, IP 包的一个字段
- “生存时间” 但是实际上和时间没有关系
- 实际上表示的是 数据包 在网络中 可以转发的最大跳数
- 每当数据包经过一个 路由器 (也就是数据包被 转发 一次), TTL就会减 1
- 不同操作系统有不同的 TTL 默认值
- 为什么要有 TTL:
- 控制数据包在网络中跳转的次数, 防止 数据包 在网络中 无限循环
- 比如说路由器配置错误, 导致路由环路, ttl 会逐渐减少, 到0之后就会被丢弃
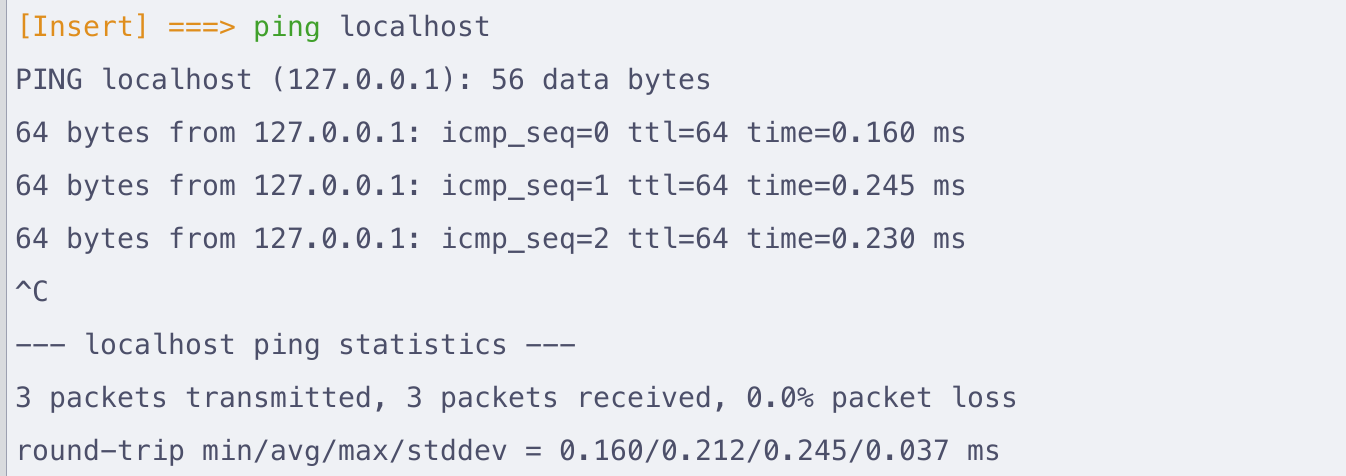
Note
没有网络的时候, 可以 ping 自己来看协议栈是否有问题:
ping 127.0.0.1orping localhost- ipv6 可以
ping ::1
dig \ nslookup
DNS lookup utility
ss -tuln 、 netstat
netstat: 用来看 network statistics, 在新的 linux 上可能都没有了, ss 是个新的更高效的工具 ss: 用来分析 socket 信息, 可以看端口的监听状态; 主要就是看 tcp、udp 的状态, 和 unix domain socket 的状态
ss flags:
man page
-l: listen, 状态为 listen 的 socket;-t、-u、-x: tcp socket, udp socket, unix domain socket-s: summary, 给出个 socket 的总结-n: numeric
查看一个端口是否有被监听:
ss -l | grep ":port_number"
ifconfig \ ip addr show
network interface configurator, 查看 NIC 相关的信息 返回:
lo: loopback address, 也就是 localhost, 用来代表当前这台计算机本身
nc
netcat, 功能本身是: 用来和 remote port (远端端口) 建立 tcp 或 udp 链接 flags:
-4、-6: ipv4 或 ipv6-z: zero I/O, 只是用来 scan, 没有 I/O-v: verbose-w: 设置 timeout 时长 使用方法:nc -zv 123.123.123.123 80: 检查 ip 123.123.123.123 的端口 80 是否开放nc -zv -w 5 google.com 80-100:- 扫描 google.com 的 端口 80 到 100, timeout 时长为 5s
traceroute
iptables
tcpdump
抓包工具
bash script
变量
$:
$?
$#
比较
-eq:
-ne:
-gt:
-ge:
-lt:
-le:



实际使用
https://www.mianshiya.com/bank/1812067560819048449
查看进程
- ps -p PID
- cat /proc/PID
- top -p PID
终止进程
查看内存
free -th
cat /proc/meminfo
cpu 占用最多的 10 个 进程
ps -eo pid,comm,%cpu --sort=-%cpu | head -n 11
磁盘占用最大的 10 个文件/dir
包含dir:
du -ah . | sort -rh | head -n 10不包含 dir, 仅文件find . -type f -exec du -h {} '+' | sort -rh | head
修改权限
配置 ip 地址
网络端口
磁盘空间不够了怎么办
# 删除特定目录中超过30天的文件
find /path/to/directory -type f -mtime +30 -exec rm -f {} \;