Direct Memory Access DMA
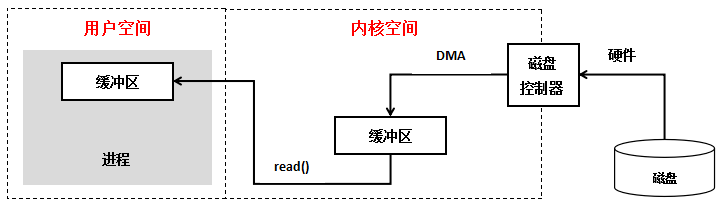
无 DMA
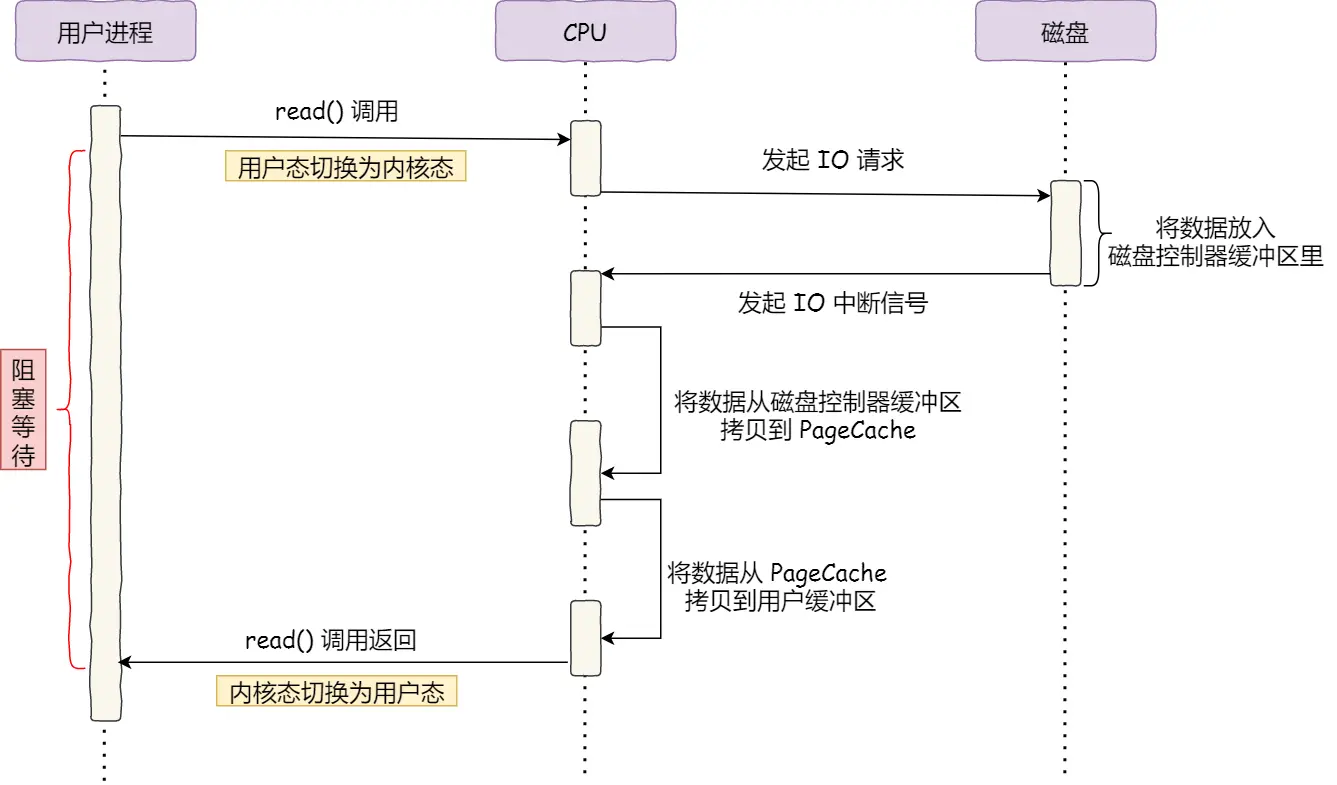 上图就是没有 DMA 的流程:
上图就是没有 DMA 的流程:
- 用户发起 syscall
- cpu 和磁盘驱动发起 io 请求
- 磁盘把数据搬到自己的 缓冲区, 发起 中断 通知 CPU
- CPU 把数据从磁盘驱动的 缓冲区 中搬到自己的 寄存器 上
- CPU 再把寄存器上的数据搬到 内存(内存上的用户缓冲区) 上 整个过程都需要 CPU 参与, CPU 干不了别的事情了
Note
direct memory access 指的是: 无需借助 CPU, CPU 无需参与!
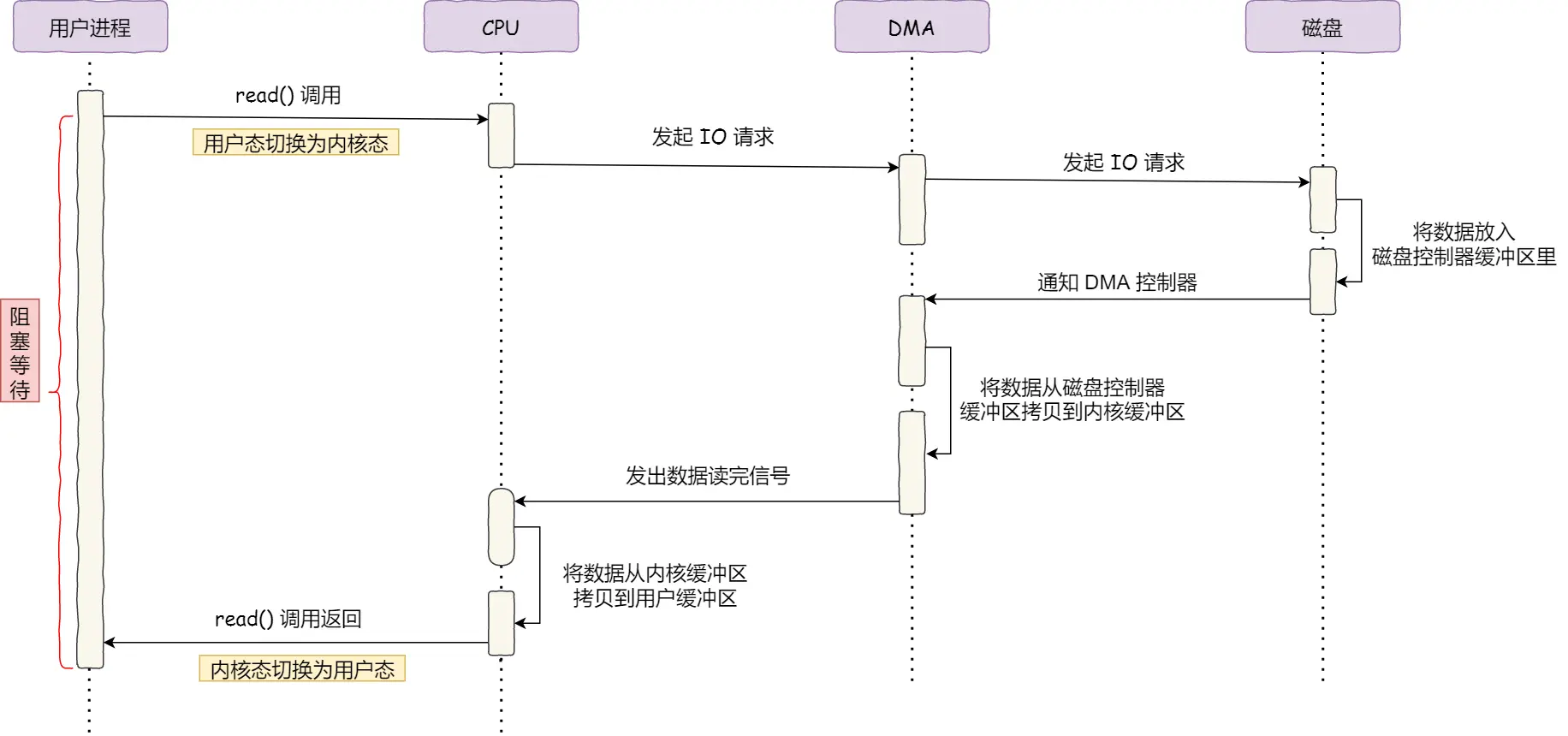
DMA
DMA 是指把数据从 磁盘 搬运到 内存 的工作都交给 DMA 控制器了, 流程如下:
- CPU 直接和 DMA 交互
- DMA 能直接访问内存, 在磁盘把数据搬到 磁盘缓冲区 之后, DMA 能直接把数据搬到 内核缓冲区; 这个过程是不占用 CPU 的
- DMA 再发 中断 给内核
- 还是需要 CPU 把数据从 内核 拷贝到 用户
在 shell 里执行 /hello 这个可执行文件
source - CSAPP
- 键盘输入
/hello的时候, CPU 会把这些字符都搬到 memory 里 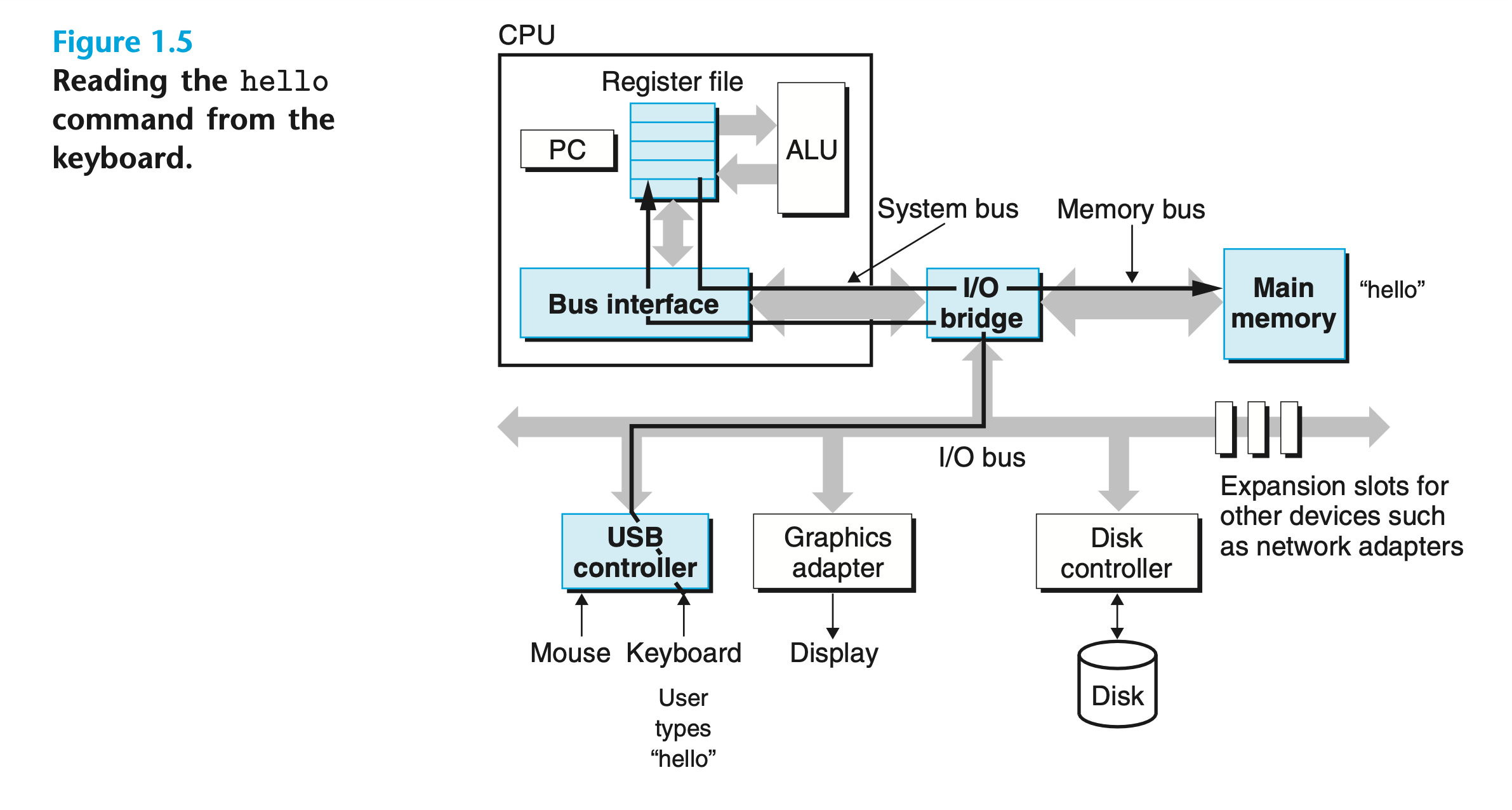
- 输入 回车 的时候, shell 作为一个程序, 能判断到输入完毕
- 然后通过 DMA, 已经编译好的可执行文件 hello (原本存储在 disk 上) 会被搬到 memory 里
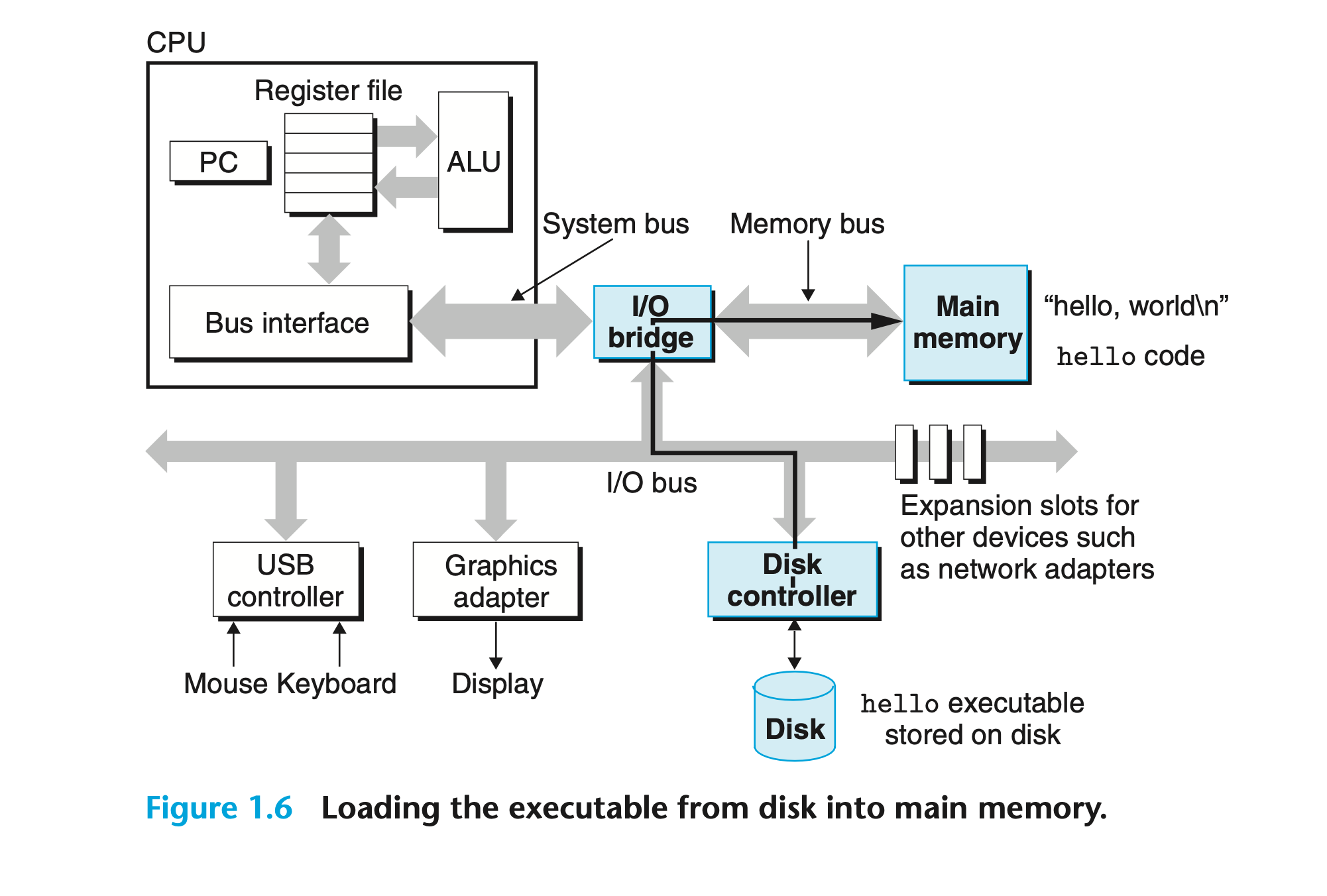
- CPU 再从 memory 里读 instruction, 执行 instruction
- 执行结果是存储在 memory 上的, 所以还是需要 CPU 把数据搬到 I/O (display device)
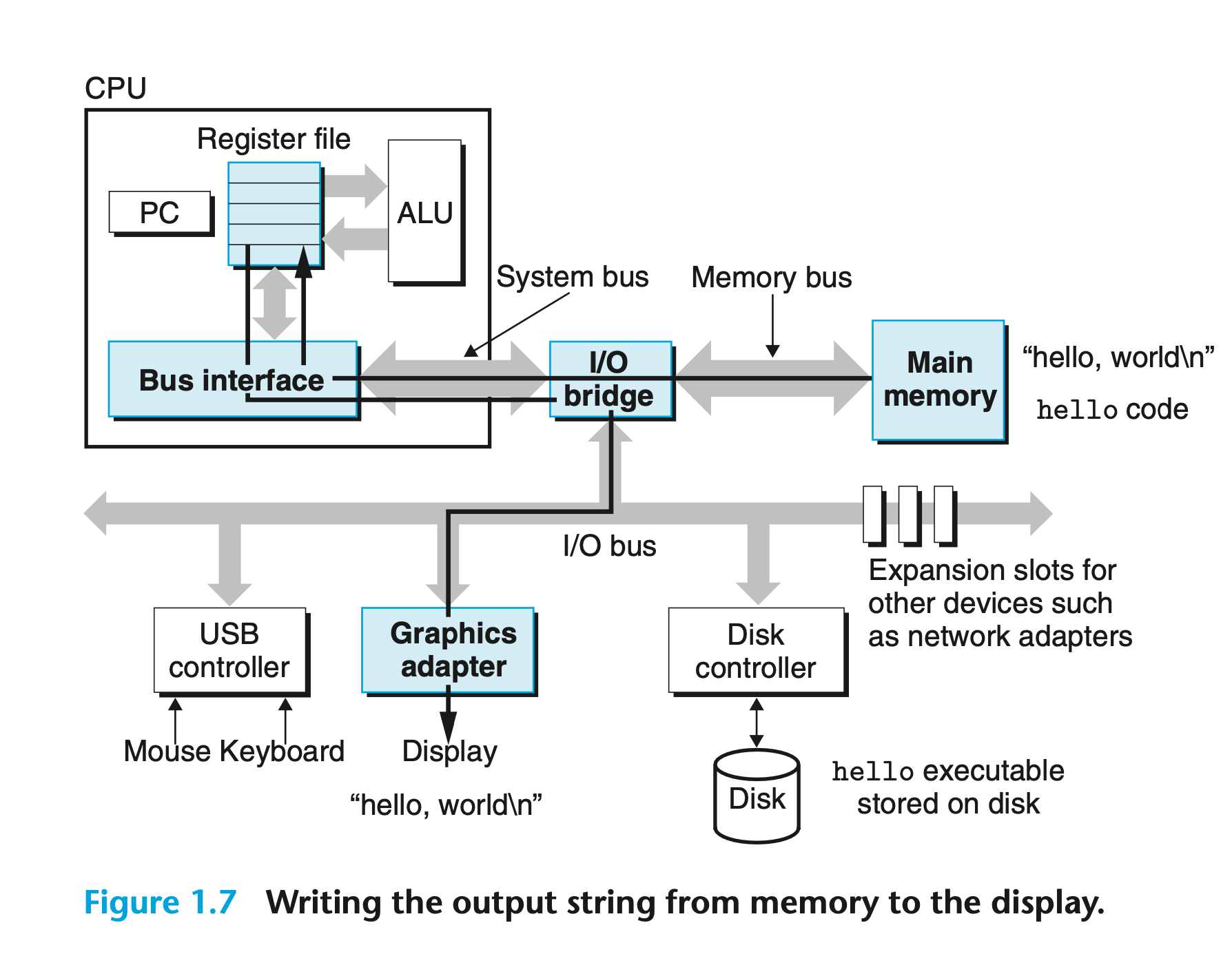
A important lesson from this simple example is that a system spends a lot of time moving information from one place to another. → 确实是, 这 CPU 就一直在搬运数据
cached memory
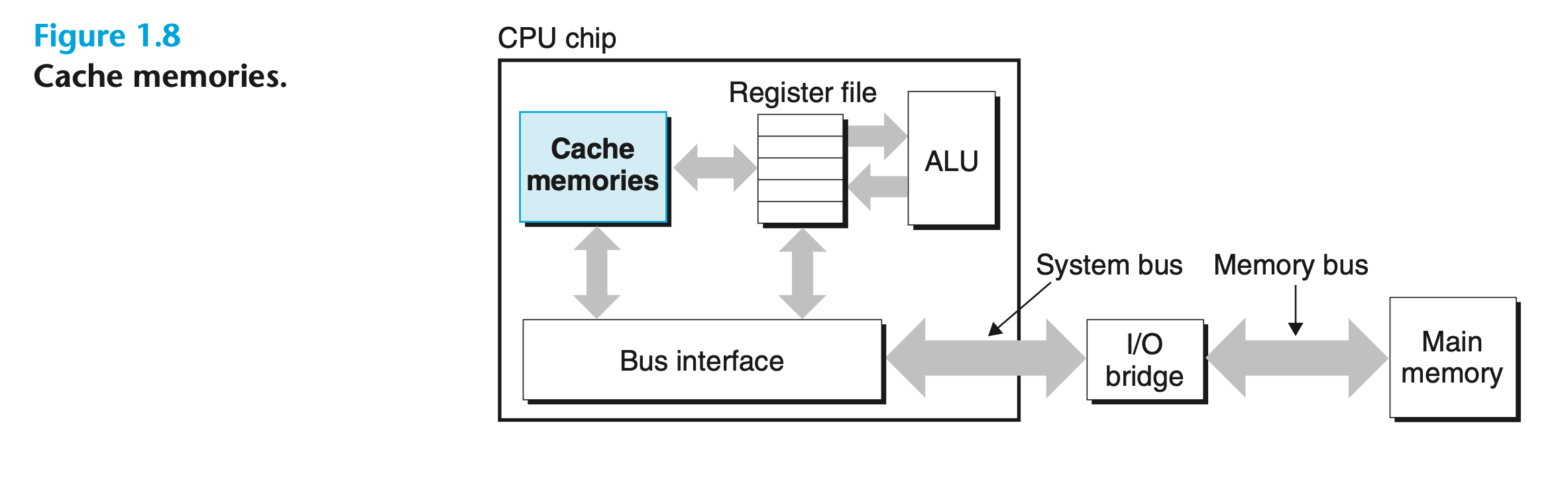
- 这里说的 cache 是 CPU 上的一个 component
- CPU 上的 cache 也叫做 static random access memory
- wikipedia
Note
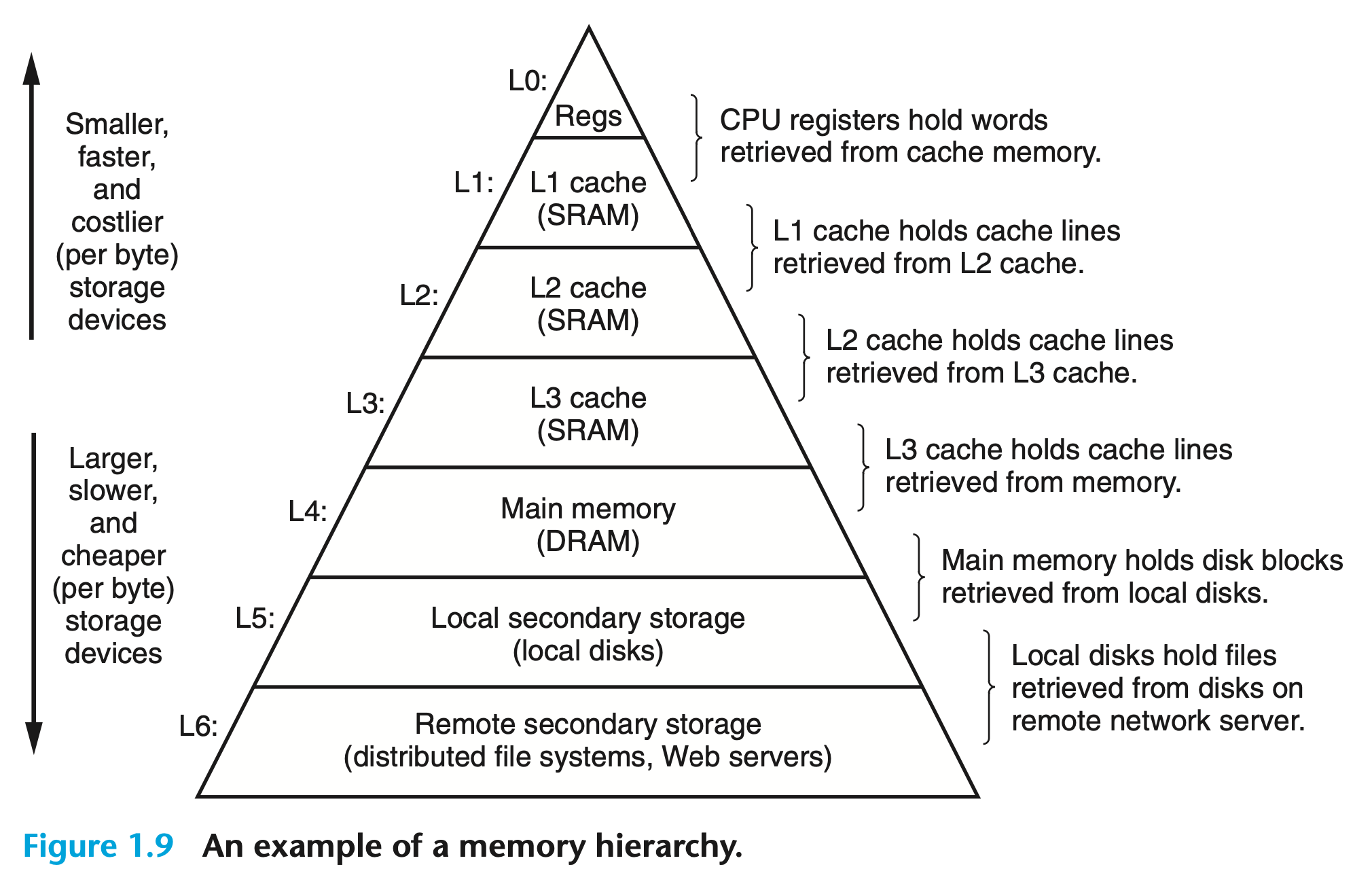
“The main idea of a memory hierarchy is that storage at one level serves as a cache for storage at the next lower level. Thus, the register file is a cache for the L1 cache. Caches L1 and L2 are caches for L2 and L3, respectively. The L3 cache is a cache for the main memory, which is a cache for the disk. On some networked systems with distributed file systems, the local disk serves as a cache for data stored on the disks of other systems.” → CSAPP
I/O 过程
 调用
调用 read(), write() 的时候发生了啥:
- 磁盘 → 内核 → 用户
- 用户 → 内核 → 磁盘
- 以上的过程发生了 2次 syscall, 4次 用户态和内核态的切换, 数据也被拷贝了 4次
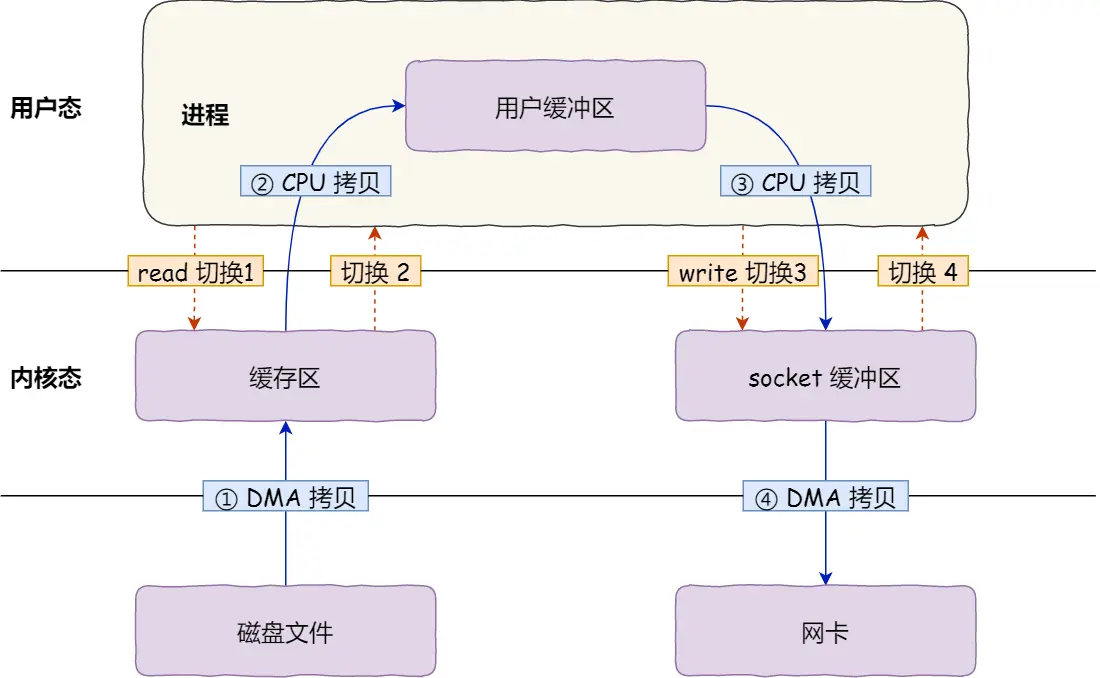
Note
打开一个 FD 有两个过程:
- 内核准备数据;
- 数据从内核空间拷贝到用户空间
减少拷贝次数
- 在调用
read()的时候, 数据会被从内核空间拷贝到用户空间 - 实际上没有必要拷贝到用户空间, 数据留在内核空间, 通过
mmap()让用户能够访问得到就行了 (用户可读可写) - 等到用户调用
write()的时候, 数据再被拷贝到 socket 缓冲区就可以了 → 减少了一次拷贝的次数, 但是还是需要 3次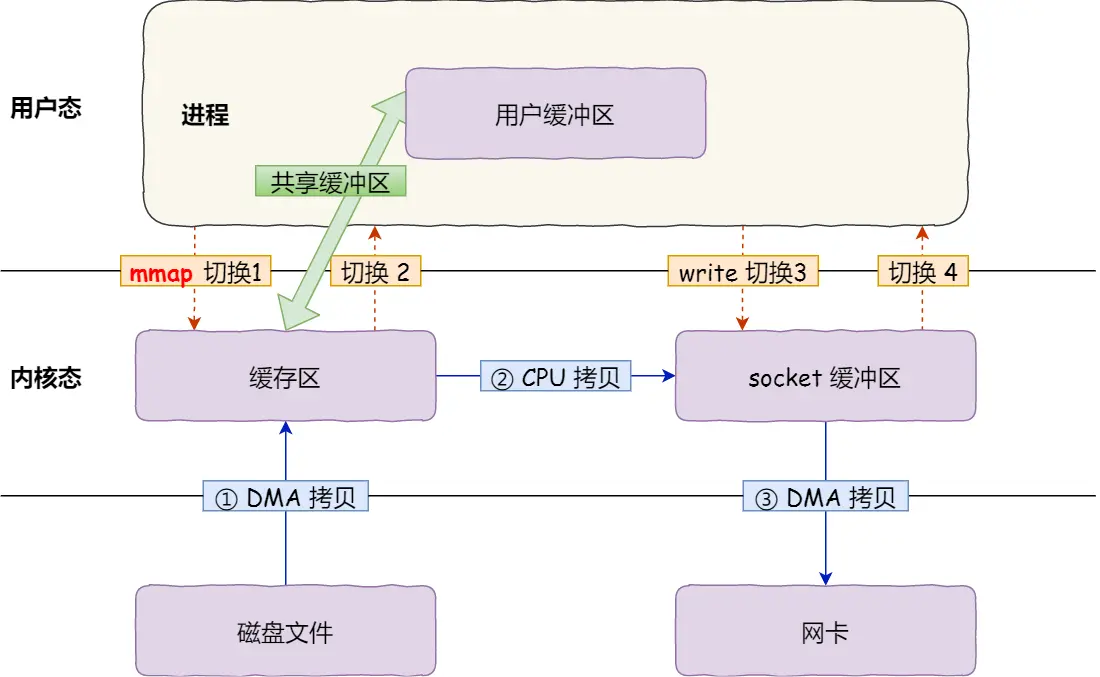
零拷贝 (tbc)
I/O 阻塞
是个啥, 为啥会阻塞
- 数据传输要时间, 进程发起 syscall 请求读取、写入数据的时候, 就需要等
- 所以其实没有 非阻塞 I/O, 常说的 非阻塞 I/O 是在感官上 看起来 没被阻塞
- 像是 cpu 执行一样, 看起来 好像是 CPU 同时在执行好多任务, 但是实际上不是 parallel
- 阻塞等待的是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程
- 下图是没有 DMA 的场景 source
linux 的 5种 I/O 模型
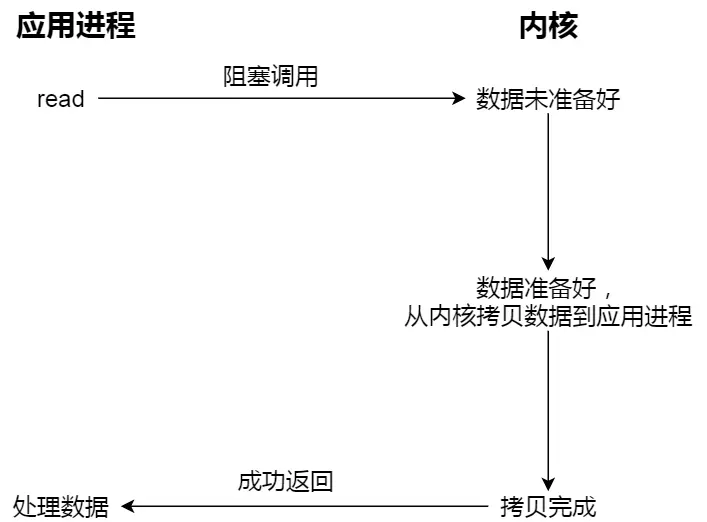
阻塞 I/O
- 一个进程里, 打开 socket, 监听某个端口
- 端口没有数据进来的时候就阻塞住, 等待数据, 啥也干不了
- 数据收到了之后才会继续
非阻塞型 I/O (polling)
- 用户进程调用 syscall 之后, 没数据的话, 内核会直接返回个错误码
- 收到错误码, 用户进程就可以继续执行了, 进程不会被阻塞
- 但是用户进程还需要不断地 主动 调用 syscall 来看 I/O 是否完成了 (polling)
下面这段代码就是不断地在调用
recv(), 一秒调用一次:
import socket
# 创建一个 socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(('example.com', 80))
# 发送一个请求
s.send(b'GET / HTTP/1.1\r\nHost: example.com\r\n\r\n')
# 轮询检查是否有数据可读
while True:
try:
data = s.recv(1024)
if data:
print("Received:", data)
break
except BlockingIOError:
# 数据不可用,继续轮询; 轮询周期为 1
time.sleep(1)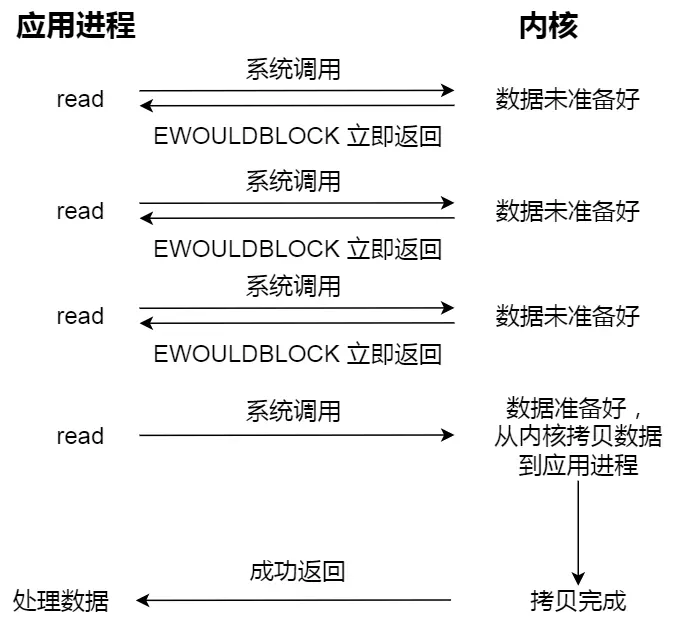
注意:
- 上图的不断调用
read(), 是在轮询查看数据是否在 内核 准备好了 - 最后一次调用
read()之后, 还要等到 数据从内核空间拷贝到用户空间 - 正是因为这样, 这个 非阻塞 I/O 也是个 同步 I/O
因为在 read 调用时,内核将数据从内核空间拷贝到用户空间的过程都是需要等待的,也就是说这个过程是同步的 - 小林
异步 I/O
异步 I/O 是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程都不用等待 - 小林
- 异步 I/O 最主要的点是 只有一次 syscall
- 进程并不需要主动发起拷贝动作
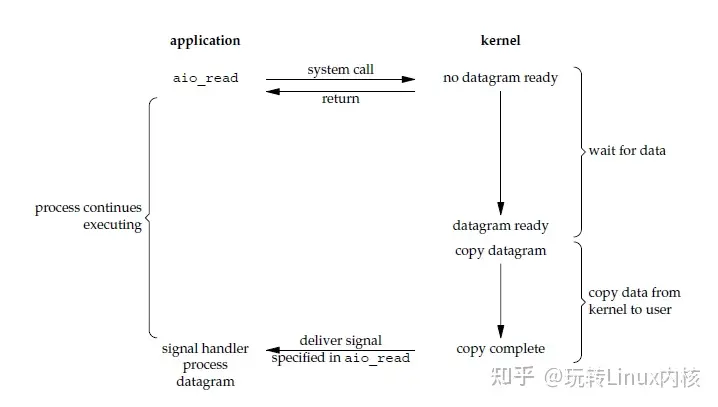
信号驱动型 I/O
- 进程发起 I/O 的 syscall 之后, 就继续执行
- 进程通过系统调用向内核注册一个 信号处理程序 signal handler
- 硬件上的 I/O 完成的时候 (数据就绪的时候), 数据就在 内核空间 里了; 这时候内核给进程发信号, 告诉进程 I/O 完成了, 进程还需要调用一次 syscall 来把数据搬到 用户空间 里
- 进程的 signal handler 来处理信号, 获取数据
这面这张图和上面 polling 对比, 就是通过 内核给进程发信号 来省略了 进程主动轮询 syscall 的过程
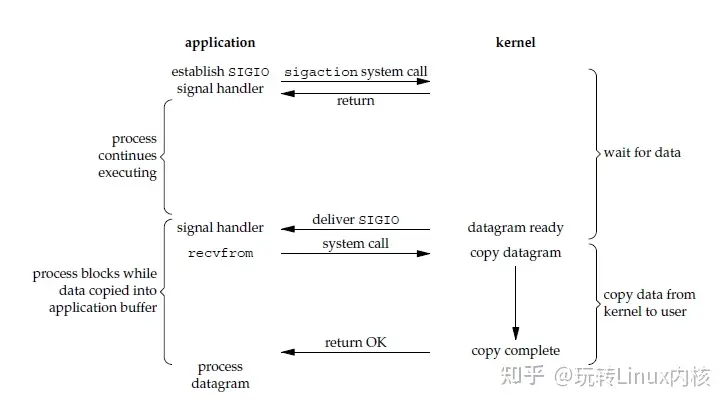
[!我的理解] 信号驱动 I/O 和异步 I/O 的共同点是: 都不会被阻塞, 都在等通知;
不同点是:
- 信号驱动 I/O 在等的是 就绪的 I/O 事件, 这个信号告诉进程, 可以开始 I/O 了;
- 异步 I/O 在等的是 已完成的 I/O 事件, 数据已经被拷贝到用户空间了
I/O 多路复用 (事件驱动 I/O)
啥叫 I/O 多路复用?
- 单个线程 同时监听 多个文件描述符, 任意一个 I/O 完成之后进程就能继续
- 任意一个 文件描述符 可以进行 I/O 的时候, 内核就会通知进程
- 不需要 多线程或多进程 就可以提高 并发能力
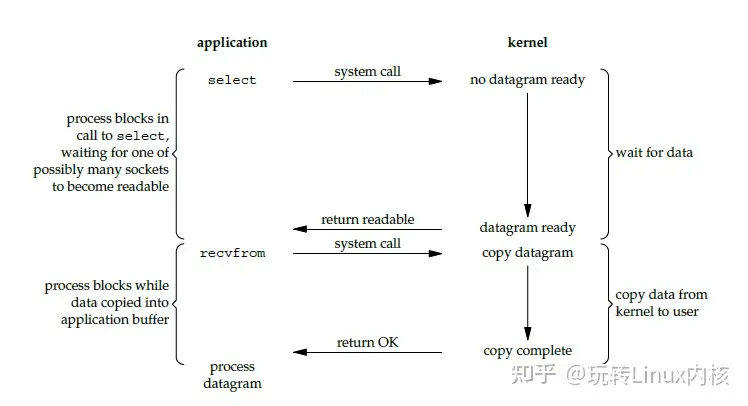
为啥需要 I/O 多路复用?
- 在网络连接数量非常大的时候, 连接和进程的数量就不能是 1:1 了; 不然 CPU 就一直在上下文切换了, 效率很低
- C10K 问题, 如果进程随着 client 数量增多, 那内存会是瓶颈, 连 FD 都会被用完
多路复用的实现
select/poll
- 一个进程用多个 socket 和多个客户端建立连接
- 这些 socket 的文件描述符被放在一个 文件描述符集合 里
- 用户态的进程把这个 文件描述符集合 拷贝到 内核
- 内核会 遍历 这些文件描述符, 把完成 I/O 的 socket 标记为 可 I/O
- 内核再把更新后的 文件描述符集合 拷贝到 用户
- 用户进程再 遍历 一次这个集合, 对 可 I/O 的文件描述符进行处理 → 两次拷贝和两次遍历, 效率低
poll 和 select 本质上没有差别:
- select 用的是 BitsMap 这个 数据结构 来表示 文件描述符集合
- poll 用的是 动态数组
- 都需要遍历这个集合, 所以 time complexity 是 O(n); 随着进程的数量线性增长
Note
这里的 poll 和上面的 非阻塞型 I/O polling 不是一回事;
这里是在一组 文件描述符 中轮询, 查看哪个是完成 I/O 的;
上面的 polling 是触发 I/O 之后, 不断地调用 syscall 查看 I/O 是否完成.
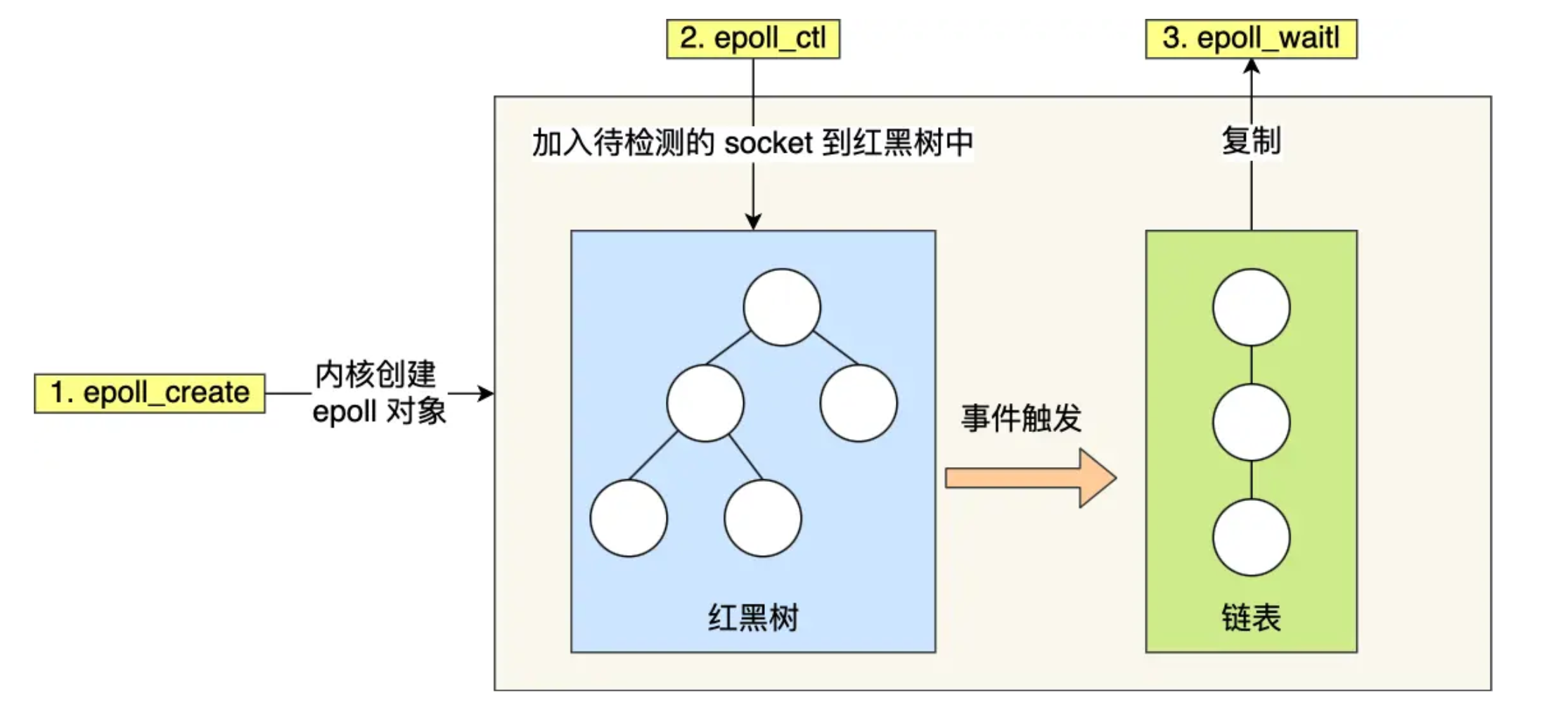
epoll
- epoll 用 红黑树 来储存 文件描述符集合
- 红黑树的 time complexity 是 O(logn), 解决了 select/poll 遍历效率低的问题
- 并且用户和内核之间不需要全量拷贝 文件描述符集合 了
- 内核会自己维护一个红黑树, 用户每次只传入一个 socket 就够了
- epoll 使用 事件驱动 的机制
- 内核里维护了个 linked list, 相当于个 就绪事件列表
- socket 有事件的时候就会被添加到这个列表里
- 不是像 select/poll 那样去遍历所有 socket 了, 只需要处理有事件的 socket 就行
对比
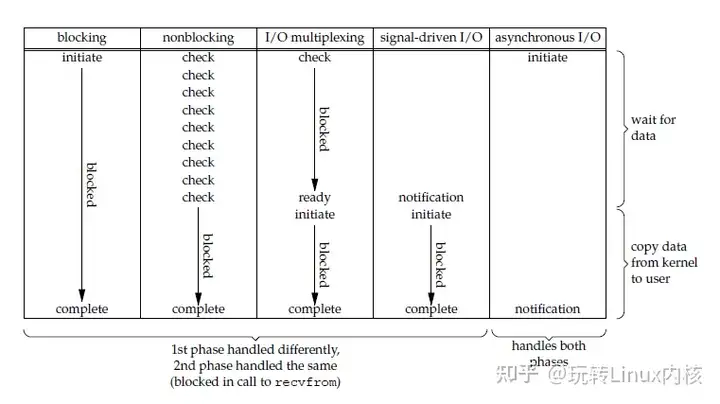
- 前四种 I/O 模型都是 同步 I/O: 都有 blocked 的时候, 这个阻塞是 数据从 内核空间 搬到 用户空间 导致的
- 异步 I/O 不会引起阻塞
web server 的 I/O
多进程模型
- 服务器要支持同时和多个客户端建立连接的话, 就要为每个客户端分配一个进程来处理这个客户端的请求
- 每个连接对应一个进程, 等待 I/O 的时候就会阻塞
工作原理:
- 主进程负责监听端口, 建立连接
- 连接建立之后, 主进程 fork() 创建子进程, 把 socket 的文件描述符给复制到子进程里
- 子进程直接用这个 socket 的文件描述符进行 I/O 就可以了 → 主进程负责监听、建立连接; 子进程负责处理请求 → 多进程模式, C10K 的时候就崩了; 资源不够, 上下文切换的开销太大, 操作系统要维护 10K 个进程也扛不住
多线程模型
- 利用 线程池
- 线程池: 先创建一批线程, 这批线程被不断地复用, 避免了频繁创建、销毁线程带来的开销
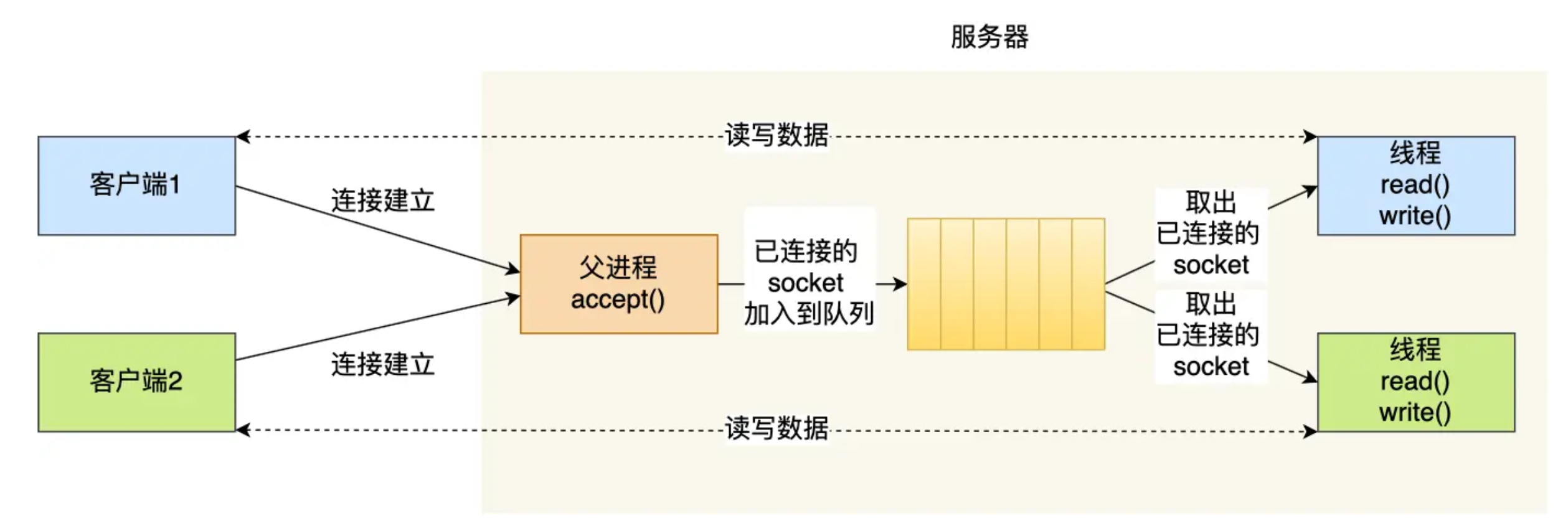
- 同样地会有上面 C10K 的问题 (为什么? 线程的数量不是固定的吗)
不同 I/O 代码对比
单进程传统 I/O:
- 传统 I/O 的
accept()和recv()会阻塞线程
import socket
def traditional_io_server():
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.bind(('localhost', 8888))
server_socket.listen(1) # 连接队列的最大长度是 1
print("等待客户端连接...")
client_socket, address = server_socket.accept() # 阻塞直到有连接
while True:
data = client_socket.recv(1024) # 阻塞直到接收到数据
if not data:
break
print(f"收到数据: {data.decode()}")
client_socket.send(data.upper()) # 发送响应多进程传统 I/O:
- 主进程监听端口
- 端口有数据, 就创建子进程来处理
- 主进程的工作就是监听端口和创建子进程
- 这样的话子进程之间就不会相互阻塞
import multiprocessing
import socket
import time
def handle_client(client_socket):
"""处理单个客户端连接的进程"""
try:
while True:
data = client_socket.recv(1024)
if not data:
break
print(f"进程 {multiprocessing.current_process().name} 收到数据: {data.decode()}")
client_socket.send(data.upper())
except Exception as e:
print(f"连接错误: {e}")
finally:
client_socket.close()
def multi_process_server():
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.bind(('localhost', 8888))
server_socket.listen(5) # 连接队列的最大长度是 5
print("多进程服务器启动...")
while True:
client_socket, address = server_socket.accept()
print(f"新连接:{address}")
# 为每个新连接创建一个独立的进程
process = multiprocessing.Process(target=handle_client, args=(client_socket,))
process.start()
# 注意:这里不会关闭 client_socket,由子进程负责关闭多路复用 I/O:
- 多路复用 I/O 使用
select()可以同时监听多个连接 - 多路复用模式下,单个线程可以处理多个客户端连接
import select
import socket
def multipath_io_server():
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.bind(('localhost', 8888))
server_socket.listen(5) # 连接队列的最大长度是 5
server_socket.setblocking(False) # 设置为非阻塞模式
inputs = [server_socket]
while inputs:
# select 监听多个文件描述符
readable, _, _ = select.select(inputs, [], [])
for s in readable:
if s is server_socket:
# 新连接
client_socket, address = s.accept()
client_socket.setblocking(False)
inputs.append(client_socket)
else:
# 处理客户端数据
try:
data = s.recv(1024)
if data:
print(f"收到数据: {data.decode()}")
s.send(data.upper())
else:
inputs.remove(s)
s.close()
except:
inputs.remove(s)
s.close()